

Apache IoTDB 介绍
IoTDB是针对时间序列数据收集、存储与分析一体化的数据管理引擎。它具有体量轻、性能高、易使用的特点,完美对接Hadoop与Spark生态,适用于工业物联网应用中海量时间序列数据高速写入和复杂分析查询的需求。
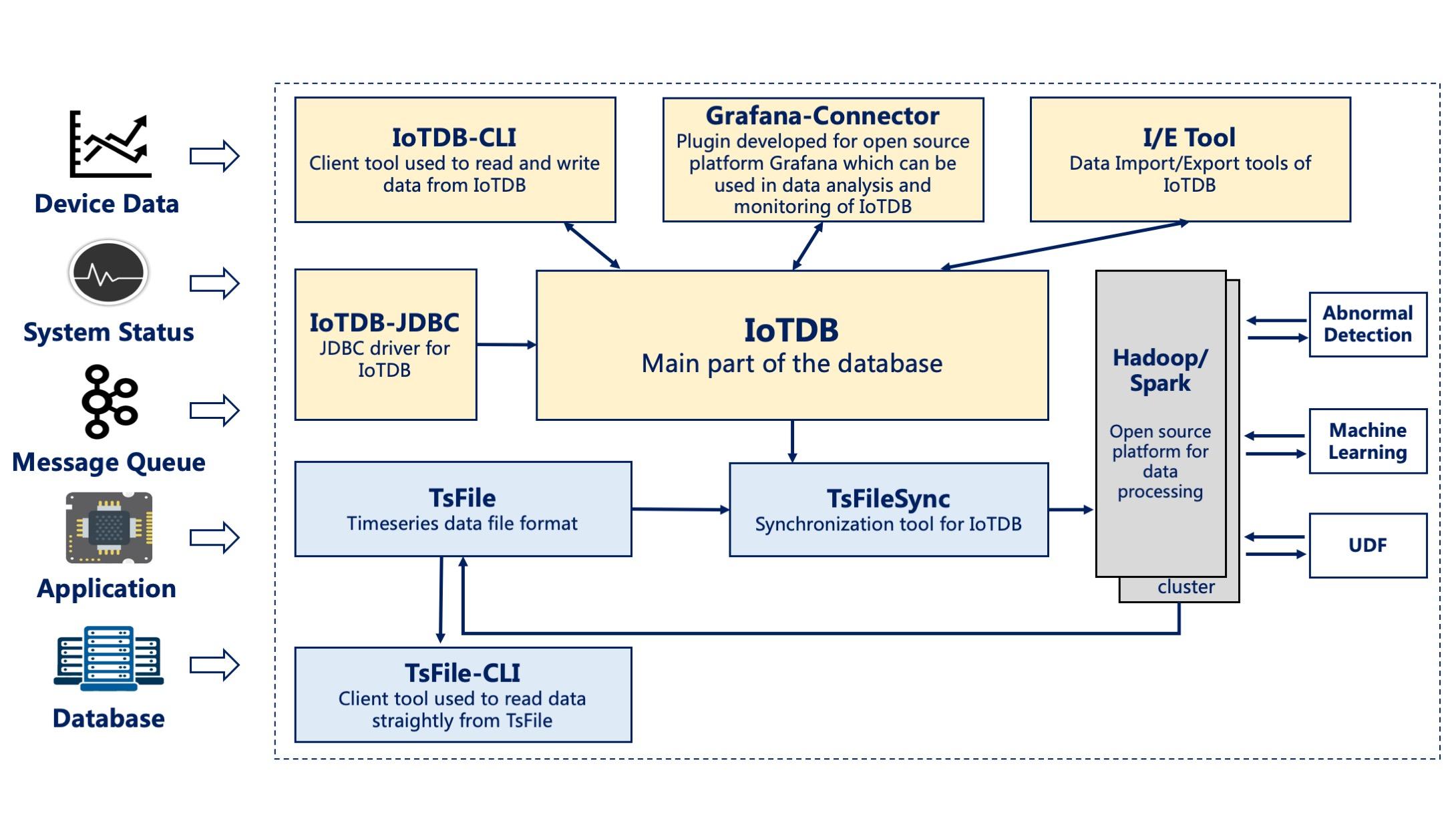
主要功能与特点
IoTDB具有以下特点:
- 灵活的部署方式
- 云端一键部署
- 终端解压即用
- 终端-云端无缝连接(数据云端同步工具)
- 低硬件成本的存储解决方案
- 高压缩比的磁盘存储(10亿数据点硬盘成本低于1.4元)
- 目录结构的时间序列组织管理方式
- 支持复杂结构的智能网联设备的时间序列组织
- 支持大量同类物联网设备的时间序列组织
- 可用模糊方式对海量复杂的时间序列目录结构进行检索
- 高通量的时间序列数据读写
- 支持百万级低功耗强连接设备数据接入(海量)
- 支持智能网联设备数据高速读写(高速)
- 以及同时具备上述特点的混合负载
- 面向时间序列的丰富查询语义
- 跨设备、跨传感器的时间序列时间对齐
- 面向时序数据特征的计算(频域变换,0.8.0版本不支持)
- 提供面向时间维度的丰富聚合函数支持
- 极低的学习门槛
- 支持类SQL的数据操作
- 提供JDBC的编程接口
- 完善的导入导出工具(0.8.0版本不支持)
- 完美对接开源生态环境
- 支持开源数据分析生态系统:Hadoop、Spark
- 支持开源可视化工具对接:Grafana
Apache IoTDB 官网
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 [email protected] 举报,一经查实,本站将立刻删除。