

Apache HAWQ 介绍
HAWQ 是一个Hadoop原生大规模并行SQL分析引擎,针对的是分析性应用。和其他关系型数据库类似,接受SQL,返回结果集。
Apache HAWQ 具有大规模并行处理很多传统数据库以及其他数据库没有的特性及功能。主要如下:
-
对标准的完善支持:ANSI SQL标准,OLAP扩展,标准JDBC/ODBC支持,比其他Hadoop SQL引擎都要完善。
-
具有MPP(大规模并行处理系统)的性能,比其他Hadoop里面的SQL引擎快数倍。
-
具有非常成熟的并行优化器。优化器是并行SQL引擎的重要组成部分,对性能影响很多,尤其是对复杂查询。
-
支持ACID事务特性:这是很多现有基于Hadoop的SQL引擎做不到的,对保证数据一致性很重要。
-
动态数据流引擎:基于UDP的高速互联网络。
-
弹性执行引擎:可以根据查询大小来决定执行查询使用的节点及Segment个数。
-
支持多种分区方法及多级分区:比如List分区和Range分区。分区表对性能有很大帮助,比如你只想访问最近一个月的数据,查询只需要扫描最近一个月数据所在分区。
-
支持多种压缩方法:snappy,gzip,quicklz,RLE等。
-
多种UDF(用户自定义函数)语言支持:java, python, c/c++, perl, R等。
-
动态扩容:动态按需扩容,按照存储大小或者计算需求,秒级添加节点。
-
多级资源或负载管理:和外部资源管理器YARN集成;可以管理CPU,Memory资源等;支持多级资源队列;方便的DDL管理接口。
-
支持访问任何HDFS及其他系统的数据:各种HDFS格式(文本,SequenceFile,Avro,Parquet等等)以及其他外部系统(HBase等),并且用户自己可以开发插件来访问新的数据源。
-
原生的机器学习数据挖掘库MADLib支持:易于使用及高性能。
-
与Hadoop系统无缝集成:存储、资源、安装部署(Ambari)、数据格式、访问等。
-
完善的安全及权限管理:kerberos;数据库,表等各个级别的授权管理。
-
支持多种第三方工具:比如Tableau,SAS,较新的Apache Zeppelin等。
-
支持对HDFS和YARN的快速访问库:libhdfs3和libyarn(其他项目也可以使用)。
-
支持在本地、虚拟化环境或者在云端部署。
HAWQ 是原生 Hadoop SQL 引擎中“原生”的意思,“原生”主要体现在如下几个方面:
-
数据都存储在HDFS上,不需要使用connector模式。
-
高可扩展性:和其他Hadoop组件一样,高可扩展。并且具有高性能。
-
原生的代码存取:和其他Hadoop项目一样。HAWQ是Apache项目。用户可以自由的下载,使用和做贡献。区别与其他的伪开源软件。
-
透明性:用Apache的方式开发软件。所有功能的开发及讨论都是公开的。用户可以自由参与。
-
原生的管理:可以通过Ambari部署、资源可以从YARN分配,与其它Hadoop组件可以运行在同一个集群。
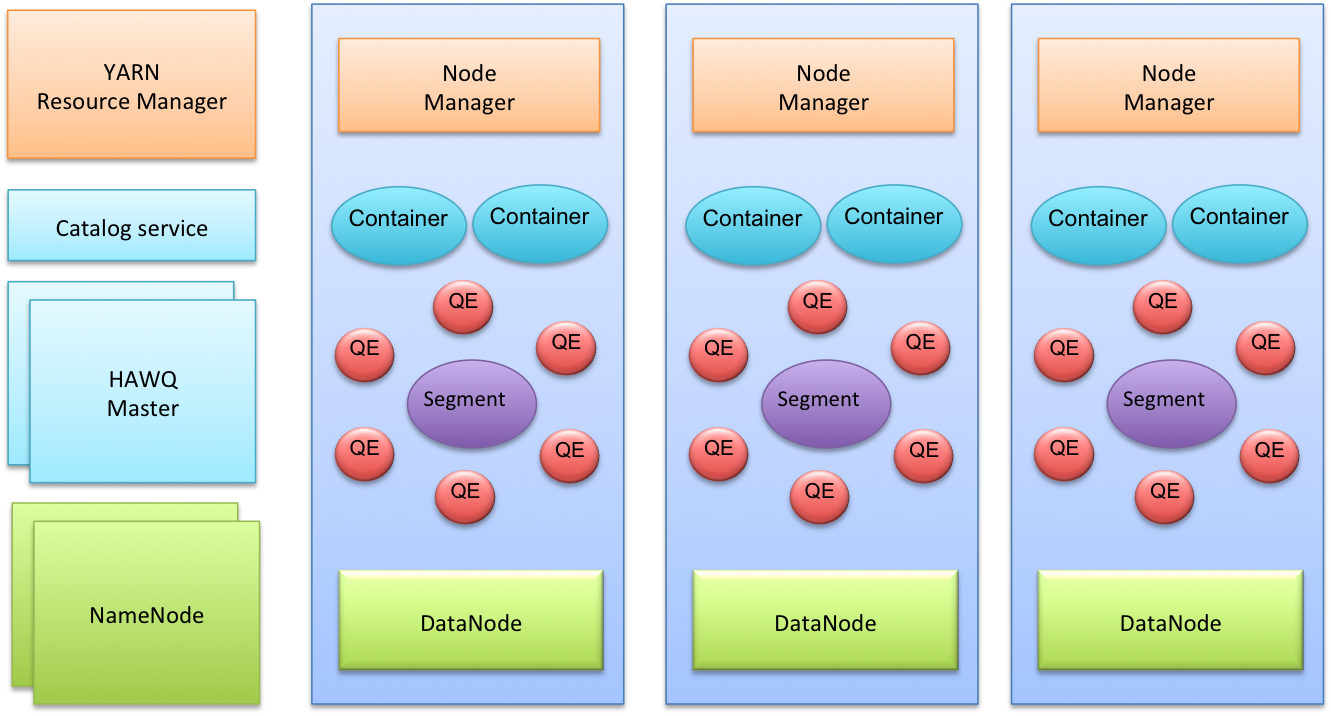
下图是一个典型的HAWQ集群的主要组件。其中有几个Master节点:包括HAWQ master节点,HDFS master节点NameNode,YARN
master节点ResourceManager。现在HAWQ元数据服务在HAWQ
master节点里面,将来的版本会成为单独的服务。其他节点为Slave节点。每个Slave节点上部署有HDFS DataNode,YARN
NodeManager以及一个HAWQ Segment。HAWQ Segment在执行查询的时候会启动多个QE (Query Executor,
查询执行器)。查询执行器运行在资源容器里面。
软件内部架构:

可以看到在HAWQ
master节点内部有如下几个重要组件:查询解析器(Parser/Analyzer),优化器,资源管理器,资源代理,HDFS元数据缓存,容错服务,查询派遣器,元数据服务。在Slave节点上安装有一个物理Segment,在查询执行时,针对一个查询,弹性执行引擎会启动多个虚拟Segment同时执行查询,节点间数据交换通过Interconnect(高速互联网络)进行。如果一个查询启动了1000个虚拟Segment,意思是这个查询被均匀的分成了1000份任务,这些任务会并行执行。所以说虚拟Segment数其实表明了查询的并行度。查询的并行度是由弹性执行引擎根据查询大小以及当前资源使用情况动态确定的。下面我逐个来解释这些组件的作用以及它们之间的关系:
-
查询解析器:负责解析查询,并检查语法及语义。最终生成查询树传递给优化器。
-
优化器:负责接受查询树,生成查询计划。针对一个查询,可能有数亿个可能的等价的查询计划,但执行性能差别很大。优化器的作用是找出优化的查询计划。
-
资源管理器:资源管理器通过资源代理向全局资源管理器(比如YARN)动态申请资源。并缓存资源。在不需要的时候返回资源。我们缓存资源的主要原因是减少HAWQ与全局资源管理器之间的交互代价。HAWQ支持毫秒级查询。如果每一个小的查询都去向资源管理器申请资源,这样的话,性能会受到影响。资源管理器同时需要保证查询不使用超过分配给该查询的资源,否则查询之间会相互影响,可能导致系统整体不可用。
-
HDFS元数据缓存:用于HAWQ确定哪些Segment扫描表的哪些部分。HAWQ是把计算派遣到数据所在的地方。所以我们需要匹配计算和数据的局部性。这些需要HDFS块的位置信息。位置信息存储在HDFS NameNode上。每个查询都访问HDFS NameNode会造成NameNode的瓶颈。所以我们在HAWQ Master节点上建立了HDFS元数据缓存。
-
容错服务:负责检测哪些节点可用,哪些节点不可用。不可用的机器会被排除出资源池。
-
查询派遣器:优化器优化完查询以后,查询派遣器派遣计划到各个节点上执行,并协调查询执行的整个过程。查询派遣器是整个并行系统的粘合剂。
-
元数据服务:负责存储HAWQ的各种元数据,包括数据库和表信息,以及访问权限信息等。另外,元数据服务也是实现分布式事务的关键。
-
高速互联网络:负责在节点之间传输数据。软件实现,基于UDP。
查询的主要流程:
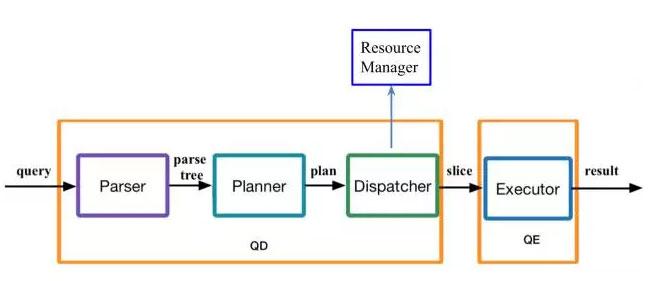
用户通过JDBC/ODBC提交查询之后,查询解析器得到查询树,然后优化器根据查询树生成查询计划,派遣器和资源管理器打交道得到资源,分解查询计划,然后派遣计划到Segment的执行器上面执行。最终结果会传回给用户。
并行查询计划示例:
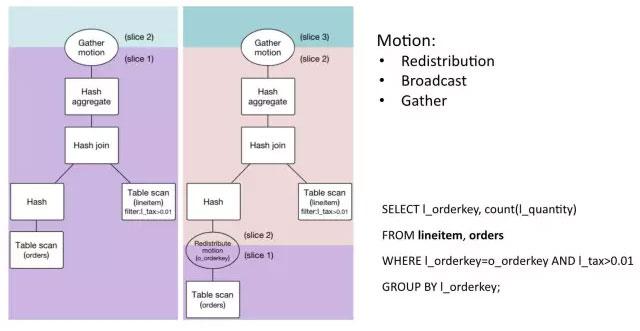
这个查询包含一个连接,一个表达式和一个聚集。图中有两个查询计划。简单来看,并行查询计划和串行查询计划最不同的是多了一些Motion操作符。Motion负责在节点之间交换数据。底层是通过高速互联网络实现的。我们可以看到这里有三种Motion:
-
Redistribution Motion: 负责按照hash键值重新分布数据
-
Broadcast Motion: 负责广播数据
-
Gather Motion: 负责搜集数据到一起。
左边的查询计划表示了如果表lineitem和orders都使用了连接键进行分布的情况。在这个例子中,lineitem按照l_orderkey进行hash分布,orders表按照o_orderkey进行分布。这样的话两个表做连接的时候是不需要进行重新分布的。右边的查询计划表示了一个需要重新分布数据的例子。该查询计划和左边的查询计划相比多了一个Motion节点。
更详细的介绍请看 http://www.36dsj.com/archives/36776
Apache HAWQ 官网
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 [email protected] 举报,一经查实,本站将立刻删除。