
Numpy 遍历数组
Numpy 提供了一个迭代器对象 numpy.nditer,能够实现灵活地访问一个或者多个数组元素,达到遍历数组的目的。
1. 数组元素访问
1.1 按照内存布局打印数组元素
在默认情况下,numpy.nditer 迭代器返回的元素顺序,是和数组内存布局一致的,这样做是为了提升访问的效率,默认是行序优先。
案例
例如,我们对于新创建的 2×3 的数组,利用 nditer 迭代器进行顺序访问:
arr = np.arange().reshape(,)
arr Out: array([[, , ], [, , ]])
for i in np.nditer(arr):print(i, end= )
打印结果为:
可以看到,在不增加其他设置的情况下,默认的打印顺序是行序优先(即 C-order)。
在不改变内部布局的情况下,通过该方式进行遍历,并不会改变顺序,例如我们通过迭代上述数组的转置来证明这一点。
for i in np.nditer(arr.T):print(i, end= )
打印结果为:
从上述结果可以看出,转置方法并未改变数组元素的存储顺序。
相对应的,我们利用 copy 方法,显式地更改内存顺序,nditer 迭代器的遍历解雇也会发生响应的变化:
for i in np.nditer(arr.T.copy(C)):print(i, end= )
打印结果为:
1.2 控制遍历顺序
如果想要改变遍历的顺序,一种是上面案例中提到的,利用 copy 方法来修改内存顺序。当然,nditer 也提供了 order 参数来达到同样的目的。
案例
C order,即是行序优先,跟默认的遍历顺序一致。
print ('以 C 风格顺序排序:')for i in np.nditer(arr, order=C):print(i, end= )打印结果为:
以 C 风格顺序排序:
Fortran order,即是列序优先:
print ('以 F 风格顺序排序:')for i in np.nditer(arr, order=F):print(i, end= )打印结果为:
以 F 风格顺序排序:
2. 数组元素修改
nditer 对象有另一个可选参数 op_flags。 默认情况下,nditer 将视待迭代遍历的数组为只读对象(read-only),为了在遍历数组的同时,实现对数组元素值得修改,必须指定 read-write 或者 write-only 的模式。
案例
在遍历的时候,对数组进行平方计算,生成一个特殊的平方方阵。
arr1 = np.arange().reshape(,)
arr1 Out:array([[ , , , ], [ , , , ], [ , , , ], [, , , ]])
# 指定读写模式for i in np.nditer(arr1, op_flags=[readwrite]):i[...] = i**
arr1 Out:array([[ , , , ], [ , , , ], [ , , , ], [, , , ]])
在读写模式下,arr1 数组发生了变化。
3. flags 可选参数
flags 参数可以接受传入一个数组或元组,它可以接受下列值:
| 参数 | 描述 |
|---|---|
| c_index | 可以跟踪 C 顺序的索引 |
| f_index | 可以跟踪 Fortran 顺序的索引 |
| multi-index | 每次迭代可以跟踪多重索引类型 |
| external_loop | 给出的值是具有多个值的一维数组,而不是零维数组 |
3.1 可以跟踪 C 顺序的索引
跟 list 类似,每个元素都对应有相应的 id。在按照 C 顺序跟踪索引的时候,数组的索引可以按照下图来直观理解:

上述索引的标注是按照行优先的顺序进行的。
案例
设置 flags=[c_index],可以实现类似 list 的 enumerate 函数的效果:
cit = np.nditer(arr, flags=[c_index])while not cit.finished:print(value:, cit[], index:<{}>.format(cit.index))cit.iternext()打印结果为:
value: index:<>value: index:<>value: index:<>value: index:<>value: index:<>value: index:<>
在上述代码中,同过 while 循环可以逐步打印出每个元素的值和索引。
3.2 可以跟踪 Fortran 顺序的索引
在按照 F 顺序跟踪索引的时候,数组的索引可以按照下图来直观理解:
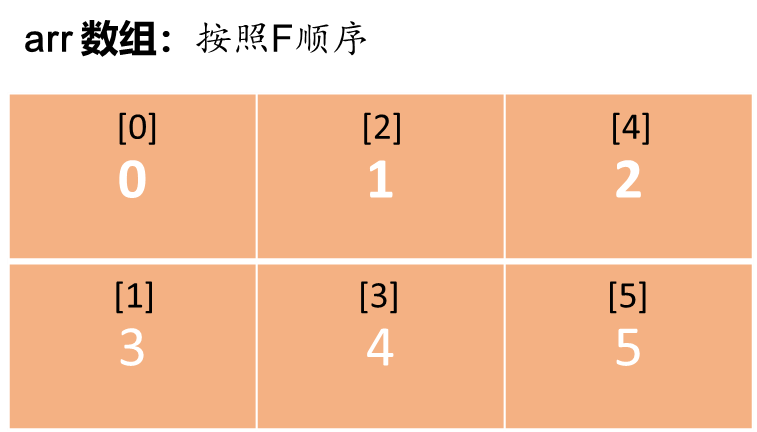
F 顺序即列优先的顺序。
案例
想要实现该索引顺序,可以设置 flags=[f_index]:
fit = np.nditer(arr, flags=[f_index])while not fit.finished:print(value:, fit[], index:<{}>.format(fit.index))fit.iternext()打印结果为:
value: index:<>value: index:<>value: index:<>value: index:<>value: index:<>value: index:<>
可以发现,在顺序打印该索引结构的时候,默认是按照行优先的顺序打印的。
也就是说,在打印索引结构的时候,打印的顺序是一样的,不同的地方在于,c_index和 f_index 索引标注的顺序不一样。
3.3 多重索引
对于 arr 这样的二维数组,可以用 2 个维度(x 方向和 y 方向)的序列来唯一定位每一个元素,multi-index 则可以打印出该种索引顺序。
multi_index 索引类型可以按照下图来直观理解:
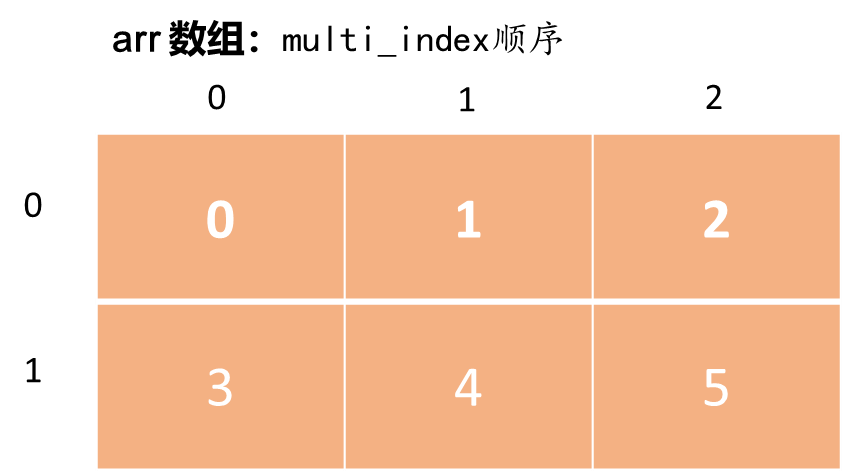
案例
设置 flags=[multi_index],效果如下:
mul_it = np.nditer(arr, flags=['multi_index'])while not mul_it.finished:print(value:, mul_it[], index:<{}>.format(mul_it.multi_index))mul_it.iternext()打印结果为:
value: index:<(, )>value: index:<(, )>value: index:<(, )>value: index:<(, )>value: index:<(, )>value: index:<(, )>
3.4 遍历返回一维数组
将一维的最内层的循环转移到外部循环迭代器,使得 NumPy 的矢量化操作在处理更大规模数据时变得更有效率。简单来说,当指定 flags=['external_loop'] 时,将返回一维数组而并非单个元素。
具体来说,当 ndarray 的顺序和遍历的顺序一致时,将所有元素组成一个一维数组返回;当 ndarray 的顺序和遍历的顺序不一致时,返回每次遍历的一维数组。
下面通过具体案例来理解这句话:
案例
对于上述创建的 arr,是行优先顺序的数组。当我们指定遍历顺序为C(行优先,与定义的顺序一致),指定 flags=[external_loop],则有:
for i in np.nditer(arr, flags=['external_loop'], order='C'):print(i)
打印结果为:
[ ]
可以看到,该案例中,把全部元素组成一个一维数组,并返回。
案例
当我们指定遍历顺序为F(列优先),指定 flags=[external_loop],则有:
for i in np.nditer(arr, flags=['external_loop'], order='F'):print(i)
打印结果为:
[ ][ ][ ]
可以看到,该案例中,返回每次遍历的一维数组。
4. 小结
本节主要介绍了如何利用 Numpy 内置的迭代器对象 numpy.nditer,实现灵活地遍历数组中的元素。numpy.nditer 迭代器提供了 order 参数,来控制访问的顺序;提供了 op_flags 参数,来设置只读或读写模式;提供 flags 参数来同步返回数组索引,功能非常强大。