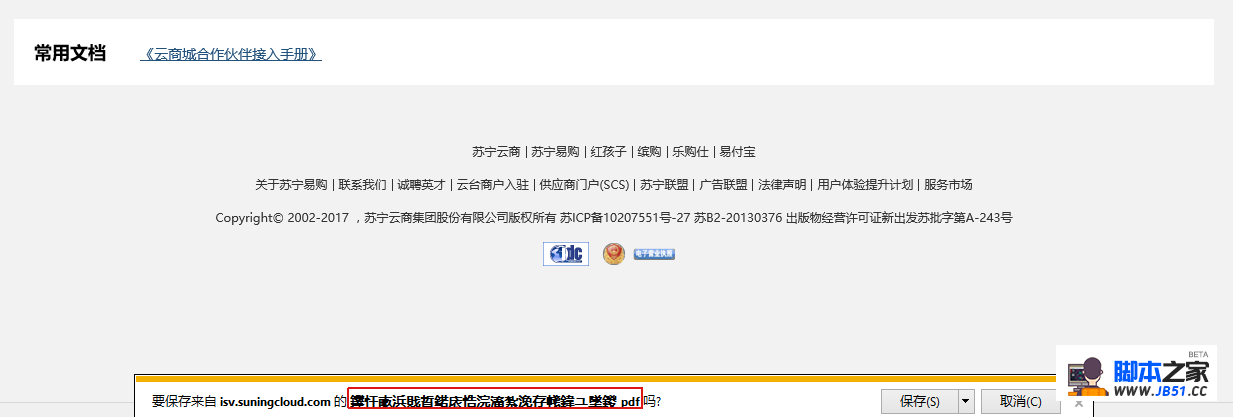
项目中有用到文件下载功能,之前在处理下载时对IE浏览器下文件下载名进行过处理,测试也没有问题,但是功能上线后,业务反馈IE11文件下载文件名依然乱码。打印User-Agent字符串如下:
IE11 User-Agent字符串:Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like GeckoIE6~IE10版本的User-Agent字符串:Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.0; Trident/6.0)
一、后端修改
IE浏览器在IE11,更改了User-Agent字符串格式内容,所以针对IE11,做一下判断即可:(后端代码更改)
= request.getSession().getServletContext().getRealPath("/upload/文档1.doc"
File file =
String filename =
Boolean flag= request.getHeader("User-Agent").indexOf("like Gecko")>0
<span style="color: #0000ff;">byte<span style="color: #000000;">[] buffer;
buffer = <span style="color: #0000ff;">new <span style="color: #0000ff;">byte<span style="color: #000000;">[fis.available()];
fis.read(buffer);
fis.close();
response.reset();
response.addHeader("Content-Disposition","attachment;filename=" +<span style="color: #000000;">filename);
response.addHeader("Content-Length","" +<span style="color: #000000;"> file.length());
OutputStream os =<span style="color: #000000;"> response.getOutputStream();
response.setContentType("application/octet-stream"<span style="color: #000000;">);
os.write(buffer);<span style="color: #008000;">//<span style="color: #008000;"> 输出文件
<span style="color: #000000;"> os.flush();
os.close();
} <span style="color: #0000ff;">catch<span style="color: #000000;"> (IOException e) {
<span style="color: #008000;">//<span style="color: #008000;"> TODO Auto-generated catch block
<span style="color: #000000;"> e.printStackTrace();
}
}
</span><span style="color: #0000ff;">if</span> (request.getHeader("User-Agent").toLowerCase().indexOf("msie") >0||<span style="color: #000000;">flag){
filename </span>= URLEncoder.encode(filename,"UTF-8");<span style="color: #008000;">//</span><span style="color: #008000;">IE浏览器</span>
}<span style="color: #0000ff;">else</span><span style="color: #000000;"> {
</span><span style="color: #008000;">//</span><span style="color: #008000;">先去掉文件名称中的空格,然后转换编码格式为utf-8,保证不出现乱码,</span><span style="color: #008000;">//</span><span style="color: #008000;">这个文件名称用于浏览器的下载框中自动显示的文件名</span>
filename = <span style="color: #0000ff;">new</span> String(filename.replaceAll(" ","").getBytes("UTF-8"),"ISO8859-1"<span style="color: #000000;">);
</span><span style="color: #008000;">//</span><span style="color: #008000;">firefox浏览器
</span><span style="color: #008000;">//</span><span style="color: #008000;">firefox浏览器User-Agent字符串:
</span><span style="color: #008000;">//</span><span style="color: #008000;">Mozilla/5.0 (Windows NT 6.1; WOW64; rv:36.0) Gecko/20100101 Firefox/36.0</span>
<span style="color: #000000;"> }
InputStream fis
<span style="color: #0000ff;">byte<span style="color: #000000;">[] buffer;
buffer = <span style="color: #0000ff;">new <span style="color: #0000ff;">byte<span style="color: #000000;">[fis.available()];
fis.read(buffer);
fis.close();
response.reset();
response.addHeader("Content-Disposition","attachment;filename=" +<span style="color: #000000;">filename);
response.addHeader("Content-Length","" +<span style="color: #000000;"> file.length());
OutputStream os =<span style="color: #000000;"> response.getOutputStream();
response.setContentType("application/octet-stream"<span style="color: #000000;">);
os.write(buffer);<span style="color: #008000;">//<span style="color: #008000;"> 输出文件
<span style="color: #000000;"> os.flush();
os.close();
} <span style="color: #0000ff;">catch<span style="color: #000000;"> (IOException e) {
<span style="color: #008000;">//<span style="color: #008000;"> TODO Auto-generated catch block
<span style="color: #000000;"> e.printStackTrace();
}
}
二、前端修改
同时作为前端也需要有一个兼容IE的心。
encodeURI函数,将其他部分字符串拼接。
encodeURI()是Javascript中真正用来对URL编码的函数。
它着眼于对整个URL进行编码,因此除了常见的符号以外,对其他一些在网址中有特殊含义的符号“; / ? : @ & = + $,#”,也不进行编码。编码后,它输出符号的utf-8形式,并且在每个字节前加上%。
<div class="cnblogs_code">
$scope.commonWord = baseUrl+"/downloadFile.htm?objectId="+encodeURI('欢迎你加入我们手册')+".pdf&fileName="+encodeURI('欢迎你加入我们手册')+".pdf";