

Brooklin 为什么要开发 Brooklin?什么是 Brooklin?应用场景数据传输桥多租户变更数据捕获CDC 介绍
Brooklin 是一种近实时的大规模数据流分布式服务,LinkedIn 自 2016 年以来一直在使用这项服务,支撑每天数千个数据流和超过 2
万亿条消息。

为什么要开发 Brooklin?
由于对可扩展、低延迟数据处理管道的需求不断在增长,LinkedIn
的数据基础设施也一直在不断演化。以一种可信赖的方式高速传输大量数据并非易事,除此之外,他们还要解决其他问题——为快速增长的数据存储类型和消息系统提供支持同样是一个有待解决的大问题。为此,LinkedIn
开发了 Brooklin,满足了他们对在数据量和系统可变性方面具备伸缩能力的系统的需求。
什么是 Brooklin?
Brooklin 是一个分布式系统,旨在将数据以可靠的方式大规模传输至多个不同的数据存储系统和消息系统。它公开了一组抽象概念,通过编写新的 Brooklin
消费者和生产者来扩展其支持新系统消费和生产数据的能力。在 LinkedIn,Brooklin 被用来将数据传输至多个数据存储系统(如 Espresso 和
Oracle)和消息系统(如 Kafka、Azure Event Hubs 和 AWS Kinesis)。
应用场景
Brooklin 有两大类应用场景:数据传输桥和变更数据捕获(Change Data Capture,CDC)。
数据传输桥
数据可以分布在不同的环境(公有云及公司的数据中心)、地理位置或部署组中。通常情况下,由于访问机制、序列化格式、合规性或安全要求的差异,每个环境都有其自身的复杂性。Brooklin
可以作为这些环境之间的“桥梁”,在这些环境之间传输数据。例如,Brooklin 可以在不同的云服务(例如 AWS Kinesis 和 Microsoft
Azure)之间、同一数据中心内的不同集群之间甚至不同的数据中心之间传输数据。
Brooklin
致力于提供跨环境数据传输服务,只需要这一项服务即可应对所有复杂的情况,让应用程序开发人员可以专注于处理数据而不是移动数据。此外,这种中心化、托管式和可扩展的框架也方便各个企业实施策略和实现数据监管。例如,通过配置
Brooklin,可以在公司内部实施统一策略,比如要求任何流入的数据都必须采用 JSON 格式,或者任何流出的数据都必须加密。
在开发 Brooklin 之前,LinkedIn 使用 Kafka MirrorMaker(KMM)将 Kafka 数据从一个 Kafka 集群镜像到另一个
Kafka 集群,但在使用这个工具时遇到了伸缩性问题。Brooklin 可以作为数据传输的通用桥梁,这样他们就能够轻松传输大量的 Kafka
数据。正是如此,他们才放弃了 KMM,转而将 Kafka 镜像解决方案整合到 Brooklin 中。
Brooklin 在 LinkedIn 的最大应用场景之一是在集群之间和数据中心之间镜像 Kafka 数据。LinkedIn 重度依赖 Kafka,用
Kafka 来存储所有类型的数据,例如日志记录、跟踪及指标,等等。为了方便集中访问,LinkedIn 的所有数据中心都使用 Brooklin
进行数据汇总。他们还用 Brooklin 在 LinkedIn 和 Azure 之间传输大量的 Kafka 数据。
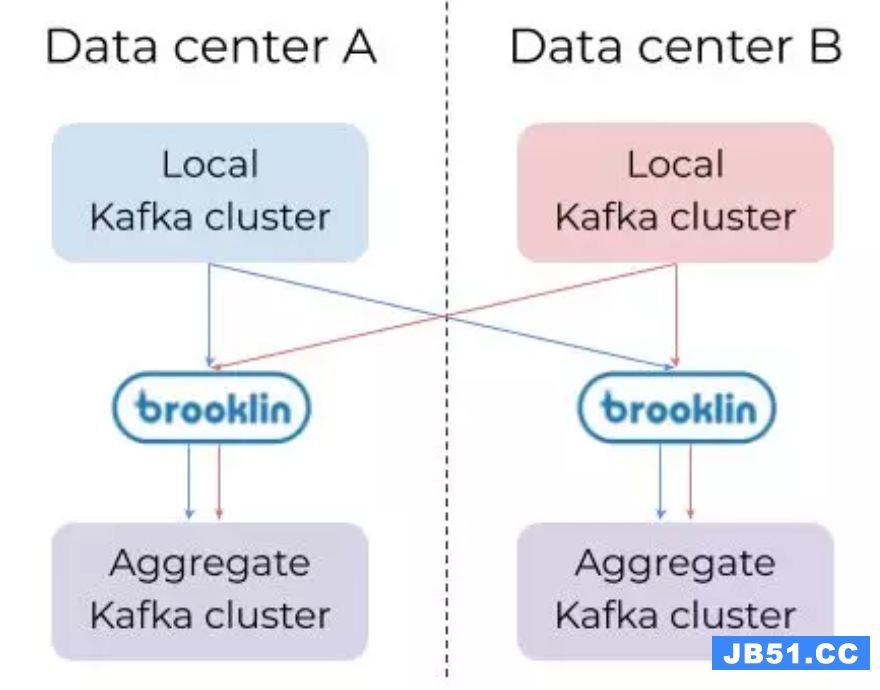
图示为一个假设示例,Brooklin 被用来汇集两个数据中心的 Kafka 数据,从而可以轻松地从任何数据中心访问整个数据集。每个数据中心的
Brooklin 群集都可以处理多个来源和目的地
Brooklin 用于镜像 Kafka 数据的方案已经过大规模测试,它已完全取代了之前的 KMM,每天镜像消息达数万亿条。Brooklin 解决了使用
KMM 时的痛点,无论是稳定性和可操作性都有所提升。基于 Brooklin 构建 Kafka 镜像解决方案,就可以很好地利用 Brooklin
的一些关键特性,下文将进行更详细的说明。
多租户
在 KMM 部署模型中,每个 KMM 集群只能在两个 Kafka 群集之间镜像数据。因此,KMM 用户通常需要使用数十个甚至数百个单独的 KMM
集群,这种方式非常难以管理。由于 Brooklin 同时可以处理多个独立的数据管道,所以可以使用一个 Brooklin 集群来同步多个 Kafka
集群,从而降低了维护数百个 KMM 集群的复杂性。

图示为一个假设示例,使用 KMM 来汇集两个数据中心的 Kafka 数据。相比之下,Brooklin 需要的 KMM 集群更少(一个 Brooklin
对应一个来源和目的地)
动态配置和管理
有了 Brooklin 服务,通过 HTTP 调用 REST 端点即可轻松创建新数据管道(也称为数据流)和修改现有管道。如果要镜像
Kafka,无需做出更改或部署静态配置即可轻松创建新的镜像管道或修改现有管道的镜像白名单。
虽然镜像管道可以在同一个集群中共存,但 Brooklin
可以单独控制和配置每个管道。也就是说,修改管道的镜像白名单或向管道添加更多资源都不会影响到其他管道。此外,Brooklin
允许按需暂停和恢复单个管道,这在临时操作或修改管道时非常有用。在进行 Kafka 镜像时,Brooklin
支持暂停或恢复整个管道、白名单中的单个主题,甚至单个主题分区。
问题诊断
Brooklin 还公开了一个诊断 REST 端点,可以按需查询数据流的状态。可以通过该 API
轻松查询某个管道的内部状态,包括单个主题分区是否出现滞后或错误。由于诊断端点汇集了整个 Brooklin
集群的信息,因此可以无需扫描日志文件就可以快速诊断特定分区的问题。
特殊功能
开发 Brooklin 的目的是为了取代 KMM,因此他们对 Brooklin 的 Kafka
镜像解决方案进行了优化,提高了稳定性和可操作性。为此,他们针对 Kafka 镜像进行了一些独有的改进。
他们努力实现更好的故障隔离,在镜像一个特定分区或主题时出现的错误不会影响到整个管道或集群。Brooklin
能够在分区级别检测出错误,并自动暂停这些有问题的分区镜像。过了一段时间(可配)之后,这些自动暂停的分区可以自动恢复,不需要手动干预。这种特性在临时出现错误时特别有用。与此同时,其他分区和管道的处理不受影响。
为了改进镜像延迟和吞吐量,Brooklin 还可以在免冲刷(flushless)生产模式下运行,在这个模式下,Kafka
的处理进度可在分区级别进行跟踪。检查点是在每个分区而不是管道级别完成的,所以 Brooklin 可以避免进行 Kafka
生产者冲刷(这是一种阻塞的同步调用,通常会让整个管道停顿几分钟)。
通过将 LinkedIn 的所有 KMM 迁移到 Brooklin,他们将镜像集群的数量从数百个减少到大约 12 个。利用 Brooklin 进行
Kafka 镜像还可以加速迭代,因为他们还在不断添加新特性和改进。
变更数据捕获(CDC)
Brooklin 的第二个主要应用场景是变更数据捕获。这些应用场景主要任务是以低延迟数据流的形式传输数据库的更新。例如,LinkedIn
的大部分真实数据(例如作业、连接和配置文件信息)都保存在各种数据库中。有一些应用程序需要知道何时发布了新工作职位、建立新的专业联系或更新成员个人资料。这些应用程序不需要通过查询在线数据库来检测这些变更,Brooklin
会通过近实时的方式传输这些数据库更新。使用 Brooklin
进行变更数据捕获的最大优势之一是可以更好地实现应用程序和在线数据存储系统之间的资源隔离。应用程序可以独立于数据库进行扩展,从而降低了拖垮数据库的风险。LinkedIn
使用 Brooklin 构建 Oracle、Espresso 和 MySQL 的变更数据捕获解决方案 ; 此外,Brooklin
的可扩展模型还有助于编写新的连接器,为数据库源添加 CDC 支持。

变更数据捕获可用于捕获在线数据源的更新,并将其传播到众多应用程序进行近线处理。示例用例是一个通知服务 /
应用程序,用于监听配置文件更新,以便向相关用户发送通知
引导支持
有时,在处理增量更新之前,应用程序可能需要完整的数据快照。这在应用程序第一次启动或者由于处理逻辑的变更需要重新处理整个数据集时,可能会出现这种情况。Brooklin
的可扩展连接器模型可以支持这种用例。
事务支持
很多数据库都支持事务,对于这些数据源,Brooklin 连接器可以确保事务边界。
更多信息
第一个 Brooklin 发布版本引入了 Kafka 镜像功能,可以使用项目提供的简单指令和脚本来测试。Brooklin
团队正在努力增加对更多数据源和目的地的支持,敬请期待!
介绍内容来自
AI前线
Brooklin 为什么要开发 Brooklin?什么是 Brooklin?应用场景数据传输桥多租户变更数据捕获CDC 官网
https://github.com/linkedin/Brooklin
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 [email protected] 举报,一经查实,本站将立刻删除。