

@
介绍一下你做的某些模块,有些什么比较复杂的地方?
略。
你们的文件怎么存储的?
我们的文件是存储在MongoDB中的。
MongoDB单个文档的存储限制是16M,如果要存储大于16M的文件,就要用到MongoDB GridFS。
GridFS是Mongo的一个子模块,使用GridFS可以基于MongoDB来持久存储文件。并且支持分布式应用(文件分布存储和读取)。作为MongoDB中二进制数据存储在数据库中的解决方案,通常用来处理大文件。
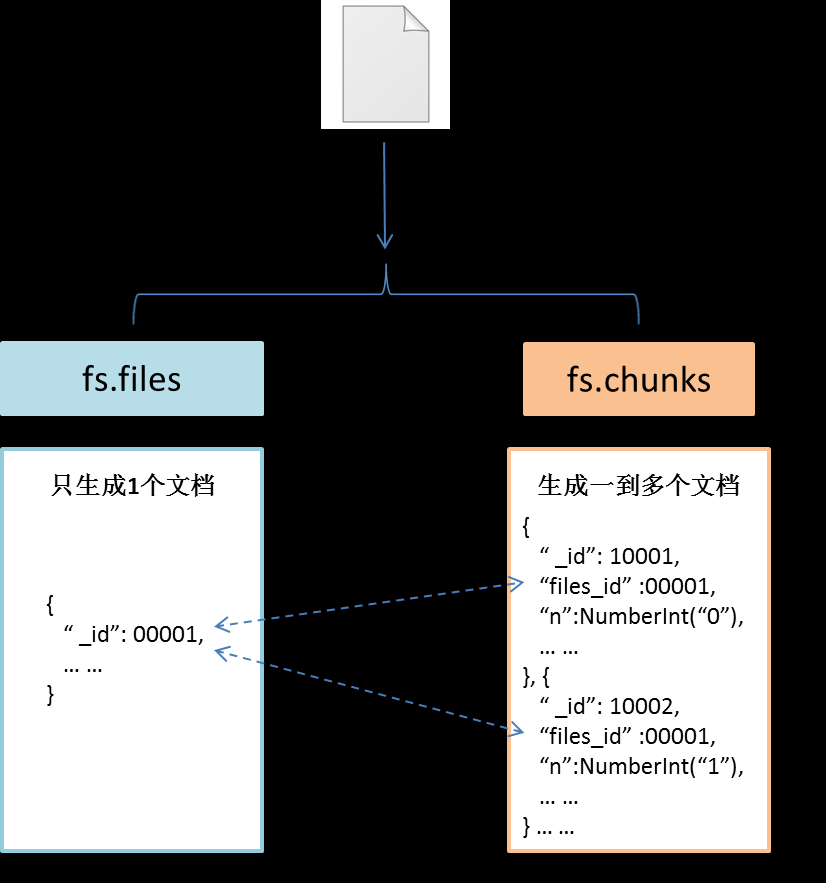
GridFS使用两个集合(collection)存储文件。一个集合是chunks,用于存储文件内容的二进制数据;一个集合是files,用于存储文件的元数据。
GridFS会将两个集合放在一个普通的buket中,并且这两个集合使用buket的名字作为前缀。MongoDB的GridFs默认使用fs命名的buket存放两个文件集合。因此存储文件的两个集合分别会命名为集合fs.files,集合fs.chunks。
怎么没有用文件服务器?
直接将文件使用通过FTP上传到文件服务器,并将文件地址存储到MySQL数据库。这种方式也是可行的。
但是,文件系统到了后期会变的很难管理,同时不利于扩展,此外我想做分布式文件系统也显得不那么容易。而GridFS却正好相反,它基于MongoDB的文件系统,便于管理和扩展。
当然了,还有其它的一些分布式文件存储系统如FastDFS,可以根据文件存储的实际情况来进行选择。
文件存储有没有做备份?
目前是手动备份。
后面计划写一个自动备份的脚本来每日备份。
在项目上有没有什么搞不定的问题?
略。
对搞不定的问题你是怎么处理的?
略。
你们项目怎么测试?
略。
MyBatis#和$有什么区别?
#{}是预编译处理,${}是字符串替换。
(1)mybatis在处理#{}时,会将sql中的#{}替换为?号,调用PreparedStatement的set方法来赋值。
(2)mybatis在处理${}时,就是把${}替换成变量的值。
(3)使用#{}可以有效的防止SQL注入,提高系统安全性。原因在于:预编译机制。
预编译是提前对SQL语句进行预编译,而其后注入的参数将不会再进行SQL编译。我们知道,SQL注入是发生在编译的过程中,因为恶意注入了某些特殊字符,最后被编译成了恶意的执行操作。而预编译机制则可以很好的防止SQL注入。预编译完成之后,SQL的结构已经固定,即便用户输入非法参数,也不会对SQL的结构产生影响,从而避免了潜在的安全风险。
Redis你用到它那些结构?
主要用到了String、Hash、Set。
String:常规key-value缓存应用。用来存一些计数。
Hash: 键值(key => value)对集合。用来存一些对象,对应Java集合中的HashMap。
Set: set是string类型的无序集合。对应Java中的HashSet,用来存一些需要去重的数据。
多线程你了解多少?
-
先说说多线程是个什么:
要说线程,就得先讲,进程:进程可以简单的理解为一个可以独立运行的程序单位,它是线程的集合,进程就是有一个或多个线程构成的。而线程是进程中的实际运行单位,是操作系统进行运算调度的最小单位。可理解为线程是进程中的一个最小运行单元。
那么多线程就很容易理解:多线程就是指一个进程中同时有多个线程正在执行。 -
再说说为什么要用多线程?
简单说来,使用多线程就是为了提高CPU的利用效率。 -
最后简单说说线程的创建:在Java中有三种线程创建方式。
继承 Thread 类创建线程类
实现Runnable接口创建线程类
使用 Callable 和 Future 创建线程
怎么保证线程安全?
保证线程安全有以下几种方式:
- Synchronized 关键字:被 Synchronized 关键字描述的方法或代码块在多线程环境下同一时间只能由一个线程进行访问,在持有当前 Monitor 的线程执行完成之前,其他线程想要调用相关方法就必须进行排队,知道持有持有当前 Monitor 的线程执行结束,释放 Monitor ,下一个线程才可获取 Monitor 执行。
- Volatile 关键字:被 Volatile 关键字描述变量的操作具有可见性和有序性(禁止指令重排)
- java.util.concurrent.atomic原子操作:ava.util.concurrent.atomic 包提供了一系列的 AtomicBoolean、AtomicInteger、AtomicLong 等类。使用这些类来声明变量可以保证对其操作具有原子性来保证线程安全。
- Lock:Lock 也是 java.util.concurrent 包下的一个接口,定义了一系列的锁操作方法。Lock 接口主要有 ReentrantLock,ReentrantReadWriteLock.ReadLock,ReentrantReadWriteLock.WriteLock 实现类。与 Synchronized 不同是 Lock 提供了获取锁和释放锁等相关接口,使得使用上更加灵活,同时也可以做更加复杂的操作。
怎么管理线程?
通常,会使用线程池来管理线程。
在 JDK 1.5 之后推出了相关的 api,常见的创建线程池方式有以下几种:
- Executors.newCachedThreadPool():无限线程池。
- Executors.newFixedThreadPool(nThreads):创建固定大小的线程池。
- Executors.newSingleThreadExecutor():创建单个线程的线程池。
其实看这三种方式创建的源码就会发现:
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0,Integer.MAX_VALUE,60L,TimeUnit.SECONDS,new SynchronousQueue<Runnable>());
}
实际上还是利用 ThreadPoolExecutor 类实现的。
通常我们都是使用:
threadPool.execute(new Job());
这样的方式来提交一个任务到线程池中,所以核心的逻辑就是 execute() 函数了。
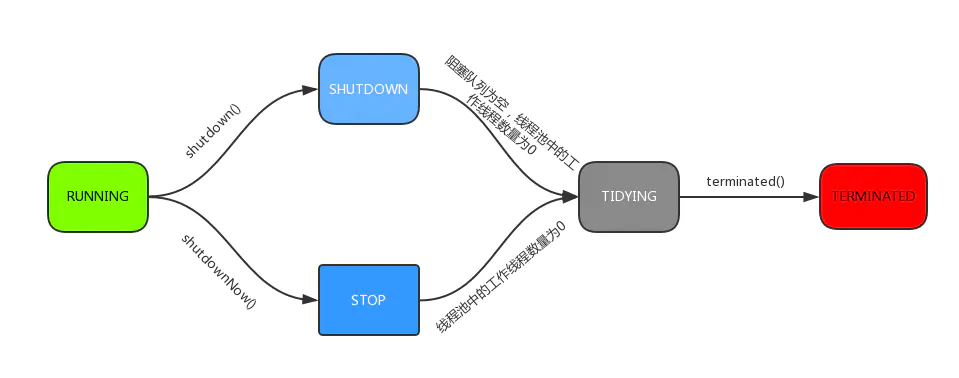
线程池一共有五种状态,分别是:
- RUNNING :能接受新提交的任务,并且也能处理阻塞队列中的任务;
- SHUTDOWN:关闭状态,不再接受新提交的任务,但却可以继续处理阻塞队列中已保存的任务。在线程池处于 RUNNING 状态时,调用 shutdown()方法会使线程池进入到该状态。(finalize() 方法在执行过程中也会调用shutdown()方法进入该状态);
- STOP:不能接受新任务,也不处理队列中的任务,会中断正在处理任务的线程。在线程池处于 RUNNING 或 SHUTDOWN 状态时,调用 shutdownNow() 方法会使线程池进入到该状态;
- TIDYING:如果所有的任务都已终止了,workerCount (有效线程数) 为0,线程池进入该状态后会调用 terminated() 方法进入TERMINATED 状态。
- TERMINATED:在terminated() 方法执行完后进入该状态,默认terminated()方法中什么也没有做。
进入TERMINATED的条件如下: -
- 线程池不是RUNNING状态;
-
- 线程池状态不是TIDYING状态或TERMINATED状态;
-
- 如果线程池状态是SHUTDOWN并且workerQueue为空;
-
- workerCount为0;
-
- 设置TIDYING状态成功。
下图为线程池的状态转换过程:
再看看Excute方法的执行:
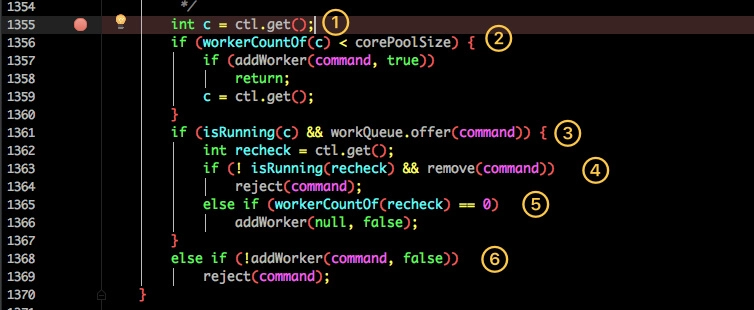
1、获取当前线程池的状态。
2、当前线程数量小于 coreSize 时创建一个新的线程运行。
3、如果当前线程处于运行状态,并且写入阻塞队列成功。
4、双重检查,再次获取线程状态;如果线程状态变了(非运行状态)就需要从阻塞队列移除任务,并尝试判断线程是否全部执行完毕。同时执行拒绝策略。
5、如果当前线程池为空就新创建一个线程并执行。
6、如果在第三步的判断为非运行状态,尝试新建线程,如果失败则执行拒绝策略。
当前SpringBoot比较流行,我们可以发挥Spring的特性,由Spring来替我们管理线程:
@Configuration
public class TreadPoolConfig {
/**
* 消费队列线程
* @return
*/
@Bean(value = "consumerQueueThreadPool")
public ExecutorService buildConsumerQueueThreadPool(){
ThreadFactory namedThreadFactory = new ThreadFactoryBuilder()
.setNameFormat("consumer-queue-thread-%d").build();
ExecutorService pool = new ThreadPoolExecutor(5,5,0L,TimeUnit.MILLISECONDS,new ArrayBlockingQueue<Runnable>(5),namedThreadFactory,new ThreadPoolExecutor.AbortPolicy());
return pool ;
}
}
使用时:
@Resource(name = "consumerQueueThreadPool")
private ExecutorService consumerQueueThreadPool;
@Override
public void execute() {
//消费队列
for (int i = 0; i < 5; i++) {
consumerQueueThreadPool.execute(new ConsumerQueueThread());
}
}
其实也挺简单,就是创建了一个线程池的 bean,在使用时直接从 Spring 中取出即可。
假如有一个List,其中存的是用户User对象,用户对象有很多属性,我要根据其中的年龄属性对List排序,这个该怎么办?
可以通过Collections类的sort方法。但需要注意,使用sort方法的时候:
- 要么 User类实现Comparable
接口,并在类中编写public int compareTo(T o)方法
public class User implements Comparable<User> {
private int age;
private String name;
private String sex;
@Override
public int compareTo(User o) {
if (this.getAge() > o.getAge()) {
return 1;
} else if (this.getAge() < o.getAge()) {
return -1;
} else {
return 0;
}
}
// ……
}
List<User> userList=new ArrayList();
userList.add(new User(10,"王二","男"));
userList.add(new User(8,"张三","男"));
userList.add(new User(17,"李四","女"));
Collections.sort(userList);
System.out.println(userList);
- 或者在排序的时候,给sort()方法传入一个比较器。具体来说,就是传入一个实现比较器接口的匿名内部类。
List<User> userList=new ArrayList();
userList.add(new User(10,"女"));
//Collections.sort(userList);
Collections.sort(userList,new Comparator<User>() {
@Override
public int compare(User o1,User o2) {
if(o1.getAge()>o2.getAge()) {
return 1;
}else if(o1.getAge()<o2.getAge()) {
return -1;
}else {
return 0;
}
}
});
System.out.println(userList);
在Java8以后可以使用Lamda表达式来进行函数式地编程:
userList.sort((a,b) -> Integer.compare(a.getAge(),b.getAge()));
jdk 1.8的Stream用的多吗?
Stream 作为 Java 8 的一大亮点,它与 java.io 包里的 InputStream 和 OutputStream 是完全不相关的东西。
Java 8 中的 Stream 是对集合(Collection)对象功能的增强,它专注于对集合对象进行各种非常便利、高效的聚合操作(aggregate operation),或者大批量数据操作 (bulk data operation)。
下面是使用流的过程:
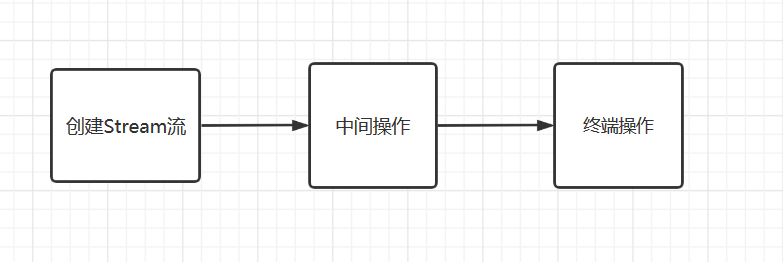
下面是一个使用流的实例,用于List的迭代:
List<String> stringList = new ArrayList<String>();
stringList.add("one");
stringList.add("two");
stringList.add("three");
stringList.add("one");
Stream<String> stream = stringList.stream();
stream.forEach( element -> { System.out.println(element); });
JWT知道吗?
JSON Web Token(缩写 JWT)是目前最流行的跨域认证解决方案。
传统的session认证一般是这样的流程:
- 1、用户向服务器发送用户名和密码。
* 2、服务器验证通过后,在当前对话(session)里面保存相关数据,比如用户角色、登录时间等等。
-
3、服务器向用户返回一个 session_id,写入用户的 Cookie。
-
4、用户随后的每一次请求,都会通过 Cookie,将 session_id 传回服务器。
-
5、服务器收到 session_id,找到前期保存的数据,由此得知用户的身份。
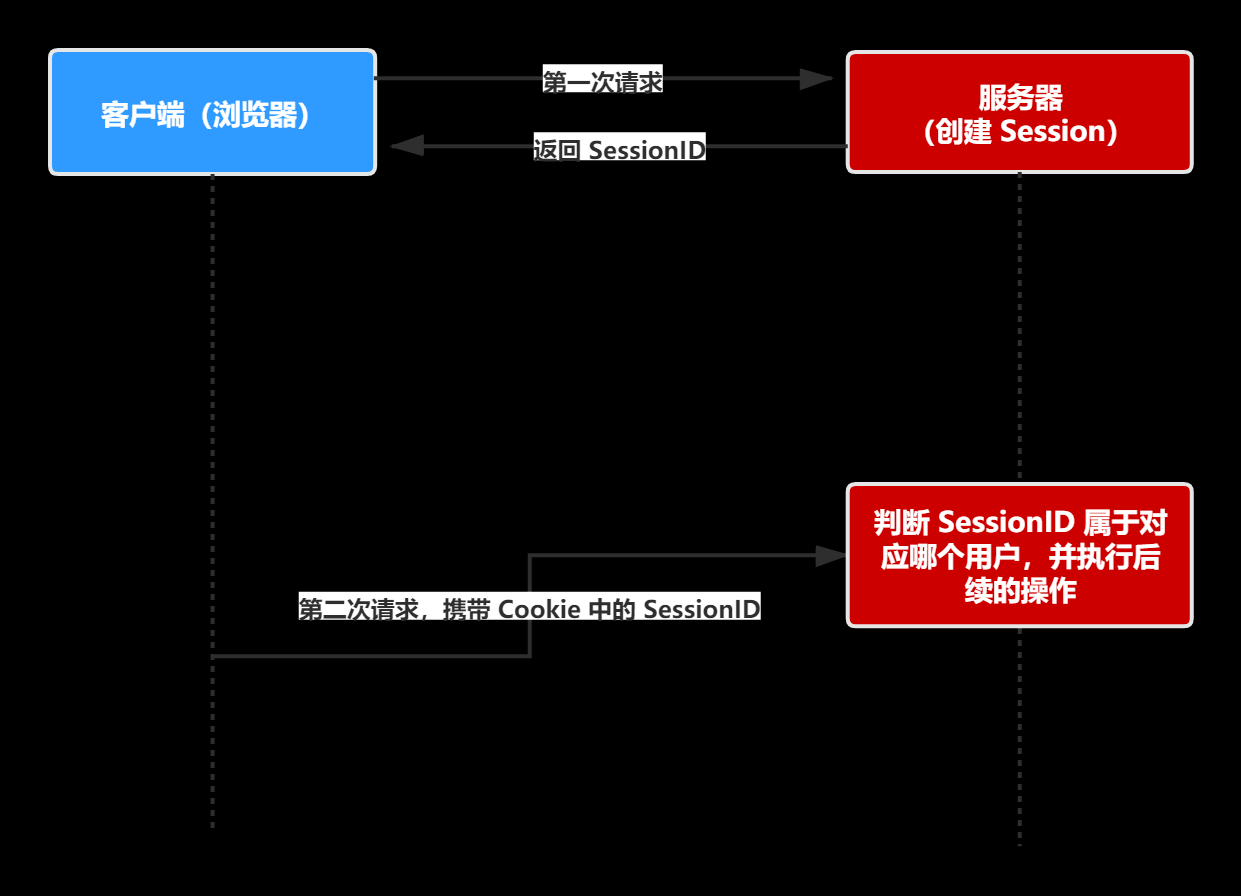
这种模式的问题在于,扩展性(scaling)不好。单机当然没有问题,如果是服务器集群,或者是跨域的服务导向架构,就要求 session 数据共享,每台服务器都能够读取 session。
一种解决方案是 session共享,将session持久化或者存入缓存。各种服务收到请求后,都向持久层或缓存请求数据。这种方案的优点是架构清晰,缺点是工程量比较大。另外,持久层或者缓存万一挂了,就会认证失败。
另一种方案是服务器索性不保存 session 数据了,所有数据都保存在客户端,每次请求都发回服务器。JWT 就是这种方案的一个代表。
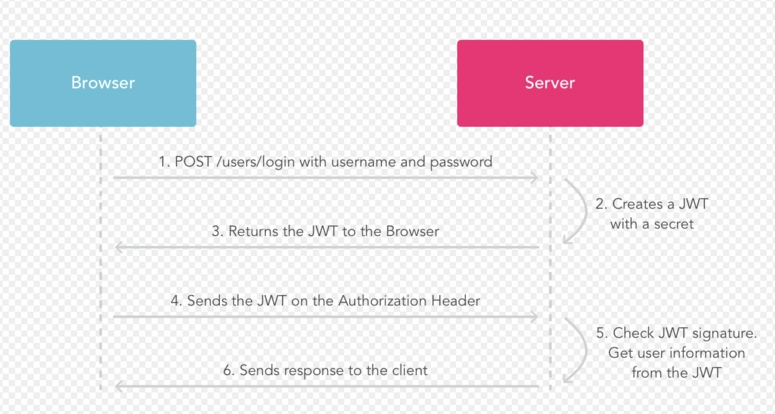
JWT认证流程:
- 1、 用户使用账号和密码发出post请求;
- 2、 服务器使用私钥创建一个jwt;
- 3、 服务器返回这个jwt给浏览器;
- 4、 浏览器将该jwt串在请求头中像服务器发送请求;
- 5、 服务器验证该jwt;
- 6、 返回响应的资源给浏览器。
数据库事务知道吗?
事务(TRANSACTION)是作为单个逻辑工作单元执行的一系列操作, 这些操作作为一个整体一起向系统提交,要么都执行、要么都不执行 。
事务是一个不可分割的工作逻辑单元事务必须具备以下四个属性,简称 ACID 属性:
- 原子性(Atomicity) :事务是一个完整的操作。事务的各步操作是不可分的(原子的);要么都执行,要么都不执行。
- 一致性(Consistency): 当事务完成时,数据必须处于一致状态。
- 隔离性(Isolation) :对数据进行修改的所有并发事务是彼此隔离的, 这表明事务必须是独立的,它不应以任何方式依赖于或影响其他事务。
- 永久性(Durability) : 事务完成后,它对数据库的修改被永久保持,事务日志能够保持事务的永久性
你写的代码用到事务吗?
通过在方法加注解 @Transactional 来实现声明式的事务。
Spring 事务管理分为编码式和声明式的两种方式。编程式事务指的是通过编码方式实现事务;声明式事务基于 AOP,将具体业务逻辑与事务处理解耦。声明式事务管理使业务代码逻辑不受污染,因此在实际使用中声明式事务用的比较多。声明式事务有两种方式,一种是在配置文件(xml)中做相关的事务规则声明,另一种是基于 @Transactional 注解的方式。
常用的检索优化方式有哪些?
- 1、查询语句中不要使用select *
- 2、尽量减少子查询,使用关联查询(left join,right join,inner join)替代
- 3、减少使用IN或者NOT IN,使用exists,not exists或者关联查询语句替代
- 4、or 的查询尽量用 union或者union all 代替(在确认没有重复数据或者不用剔除重复数据时,union all会更好)
- 5、应尽量避免在 where 子句中使用!=或<>操作符,否则将引擎放弃使用索引而进行全表扫描。
- 6、应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描,如: select id from t where num is null 可以在num上设置默认值0,确保表中num列没有null值,然后这样查询: select id from t where num=0
Linux了解多少?
(这里应该是想问用过的命令)日产工作中,下面这些命令经常用到:
- 查看当前目录:pwd
- 切换目录 : cd
- 查看目录下的文件 :ls/ls -lh
- 创建目录:mkdir
- 启动war包:java -jar xx.war
- 后台启动war包:nohup java -jar * xx.war&
- 查找进程:ps –aux|grep java
- 杀死进程:kill -9 pid
参考:
【1】:SpringBoot学习笔记(十一:使用MongoDB存储文件 )
【2】:GridFS 基于 MongoDB 的分布式文件存储系统
【3】:Linux下shell脚本实现mongodb定时自动备份
【4】:Mybatis中#{}和${}的区别是什么
【5】:Redis五种数据类型及应用场景
【6】:Redis五种数据类型及应用场景
【7】:面试官:说说什么是线程安全?一图带你了解java线程安全
【8】:如何优雅的使用和理解线程池
【9】:深入理解 Java 线程池:ThreadPoolExecutor
【10】:透彻的掌握 Spring 中 @Transactional的使用
【11】:SpringBoot学习笔记(十三:JWT )
【12】:Java8 Stream
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 [email protected] 举报,一经查实,本站将立刻删除。