
操作系统实验
作者寄语
操作系统实验的学习是一个循序渐进的过程,初次看linux-0.11中的代码,看着满屏的汇编语言,确实头疼。但通过学习赵炯博士的Linux内核0.11完全注释,结合着王爽老师的汇编语言一书,我逐渐理解每段汇编语言的含义和作用。本文主要是通过对哈工大李治军配套实验的实现,着重解释每一段的汇编代码,使读者对实验的整体脉络有一个初步的认识,不再因为畏惧汇编而不放弃实验。本文只是抛砖引玉,希望读者可以深入研究我下文提供的参考资料,做到理论与实践兼具。
参考资料
- 视频:操作系统
- 书籍:现代操作系统
- 实验:操作系统原理与实践
- 书籍:王道操作系统
- 书籍:Linux内核完全注释
- 书籍:汇编语言(第3版) 王爽著
目录
文章目录
实验一 熟悉实验环境
只是熟悉实验环境,我没有使用蓝桥云课的实验环境,而是通过阿里云服务器搭建了linux环境,有需要的可以看以下2篇文章
- 阿里云服务器Ubuntu14.04(64位)安装图形化界面_leoabcd12的博客-CSDN博客
- 阿里云ubuntu系统配置linux-0.11(哈工大 李治军)实验环境搭建_leoabcd12的博客-CSDN博客
实验二 操作系统的引导
Linux 0.11 文件夹中的 boot/bootsect.s、boot/setup.s 和 tools/build.c 是本实验会涉及到的源文件。它们的功能详见《Linux内核0.11完全注释》的 6.2、6.3 节和 16 章。
汇编知识
简要整理了一下这次实验所需的基础汇编知识,可以在下文阅读代码是碰到再回过头来看!
int 0x10

注意,这里ah要先有值,代表内部子程序的编号
功能号 a h = 0 x 03 ah=0x03 ah=0x03,作用是读取光标的位置
- 输入:bh = 页号
- 返回:ch = 扫描开始线;cl = 扫描结束线;dh = 行号;dl = 列号
功能号 a h = 0 x 13 ah=0x13 ah=0x13,作用是显示字符串
- 输入:al = 放置光标的方式及规定属性,下文 al=1,表示目标字符串仅仅包含字符,属性在BL中包含,光标停在字符串结尾处;es:bp = 字符串起始位置;cx = 显示的字符串字符数;bh = 页号;bl = 字符属性,下文 bl = 07H,表示正常的黑底白字;dh = 行号;dl = 列号
功能号 a h = 0 x 0 e ah=0x0e ah=0x0e,作用是显示字符
- 输入:al = 字符
int 0x13
在DOS等实模式操作系统下,调用INT 13h会跳转到计算机的ROM-BIOS代码中进行低级磁盘服务,对程序进行基于物理扇区的磁盘读写操作。
功能号 a h = 0 x 02 ah=0x02 ah=0x02,作用是读磁盘扇区到内存
-
输入:
寄存器 含义 ah 读磁盘扇区到内存 al 需要读出的扇区数量 ch 磁道 cl 扇区 dh 磁头 dl 驱动器 es:bx 数据缓冲区的地址 -
返回:ah = 出错码(00H表示无错,01H表示非法命令,02H表示地址目标未发现…);CF为进位标志位,如果没有出错 C F = 0 CF=0 CF=0
功能号 a h = 0 x 00 ah=0x00 ah=0x00,作用是磁盘系统复位
- 输入:dl = 驱动器
- 返回:如果操作成功———— C F = 0 CF=0 CF=0, a h = 00 H ah=00H ah=00H
这里我只挑了下文需要的介绍,更多内容可以参考这篇博客BIOS系统服务 —— 直接磁盘服务(int 0x13)
int 0x15
功能号 a h = 0 x 88 ah=0x88 ah=0x88,作用是获取系统所含扩展内存大小
- 输入:ah = 0x88
- 返回:ax = 从0x100000(1M)处开始的拓展内存大小(KB)。若出错则CF置位,ax = 出错码。
int 0x41
在PC机中BIOS设定的中断向量表中int 0x41的中断向量位置 (
4
∗
0
x
41
=
0
x
0000
:
0
x
0104
4*0x41 = 0x0000:0x0104
4∗0x41=0x0000:0x0104)存放的并不是中断程序的地址,而是第一个硬盘的基本参数表。对于100%兼容的BIOS来说,这里存放着硬盘参数表阵列的首地址0xF000:0E401,第二个硬盘的基本参数表入口地址存于int 0x46中断向量位置处.每个硬盘参数表有16个字节大小.
| 位移 | 大小 | 说明 |
|---|---|---|
| 0x00 | 字 | 柱面数 |
| 0x02 | 字节 | 磁头数 |
| … | … | … |
| 0x0E | 字节 | 每磁道扇区数 |
| 0x0F | 字节 | 保留 |
CF
要了解CF,首先要知道寄存器中有一种特殊的寄存器————标志寄存器,其中存储的信息通常被称为程序状态字。以下简称为flag寄存器。
flag和其他寄存器不一样,其他寄存器是用来存放数据的,都是整个寄存器具有一个含义。而flag寄存器是按位起作用的,也就是说,它的每一位都有专门的含义,记录特定的信息。
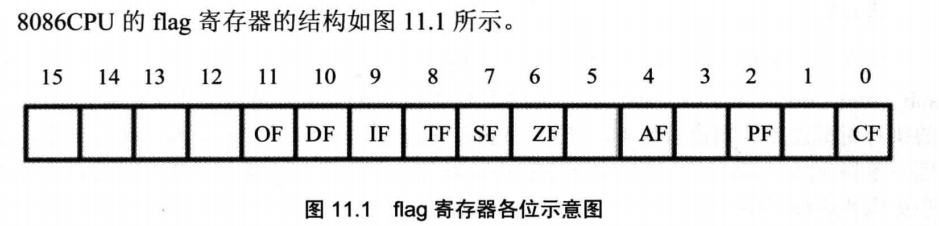
flag的1、3、5、12、13、14、15位在8086CPU中没有使用,不具有任何含义。而0、2、4、6、7、8、9、10、11位都具有特殊的含义。
CF就是flag的第0位————进位标志位。在进行无符号数运算的时候,它记录了运算结果的最高有效位向更高位的进位值,或从更高位的借位值。
jnc
在 C F = 0 CF=0 CF=0 的时候,进行跳转,即不进位则跳转,下文就是在读入没有出错时,跳转到ok_load_setup
jl
小于则跳转
lds
格式: LDS reg16,mem32
其意义是同时给一个段寄存器和一个16位通用寄存器同时赋值
举例:
| 地址 | 100H | 101H | 102H | 103H |
|---|---|---|---|---|
| 内容 | 00H | 41H | 02H | 03H |
LDS AX,[100H]
! 结果:AX=4100H DS=0302H
可以把上述代码理解为这样一个过程,但实际上不能这么写
mov AX,[100H]
mov DS,[100H+2]
即把低字(2B)置为偏移地址,高字(2B)置为段地址
DF标志和串传送指令
flag的第10位是DF,方向标志位。在串处理指令中,控制每次操作后si、di的增减。
- df=0:每次操作后si、di递增
- df=1:每次操作后si、di递减
来看一个串传送指令
-
格式:movsb
-
功能:相当于执行了如下2步操作
-
( ( e s ) ∗ 16 + ( d i ) ) = ( ( d s ) ∗ 16 + s i ) ((es)*16+(di))=((ds)*16+si) ((es)∗16+(di))=((ds)∗16+si)
-
如果df=0:(si)=(si)+1,(di)=(di)+1
如果df=1:(si)=(si)-1,(di)=(di)-1
-
可以看出,movsb的功能是将 d s : s i ds:si ds:si 指向的内存单元中的字节送入 e s : d i es:di es:di中,然后根据标志寄存器df位的值,将si和di递增或递减。
也可以传送一个字
-
格式:movsw
-
功能:相当于执行了如下2步操作
-
( ( e s ) ∗ 16 + ( d i ) ) = ( ( d s ) ∗ 16 + s i ) ((es)*16+(di))=((ds)*16+si) ((es)∗16+(di))=((ds)∗16+si)
-
如果df=0:(si)=(si)+2,(di)=(di)+2
如果df=1:(si)=(si)-2,(di)=(di)-2
-
可以看出,movsw的功能是将 d s : s i ds:si ds:si 指向的内存单元中的字节送入 e s : d i es:di es:di中,然后根据标志寄存器df位的值, 将si和di递增2或递减2。
movsb和movsw进行的是串传送操作的一个步骤,一般配合rep使用
格式如下:rep movsb
用汇编语法描述:
s:movsb
loop s
可见rep的作用是根据cx的值,重复执行串传送指令。由于每执行一次movsb指令si和di都会递增或递减指向后面一个单元或前面一个单元,则 rep movsb就可以循环实现(cx)个字符的传送。
call
(1) 将当前IP或CS和IP压入栈中
(2) 转移
CPU执行“call 标号”时,相当于进行:
push IP
jmp near ptr 标号
ret
ret指令用栈中的数据,修改IP的内容,从而实现近转移
(1) ( I P ) = ( ( s s ) ∗ 16 + ( s p ) ) (IP)=((ss)*16+(sp)) (IP)=((ss)∗16+(sp))
(2) ( s p ) = ( s p ) + 2 (sp)=(sp)+2 (sp)=(sp)+2
CPU执行ret指令时,相当于进行:
pop IP
改写bootsect.s
打开 bootsect.s
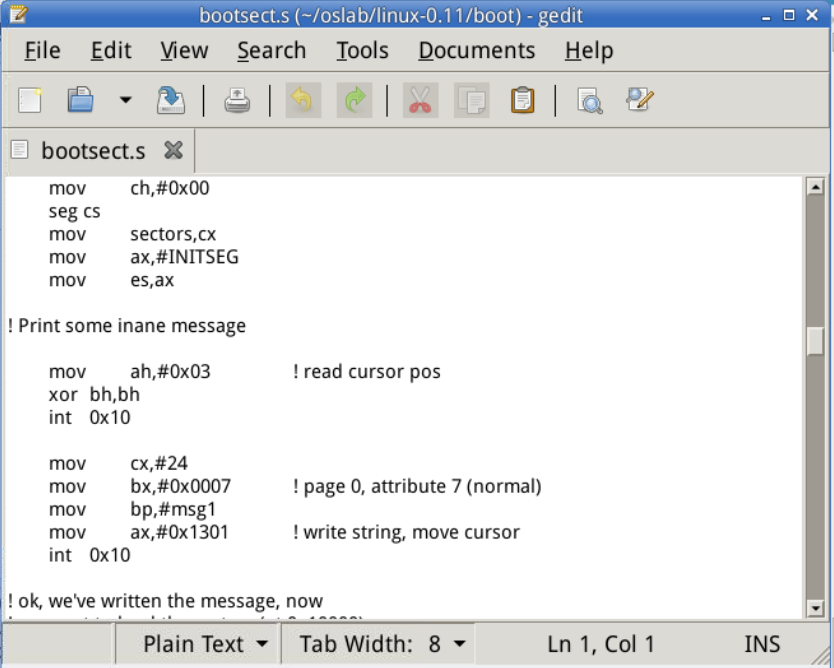
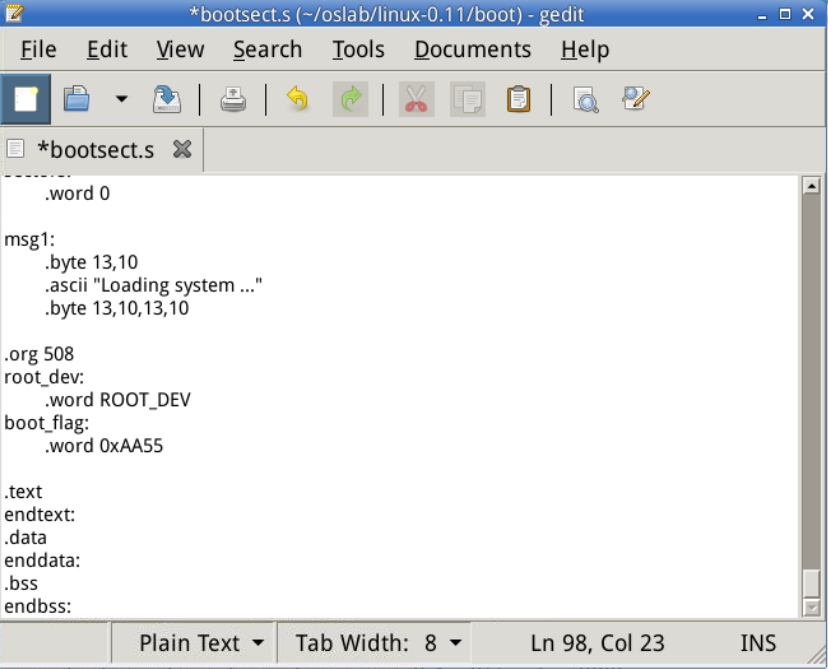
Loading system ...就是开机时显示在屏幕上的字,共16字符,加上3个换行+回车,一共是24字符。我将要修改他为Hello OS world,my name is WCF,30字符,加上3个换行+回车,共36字符。所以图一代码修改为mov cx.#36。
将 .org 508 修改为 .org 510,是因为这里不需要 root_dev: .word ROOT_DEV,为了保证 boot_flag 一定在引导扇区最后两个字节,所以要修改 .org。.org 510 表示下面语句从地址510(0x1FE)开始,用来强制要求boot_flag一定在引导扇区的最后2个字节中(第511和512字节)。
完整的代码如下:
entry _start
_start:
mov ah,#0x03 ! 设置功能号
xor bh,bh ! 将bh置0
int 0x10 ! 返回行号和列号,供显示串用
mov cx,#52 !要显示的字符串长度
mov bx,#0x0007 ! bh=0,bl=07(正常的黑底白字)
mov bp,#msg1 ! es:bp 要显示的字符串物理地址
mov ax,#0x07c0 ! 将es段寄存器置为#0x07c0
mov es,ax
mov ax,#0x1301 ! ah=13(设置功能号),al=01(目标字符串仅仅包含字符,属性在BL中包含,光标停在字符串结尾处)
int 0x10 ! 显示字符串
! 设置一个无限循环(纯粹为了能一直看到字符串显示)
inf_loop:
jmp inf_loop
! 字符串信息
msg1:
.byte 13,10 ! 换行+回车
.ascii "Welcome to the world without assembly language"
.byte 13,10,13,10 ! 换行+回车
! 将
.org 510
! 启动盘具有有效引导扇区的标志。仅供BIOS中的程序加载引导扇区时识别使用。它必须位于引导扇区的最后两个字节中
boot_flag:
.word 0xAA55
Ubuntu 上先从终端进入 ~/oslab/linux-0.11/boot/目录
执行下面两个命令编译和链接 bootsect.s:
$ as86 -0 -a -o bootsect.o bootsect.s
$ ld86 -0 -s -o bootsect bootsect.o

其中
bootsect.o 是中间文件。bootsect 是编译、链接后的目标文件。
需要留意的文件是 bootsect 的文件大小是 544 字节,而引导程序必须要正好占用一个磁盘扇区,即 512 个字节。造成多了 32 个字节的原因是 ld86 产生的是 Minix 可执行文件格式,这样的可执行文件处理文本段、数据段等部分以外,还包括一个 Minix 可执行文件头部,它的结构如下:
struct exec {
unsigned char a_magic[2]; //执行文件魔数
unsigned char a_flags;
unsigned char a_cpu; //CPU标识号
unsigned char a_hdrlen; //头部长度,32字节或48字节
unsigned char a_unused;
unsigned short a_version;
long a_text; long a_data; long a_bss; //代码段长度、数据段长度、堆长度
long a_entry; //执行入口地址
long a_total; //分配的内存总量
long a_syms; //符号表大小
};
6 char(6 字节)+ 1 short(2 字节) + 6 long(24 字节)= 32,正好是 32 个字节,去掉这 32 个字节后就可以放入引导扇区了。
对于上面的 Minix 可执行文件,其 a_magic[0]=0x01,a_magic[1]=0x03,a_flags=0x10(可执行文件),a_cpu=0x04(表示 Intel i8086/8088,如果是 0x17 则表示 Sun 公司的 SPARC),所以 bootsect 文件的头几个字节应该是 01 03 10 04。为了验证一下,Ubuntu 下用命令hexdump -C bootsect可以看到:
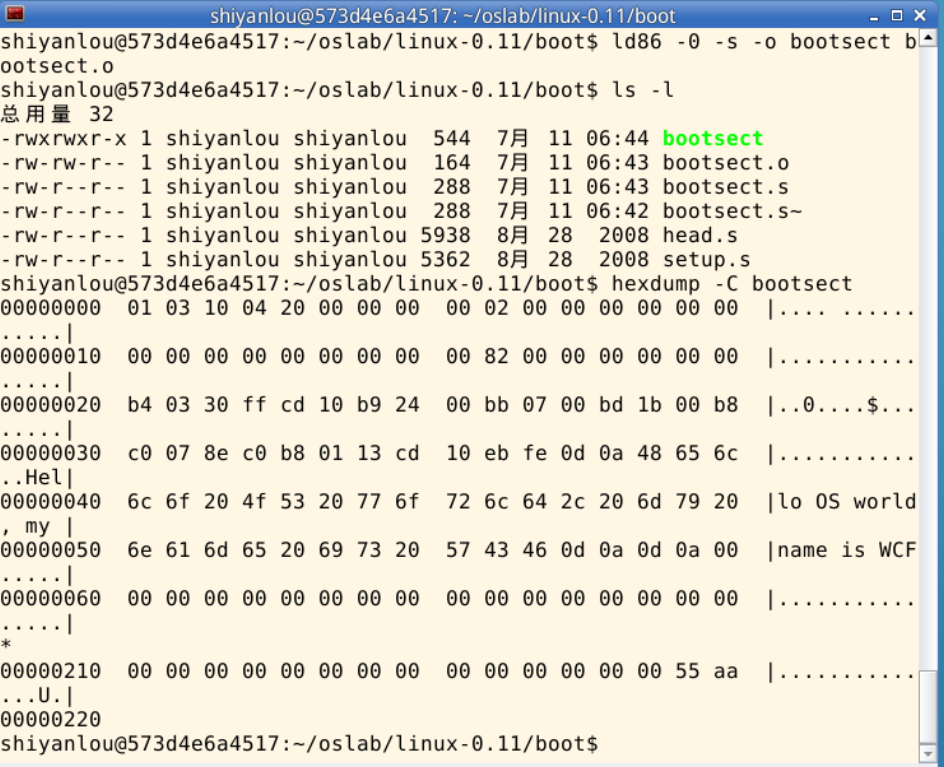
去掉这 32 个字节的文件头部
$ dd bs=1 if=bootsect of=Image skip=32
生成的 Image 就是去掉文件头的 bootsect。
去掉这 32 个字节后,将生成的文件拷贝到 linux-0.11 目录下,并一定要命名为“Image”(注意大小写)。然后就“run”吧!
# 当前的工作路径为 /oslab/linux-0.11/boot/
# 将刚刚生成的 Image 复制到 linux-0.11 目录下
$ cp ./Image ../Image
# 执行 oslab 目录中的 run 脚本
$ ../../run
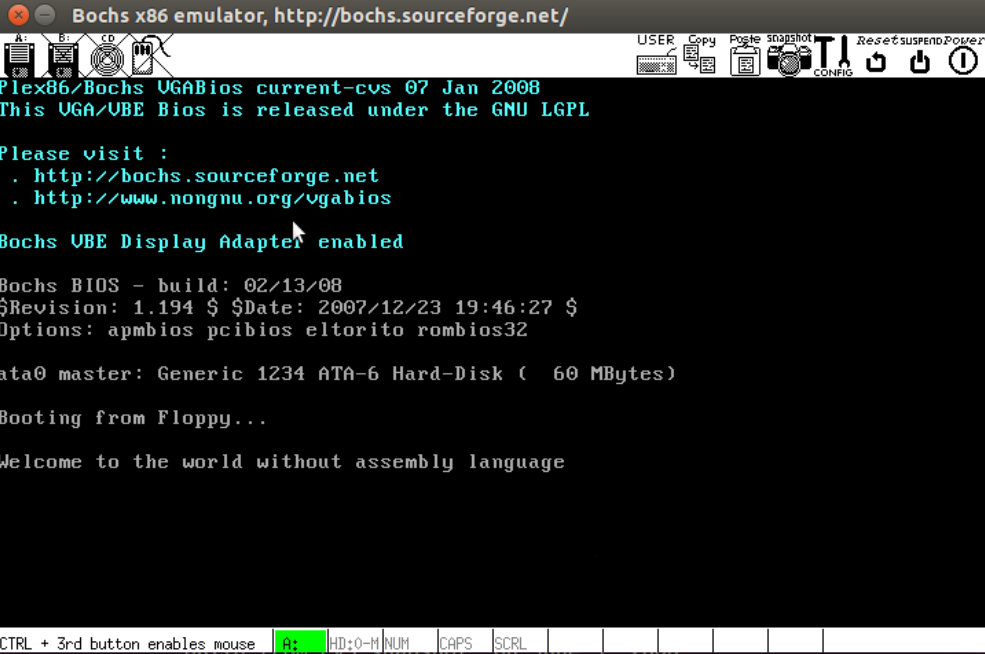
bootsect.s读入setup.s
首先编写一个 setup.s,该 setup.s 可以就直接拷贝前面的 bootsect.s(还需要简单的调整),然后将其中的显示的信息改为:“Now we are in SETUP”。
和前面基本一样,就不注释了。
entry _start
_start:
mov ah,#0x03
xor bh,bh
int 0x10
mov cx,#25
mov bx,#0x0007
mov bp,#msg2
mov ax,cs ! 这里的cs其实就是这段代码的段地址
mov es,ax
mov ax,#0x1301
int 0x10
inf_loop:
jmp inf_loop
msg2:
.byte 13,10
.ascii "Now we are in SETUP"
.byte 13,10
.org 510
boot_flag:
.word 0xAA55
接下来需要编写 bootsect.s 中载入 setup.s 的关键代码
所有需要的功能在原版 bootsect.s 中都是存在的,我们要做的仅仅是将这些代码添加到新的 bootsect.s 中去。
除了新增代码,我们还需要去掉在 bootsect.s 添加的无限循环。
SETUOLEN=2 ! 读入的扇区数
SETUPSEG=0x07e0 ! setup代码的段地址
entry _start
_start:
mov ah,al=01(目标字符串仅仅包含字符,属性在BL中包含,光标停在字符串结尾处)
int 0x10 ! 显示字符串
! 将setup模块从磁盘的第二个扇区开始读到0x7e00
load_setup:
mov dx,#0x0000 ! 磁头=0;驱动器号=0
mov cx,#0x0002 ! 磁道=0;扇区=2
mov bx,#0x0200 ! 偏移地址
mov ax,#0x0200+SETUPLEN ! 设置功能号;需要读出的扇区数量
int 0x13 ! 读磁盘扇区到内存
jnc ok_load_setup ! CF=0(读入成功)跳转到ok_load_setup
mov dx,#0x0000 ! 如果读入失败,使用功能号ah=0x00————磁盘系统复位
mov ax,#0x0000
int 0x13
jmp load_setup ! 尝试重新读入
ok_load_setup:
jmpi 0,SETUPSEG ! 段间跳转指令,跳转到setup模块处(0x07e0:0000)
! 字符串信息
msg1:
.byte 13,10 ! 换行+回车
! 将
.org 510
! 启动盘具有有效引导扇区的标志。仅供BIOS中的程序加载引导扇区时识别使用。它必须位于引导扇区的最后两个字节中
boot_flag:
.word 0xAA55
再次编译
$ make BootImage
有 Error!这是因为 make 根据 Makefile 的指引执行了 tools/build.c,它是为生成整个内核的镜像文件而设计的,没考虑我们只需要 bootsect.s 和 setup.s 的情况。它在向我们要 “系统” 的核心代码。为完成实验,接下来给它打个小补丁。c
build.c 从命令行参数得到 bootsect、setup 和 system 内核的文件名,将三者做简单的整理后一起写入 Image。其中 system 是第三个参数(argv[3])。当 “make all” 或者 “makeall” 的时候,这个参数传过来的是正确的文件名,build.c 会打开它,将内容写入 Image。而 “make BootImage” 时,传过来的是字符串 “none”。所以,改造 build.c 的思路就是当 argv[3] 是"none"的时候,只写 bootsect 和 setup,忽略所有与 system 有关的工作,或者在该写 system 的位置都写上 “0”。
修改工作主要集中在 build.c 的尾部,可长度以参考下面的方式,将圈起来的部分注释掉。
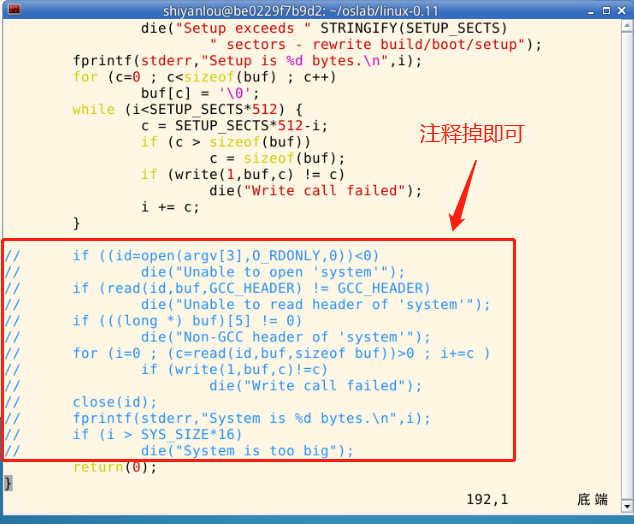
重新编译
$ cd ~/oslab/linux-0.11
$ make BootImage
$ ../run
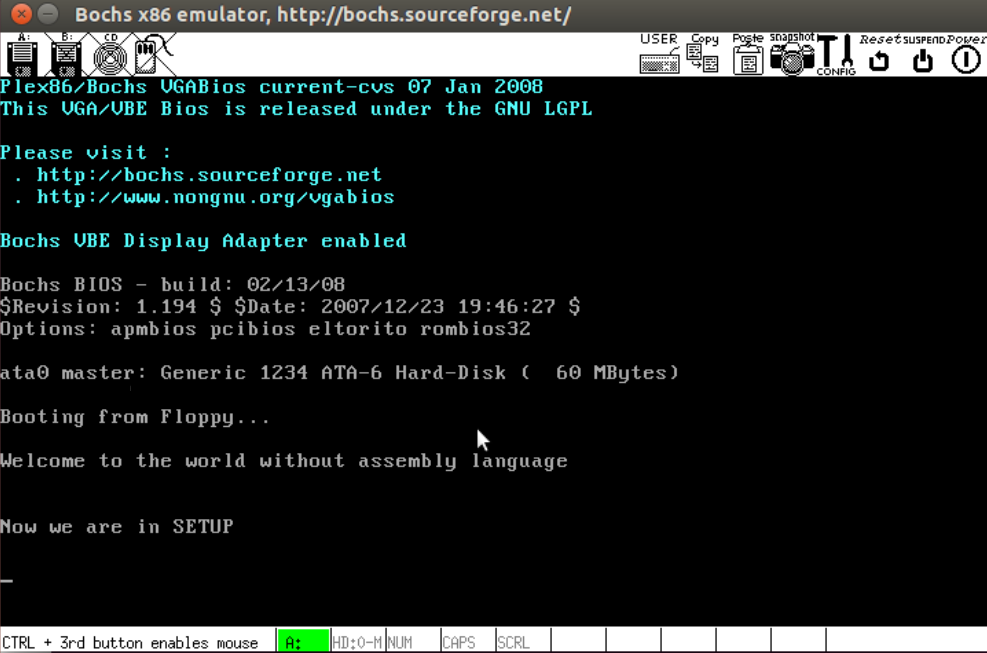
setup.s获取基本硬件参数
这里把一些难以理解的代码单独列出来
- 获得磁盘参数
这里花了我很长时间,原因是概念没有搞清楚,我觉得老师在实验指导书上写的也不是很清楚,CSDN上都只是草草复制的代码,感觉他们可以压根没有理解这一段。
先来回顾一下上文的一个概念:int 0x41
在PC机中BIOS设定的中断向量表中int 0x41的中断向量位置 (
4
∗
0
x
41
=
0
x
0000
:
0
x
0104
4*0x41 = 0x0000:0x0104
4∗0x41=0x0000:0x0104)存放的并不是中断程序的地址,这里存放着硬盘参数表阵列的首地址0xF000:0E401,第二个硬盘的基本参数表入口地址存于int 0x46中断向量位置处.每个硬盘参数表有16个字节大小.
这段话是重点,我之前误理解为磁盘参数就存放在以0x0000:0x0104为首地址的单元中,总共占16个字节,但实际上,只存了4个字节,里面存放的是磁盘参数表的偏移地址和段地址,也就是上文所说这里存放着硬盘参数表阵列的首地址0xF000:0E401。
lds si,[4*0x41]
再看这行代码就可以理解了,这里是把0x0000:0x0104单元存放的值(表示硬盘参数表阵列的首地址的偏移地址)赋给si寄存器,把0x0000:0x0106单元存放的值(表示硬盘参数表阵列的首地址的段地址)赋给ds寄存器。
- 参数以十六进制方式显示
先说说浪费我很长时间的我的错误:我想的是一个ASCII码8位,为什么答案里是4位4位输出,这里是搞清楚显示的目的。显示的是存在内存单元里的16进制数,例如某个字(2个字节)中的数值为 019 A 019A 019A,我所要显示的不是01和9A表示的ASCII码,而是显示019A本身,所以要4位4位显示。
以十六进制方式显示比较简单。这是因为十六进制与二进制有很好的对应关系(每 4 位二进制数和 1 位十六进制数存在一一对应关系),显示时只需将原二进制数每 4 位划成一组,按组求对应的 ASCII 码送显示器即可。ASCII 码与十六进制数字的对应关系为:0x30 ~ 0x39 对应数字 0 ~ 9,0x41 ~ 0x46 对应数字 a ~ f。从数字 9 到 a,其 ASCII 码间隔了 7h,这一点在转换时要特别注意。为使一个十六进制数能按高位到低位依次显示,实际编程中,需对 bx 中的数每次循环左移一组(4 位二进制),然后屏蔽掉当前高 12 位,对当前余下的 4 位(即 1 位十六进制数)求其 ASCII 码,要判断它是 0 ~ 9 还是 a ~ f,是前者则加 0x30 得对应的 ASCII 码,后者则要加 0x37 才行,最后送显示器输出。以上步骤重复 4 次,就可以完成 bx 中数以 4 位十六进制的形式显示出来。
下面是提供的参考代码
INITSEG = 0x9000 ! 参数存放位置的段地址
entry _start
_start:
! 打印 "NOW we are in SETUP"
mov ah,#0x03
xor bh,bh
int 0x10
mov cx,#25
mov bx,#0x0007
mov bp,#msg2
mov ax,cs
mov es,ax
mov ax,#0x1301
int 0x10
! 获取光标位置
mov ax,#INITSEG
mov ds,ax
mov ah,bh
int 0x10 ! 返回:dh = 行号;dl = 列号
mov [0],dx ! 存储到内存0x9000:0处
! 获取内存大小
mov ah,#0x88
int 0x15 ! 返回:ax = 从0x100000(1M)处开始的扩展内存大小(KB)
mov [2],ax ! 将扩展内存数值存放在0x90002处(1个字)
! 读第一个磁盘参数表复制到0x90004处
mov ax,#0x0000
mov ds,ax
lds si,[4*0x41] ! 把低字(2B)置为偏移地址,高字(2B)置为段地址
mov ax,#INITSEG
mov es,ax
mov di,#0x0004
mov cx,#0x10 ! 重复16次,即传送16B
rep
movsb ! 按字节传送
! 打印前的准备
mov ax,ax
! 打印"Cursor position:"
mov ah,#18
mov bx,#msg_cursor
mov ax,#0x1301
int 0x10
! 打印光标位置
mov dx,[0]
call print_hex
! 打印"Memory Size:"
mov ah,#14
mov bx,#msg_memory
mov ax,#0x1301
int 0x10
! 打印内存大小
mov dx,[2]
call print_hex
! 打印"KB"
mov ah,#2
mov bx,#msg_kb
mov ax,#0x1301
int 0x10
! 打印"Cyls:"
mov ah,#7
mov bx,#msg_cyles
mov ax,#0x1301
int 0x10
! 打印柱面数
mov dx,[4]
call print_hex
! 打印"Heads:"
mov ah,#8
mov bx,#msg_heads
mov ax,#0x1301
int 0x10
! 打印磁头数
mov dx,[6]
call print_hex
! 打印"Sectors:"
mov ah,#10
mov bx,#msg_sectors
mov ax,#0x1301
int 0x10
mov dx,[18]
call print_hex
inf_loop:
jmp inf_loop
! 上面的call都转到这里
print_hex:
mov cx,#4 ! dx(16位)可以显示4个十六进制数字
print_digit:
rol dx,#4 ! 取 dx 的高4比特移到低4比特处
mov ax,#0xe0f ! ah = 请求的功能值(显示单个字符),al = 半字节(4个比特)掩码
and al,dl ! 前4位会被置为0
add al,#0x30 ! 给 al 数字加上十六进制 0x30
cmp al,#0x3a ! 比较看是否大于数字十
jl outp ! 是一个不大于十的数字则跳转
add al,#0x07 ! 否则就是a~f,要多加7
outp:
int 0x10 ! 显示单个字符
loop print_digit ! 重复4次
ret
! 打印换行回车
print_nl:
mov ax,#0xe0d ! CR
int 0x10
mov al,#0xa ! LF
int 0x10
ret
msg2:
.byte 13,10
.ascii "NOW we are in SETUP"
.byte 13,10
msg_cursor:
.byte 13,10
.ascii "Cursor position:"
msg_memory:
.byte 13,10
.ascii "Memory Size:"
msg_cyles:
.byte 13,10
.ascii "Cyls:"
msg_heads:
.byte 13,10
.ascii "Heads:"
msg_sectors:
.byte 13,10
.ascii "Sectors:"
msg_kb:
.ascii "KB"
.org 510
boot_flag:
.word 0xAA55
经过漫长的调试,得到如下结果
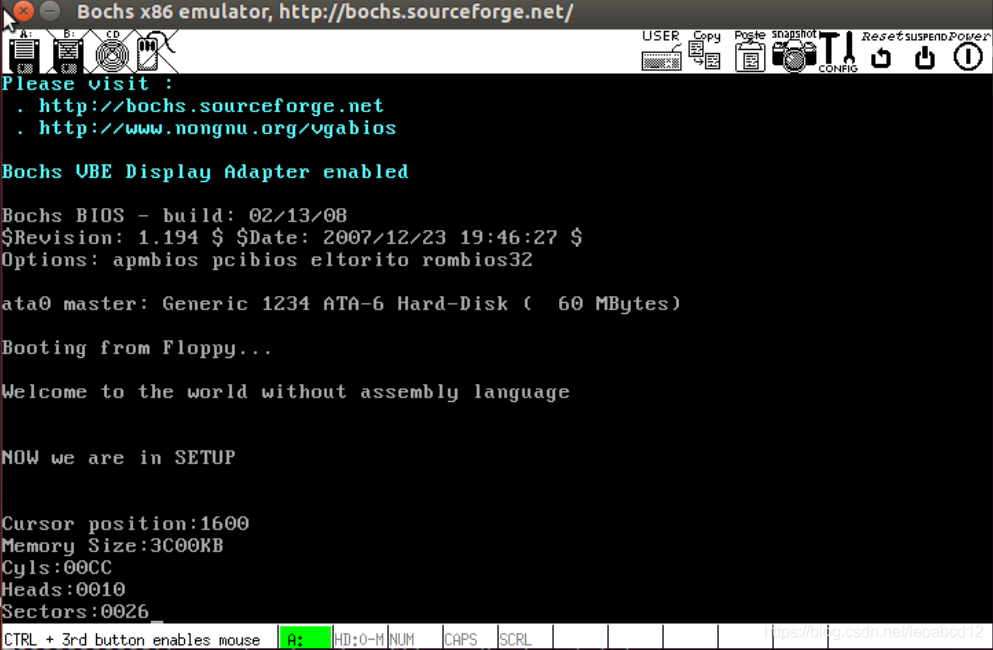
Memory Size 是 0x3C00KB,算一算刚好是 15MB(扩展内存),加上 1MB 正好是 16MB,看看 Bochs 配置文件 bochs/bochsrc.bxrc:

这些都和上面打出的参数吻合,表示此次实验是成功的。
天道酬勤
实验二总共花费25小时,因为没有汇编基础,花费了大量时间在理解代码上,希望下面的实验可以越做越快吧。
实验三 系统调用
提醒
这次实验涉及的宏过于复杂,加上本人能力有限,我也没有花大量时间去研究每一段代码,只是理解到每一段代码做了什么这一程度。
实验目的
此次实验的基本内容是:在 Linux 0.11 上添加两个系统调用,并编写两个简单的应用程序测试它们。
-
iam()
第一个系统调用是 iam(),其原型为:
int iam(const char * name);完成的功能是将字符串参数
name的内容拷贝到内核中保存下来。要求name的长度不能超过 23 个字符。返回值是拷贝的字符数。如果name的字符个数超过了 23,则返回 “-1”,并置 errno 为 EINVAL。 -
whoami()
第二个系统调用是 whoami(),其原型为:
int whoami(char* name, unsigned int size);它将内核中由
iam()保存的名字拷贝到 name 指向的用户地址空间中,同时确保不会对name越界访存(name的大小由size说明)。返回值是拷贝的字符数。如果size小于需要的空间,则返回“-1”,并置 errno 为 EINVAL。
应用程序如何调用系统调用
在通常情况下,调用系统调用和调用一个普通的自定义函数在代码上并没有什么区别,但调用后发生的事情有很大不同。
调用自定义函数是通过 call 指令直接跳转到该函数的地址,继续运行。
而调用系统调用,是调用系统库中为该系统调用编写的一个接口函数,叫 API(Application Programming Interface)。API 并不能完成系统调用的真正功能,它要做的是去调用真正的系统调用,过程是:
- 把系统调用的编号存入 EAX;
- 把函数参数存入其它通用寄存器;
- 触发 0x80 号中断(int 0x80)。
linux-0.11 的 lib 目录下有一些已经实现的 API。Linus 编写它们的原因是在内核加载完毕后,会切换到用户模式下,做一些初始化工作,然后启动 shell。而用户模式下的很多工作需要依赖一些系统调用才能完成,因此在内核中实现了这些系统调用的 API。
我们不妨看看 lib/close.c,研究一下 close() 的 API:
#define __LIBRARY__
#include <unistd.h>
_syscall1(int, close, int, fd)
其中 _syscall1 是一个宏,在 include/unistd.h 中定义。
#define _syscall1(type,name,atype,a) \
type name(atype a) \
{ \
long __res; \
__asm__ volatile ("int $0x80" \
: "=a" (__res) \
: "0" (__NR_##name),"b" ((long)(a))); \
if (__res >= 0) \
return (type) __res; \
errno = -__res; \
return -1; \
}
将 _syscall1(int,close,int,fd) 进行宏展开,可以得到:
int close(int fd)
{
long __res;
__asm__ volatile ("int $0x80"
: "=a" (__res)
: "0" (__NR_close),"b" ((long)(fd)));
if (__res >= 0)
return (int) __res;
errno = -__res;
return -1;
}
这就是 API 的定义。它先将宏 __NR_close 存入 EAX,将参数 fd 存入 EBX,然后进行 0x80 中断调用。调用返回后,从 EAX 取出返回值,存入 __res,再通过对 __res 的判断决定传给 API 的调用者什么样的返回值。
其中 __NR_close 就是系统调用的编号,在 include/unistd.h 中定义:
#define __NR_close 6
/*
所以添加系统调用时需要修改include/unistd.h文件,
使其包含__NR_whoami和__NR_iam。
*/
/*
而在应用程序中,要有:
*/
/* 有它,_syscall1 等才有效。详见unistd.h */
#define __LIBRARY__
/* 有它,编译器才能获知自定义的系统调用的编号 */
#include "unistd.h"
/* iam()在用户空间的接口函数 */
_syscall1(int, iam, const char*, name);
/* whoami()在用户空间的接口函数 */
_syscall2(int, whoami,char*,unsigned int,size);
在 0.11 环境下编译 C 程序,包含的头文件都在 /usr/include 目录下。
该目录下的 unistd.h 是标准头文件(它和 0.11 源码树中的 unistd.h 并不是同一个文件,虽然内容可能相同),没有 __NR_whoami 和 __NR_iam 两个宏,需要手工加上它们,也可以直接从修改过的 0.11 源码树中拷贝新的 unistd.h 过来。
从“int 0x80”进入内核函数
int 0x80 触发后,接下来就是内核的中断处理了。先了解一下 0.11 处理 0x80 号中断的过程。
在内核初始化时,主函数在 init/main.c 中,调用了 sched_init() 初始化函数:
void main(void)
{
// ……
time_init();
sched_init();
buffer_init(buffer_memory_end);
// ……
}
sched_init() 在 kernel/sched.c 中定义为:
void sched_init(void)
{
// ……
set_system_gate(0x80,&system_call);
}
set_system_gate 是个宏,在 include/asm/system.h 中定义为:
#define set_system_gate(n,addr) \
_set_gate(&idt[n],15,3,addr)
_set_gate 的定义是:
#define _set_gate(gate_addr,type,dpl,addr) \
__asm__ ("movw %%dx,%%ax\n\t" \
"movw %0,%%dx\n\t" \
"movl %%eax,%1\n\t" \
"movl %%edx,%2" \
: \
: "i" ((short) (0x8000+(dpl<<13)+(type<<8))), \
"o" (*((char *) (gate_addr))), \
"o" (*(4+(char *) (gate_addr))), \
"d" ((char *) (addr)),"a" (0x00080000))
虽然看起来挺麻烦,但实际上很简单,就是填写 IDT(中断描述符表),将 system_call 函数地址写到 0x80 对应的中断描述符中,也就是在中断 0x80 发生后,自动调用函数 system_call。
接下来看 system_call。该函数纯汇编打造,定义在 kernel/system_call.s 中:
!……
! # 这是系统调用总数。如果增删了系统调用,必须做相应修改
nr_system_calls = 72
!……
.globl system_call
.align 2
system_call:
! # 检查系统调用编号是否在合法范围内
cmpl \$nr_system_calls-1,%eax
ja bad_sys_call
push %ds
push %es
push %fs
pushl %edx
pushl %ecx
! # push %ebx,%ecx,%edx,是传递给系统调用的参数
pushl %ebx
! # 让ds,es指向GDT,内核地址空间
movl $0x10,%edx
mov %dx,%ds
mov %dx,%es
movl $0x17,%edx
! # 让fs指向LDT,用户地址空间
mov %dx,%fs
call sys_call_table(,%eax,4)
pushl %eax
movl current,%eax
cmpl $0,state(%eax)
jne reschedule
cmpl $0,counter(%eax)
je reschedule
system_call 用 .globl 修饰为其他函数可见。
call sys_call_table(,4) 之前是一些压栈保护,修改段选择子为内核段,call sys_call_table(,4) 之后是看看是否需要重新调度,这些都与本实验没有直接关系,此处只关心 call sys_call_table(,4) 这一句。
根据汇编寻址方法它实际上是:call sys_call_table + 4 * %eax,其中 eax 中放的是系统调用号,即 __NR_xxxxxx。
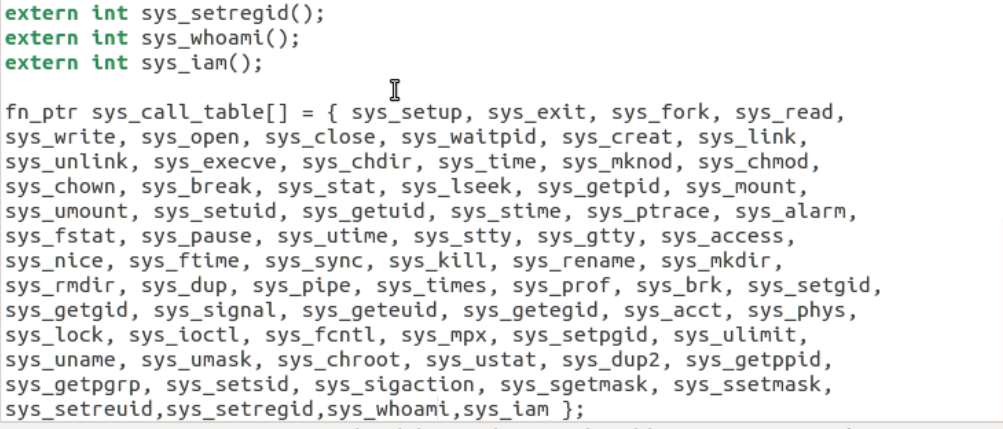
显然,sys_call_table 一定是一个函数指针数组的起始地址,它定义在 include/linux/sys.h 中:
fn_ptr sys_call_table[] = { sys_setup,sys_exit,sys_fork,sys_read,...
增加实验要求的系统调用,需要在这个函数表中增加两个函数引用 ——sys_iam 和 sys_whoami。当然该函数在 sys_call_table 数组中的位置必须和 __NR_xxxxxx 的值对应上。
同时还要仿照此文件中前面各个系统调用的写法,加上:
extern int sys_whoami();
extern int sys_iam();
不然,编译会出错的。
实现 sys_iam() 和 sys_whoami()
添加系统调用的最后一步,是在内核中实现函数 sys_iam() 和 sys_whoami()。
每个系统调用都有一个 sys_xxxxxx() 与之对应,它们都是我们学习和模仿的好对象。
比如在 fs/open.c 中的 sys_close(int fd):
int sys_close(unsigned int fd)
{
// ……
return (0);
}
它没有什么特别的,都是实实在在地做 close() 该做的事情。
所以只要自己创建一个文件:kernel/who.c,然后实现两个函数就万事大吉了。
按照上述逻辑修改相应文件
通过上文描述,我们已经理清楚了要修改的地方在哪里
-
添加iam和whoami系统调用编号的宏定义(_NR_xxxxxx),文件:include/unistd.h

-
修改系统调用总数,文件:kernel/system_call.s

-
为新增的系统调用添加系统调用名并维护系统调用表,文件:include/linux/sys.h
-
为新增的系统调用编写代码实现,在linux-0.11/kernel目录下,创建一个文件
who.c#include <asm/segment.h> #include <errno.h> #include <string.h> char _myname[24]; int sys_iam(const char *name) { char str[25]; int i = 0; do { // get char from user input str[i] = get_fs_byte(name + i); } while (i <= 25 && str[i++] != '\0'); if (i > 24) { errno = EINVAL; i = -1; } else { // copy from user mode to kernel mode strcpy(_myname, str); } return i; } int sys_whoami(char *name, unsigned int size) { int length = strlen(_myname); printk("%s\n", _myname); if (size < length) { errno = EINVAL; length = -1; } else { int i = 0; for (i = 0; i < length; i++) { // copy from kernel mode to user mode put_fs_byte(_myname[i], name + i); } } return length; }
修改 Makefile
要想让我们添加的 kernel/who.c 可以和其它 Linux 代码编译链接到一起,必须要修改 Makefile 文件。
Makefile 里记录的是所有源程序文件的编译、链接规则,《注释》3.6 节有简略介绍。我们之所以简单地运行 make 就可以编译整个代码树,是因为 make 完全按照 Makefile 里的指示工作。
Makefile 在代码树中有很多,分别负责不同模块的编译工作。我们要修改的是 kernel/Makefile。需要修改两处。
(1)第一处
OBJS = sched.o system_call.o traps.o asm.o fork.o \
panic.o printk.o vsprintf.o sys.o exit.o \
signal.o mktime.o
改为:
OBJS = sched.o system_call.o traps.o asm.o fork.o \
panic.o printk.o vsprintf.o sys.o exit.o \
signal.o mktime.o who.o
添加了 who.o。

(2)第二处
### Dependencies:
exit.s exit.o: exit.c ../include/errno.h ../include/signal.h \
../include/sys/types.h ../include/sys/wait.h ../include/linux/sched.h \
../include/linux/head.h ../include/linux/fs.h ../include/linux/mm.h \
../include/linux/kernel.h ../include/linux/tty.h ../include/termios.h \
../include/asm/segment.h
改为:
### Dependencies:
who.s who.o: who.c ../include/linux/kernel.h ../include/unistd.h
exit.s exit.o: exit.c ../include/errno.h ../include/signal.h \
../include/sys/types.h ../include/sys/wait.h ../include/linux/sched.h \
../include/linux/head.h ../include/linux/fs.h ../include/linux/mm.h \
../include/linux/kernel.h ../include/linux/tty.h ../include/termios.h \
../include/asm/segment.h
添加了 who.s who.o: who.c ../include/linux/kernel.h ../include/unistd.h。

Makefile 修改后,和往常一样 make all 就能自动把 who.c 加入到内核中了。
编写测试程序
到此为止,内核中需要修改的部分已经完成,接下来需要编写测试程序来验证新增的系统调用是否已经被编译到linux-0.11内核可供调用。首先在oslab目录下编写iam.c,whoami.c
/* iam.c */
#define __LIBRARY__
#include <unistd.h>
#include <errno.h>
#include <asm/segment.h>
#include <linux/kernel.h>
_syscall1(int, name);
int main(int argc, char *argv[])
{
/*调用系统调用iam()*/
iam(argv[1]);
return 0;
}
/* whoami.c */
#define __LIBRARY__
#include <unistd.h>
#include <errno.h>
#include <asm/segment.h>
#include <linux/kernel.h>
#include <stdio.h>
_syscall2(int,char *,size);
int main(int argc, char *argv[])
{
char username[64] = {0};
/*调用系统调用whoami()*/
whoami(username, 24);
printf("%s\n", username);
return 0;
}
以上两个文件需要放到启动后的linux-0.11操作系统上运行,验证新增的系统调用是否有效,那如何才能将这两个文件从宿主机转到稍后虚拟机中启动的linux-0.11操作系统上呢?这里我们采用挂载方式实现宿主机与虚拟机操作系统的文件共享,在 oslab 目录下执行以下命令挂载hdc目录到虚拟机操作系统上。
sudo ./mount-hdc
再通过以下命令将上述两个文件拷贝到虚拟机linux-0.11操作系统/usr/root/目录下,命令在oslab/目录下执行:
cp iam.c whoami.c hdc/usr/root
如果目标目录下存在对应的两个文件则可启动虚拟机进行测试了。
-
编译
[/usr/root]# gcc -o iam iam.c [/usr/root]# gcc -o whoami whoami.c -
运行测试
[/usr/root]# ./iam wcf [/usr/root]# ./whoami
命令执行后,很可能会报以下错误:
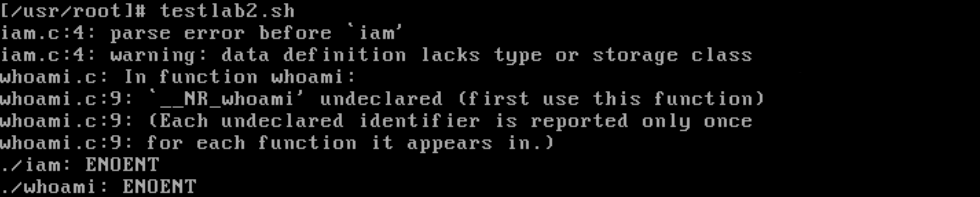
这代表虚拟机操作系统中/usr/include/unistd.h文件中没有新增的系统调用调用号
为新增系统调用设置调用号
#define __NR_whoami 72
#define __NR_iam 73
再次执行:

实验成功
-
为什么这里会打印2次?
-
因为在系统内核中执行了
printk()函数,在用户模式下又执行了一次printf()函数。
要知道到,printf() 是一个只能在用户模式下执行的函数,而系统调用是在内核模式中运行,所以 printf() 不可用,要用 printk()。
printk() 和 printf() 的接口和功能基本相同,只是代码上有一点点不同。printk() 需要特别处理一下 fs 寄存器,它是专用于用户模式的段寄存器。

天道酬勤
实验三总共花费7小时,看的不是特别仔细,没有特别深入的学习宏展开和内联汇编。但基本理解了系统调用的目的和方式,Linus永远的神!
实验四 进程运行轨迹的跟踪与统计
实验目的
- 掌握 Linux 下的多进程编程技术;
- 通过对进程运行轨迹的跟踪来形象化进程的概念;
- 在进程运行轨迹跟踪的基础上进行相应的数据统计,从而能对进程调度算法进行实际的量化评价,更进一步加深对调度和调度算法的理解,获得能在实际操作系统上对调度算法进行实验数据对比的直接经验。
实验内容
进程从创建(Linux 下调用 fork())到结束的整个过程就是进程的生命期,进程在其生命期中的运行轨迹实际上就表现为进程状态的多次切换,如进程创建以后会成为就绪态;当该进程被调度以后会切换到运行态;在运行的过程中如果启动了一个文件读写操作,操作系统会将该进程切换到阻塞态(等待态)从而让出 CPU;当文件读写完毕以后,操作系统会在将其切换成就绪态,等待进程调度算法来调度该进程执行……
本次实验包括如下内容:
- 基于模板
process.c编写多进程的样本程序,实现如下功能: + 所有子进程都并行运行,每个子进程的实际运行时间一般不超过 30 秒; + 父进程向标准输出打印所有子进程的 id,并在所有子进程都退出后才退出; - 在
Linux0.11上实现进程运行轨迹的跟踪。 + 基本任务是在内核中维护一个日志文件/var/process.log,把从操作系统启动到系统关机过程中所有进程的运行轨迹都记录在这一 log 文件中。 - 在修改过的 0.11 上运行样本程序,通过分析 log 文件,统计该程序建立的所有进程的等待时间、完成时间(周转时间)和运行时间,然后计算平均等待时间,平均完成时间和吞吐量。可以自己编写统计程序进行统计。
- 修改 0.11 进程调度的时间片,然后再运行同样的样本程序,统计同样的时间数据,和原有的情况对比,体会不同时间片带来的差异。
/var/process.log 文件的格式必须为:
pid X time
其中:
- pid 是进程的 ID;
- X 可以是 N、J、R、W 和 E 中的任意一个,分别表示进程新建(N)、进入就绪态(J)、进入运行态®、进入阻塞态(W) 和退出(E);
- time 表示 X 发生的时间。这个时间不是物理时间,而是系统的滴答时间(tick);
三个字段之间用制表符分隔。例如:
12 N 1056
12 J 1057
4 W 1057
12 R 1057
13 N 1058
13 J 1059
14 N 1059
14 J 1060
15 N 1060
15 J 1061
12 W 1061
15 R 1061
15 J 1076
14 R 1076
14 E 1076
......
编写process.c文件
提示
在 Ubuntu 下,top 命令可以监视即时的进程状态。在 top 中,按 u,再输入你的用户名,可以限定只显示以你的身份运行的进程,更方便观察。按 h 可得到帮助。
在 Ubuntu 下,ps 命令可以显示当时各个进程的状态。ps aux 会显示所有进程;ps aux | grep xxxx 将只显示名为 xxxx 的进程。更详细的用法请问 man。
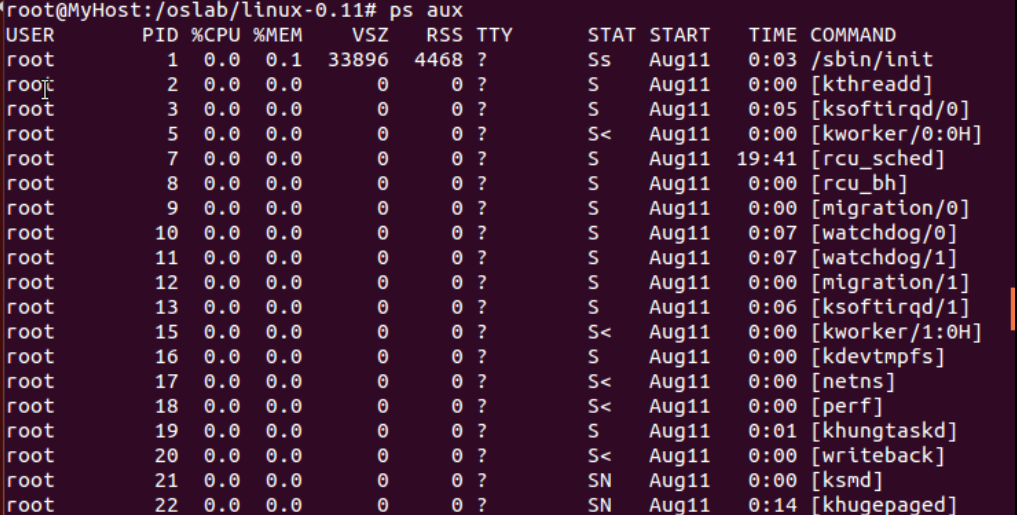
在 Linux 0.11 下,按 F1 可以即时显示当前所有进程的状态。

文件主要作用
process.c文件主要实现了一个函数:
/*
* 此函数按照参数占用CPU和I/O时间
* last: 函数实际占用CPU和I/O的总时间,不含在就绪队列中的时间,>=0是必须的
* cpu_time: 一次连续占用CPU的时间,>=0是必须的
* io_time: 一次I/O消耗的时间,>=0是必须的
* 如果last > cpu_time + io_time,则往复多次占用CPU和I/O,直到总运行时间超过last为止
* 所有时间的单位为秒
*/
cpuio_bound(int last, int cpu_time, int io_time);
下面是 4 个使用的例子:
// 比如一个进程如果要占用10秒的CPU时间,它可以调用:
cpuio_bound(10, 1, 0);
// 只要cpu_time>0,io_time=0,效果相同
// 以I/O为主要任务:
cpuio_bound(10, 0, 1);
// 只要cpu_time=0,io_time>0,效果相同
// CPU和I/O各1秒钟轮回:
cpuio_bound(10, 1);
// 较多的I/O,较少的CPU:
// I/O时间是CPU时间的9倍
cpuio_bound(10, 9);
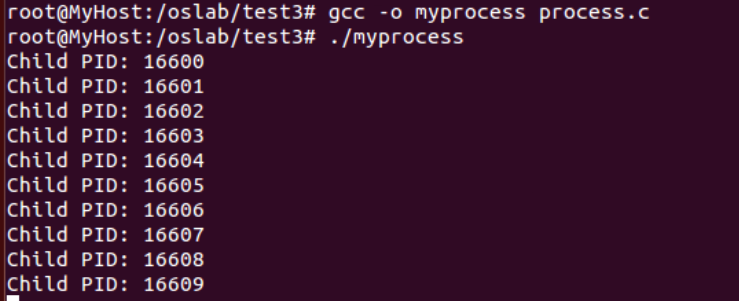
修改此模板,用 fork() 建立若干个同时运行的子进程,父进程等待所有子进程退出后才退出,每个子进程按照你的意愿做不同或相同的 cpuio_bound(),从而完成一个个性化的样本程序。
它可以用来检验有关 log 文件的修改是否正确,同时还是数据统计工作的基础。
wait() 系统调用可以让父进程等待子进程的退出。
关键函数解释
fork()
这里摘录某位博主的详解操作系统之 fork() 函数详解 - 简书 (jianshu.com)
fork()函数通过系统调用创建一个与原来进程几乎完全相同的进程,也就是两个进程可以做完全相同的事,但如果初始参数或者传入的变量不同,两个进程也可以做不同的事。
一个进程调用fork()函数后,系统先给新的进程分配资源,例如存储数据和代码的空间。然后把原来的进程的所有值都复制到新的新进程中,只有少数值与原来的进程的值不同。相当于克隆了一个自己。
#include <unistd.h>
#include <stdio.h>
int main ()
{
pid_t fpid; //fpid表示fork函数返回的值
int count=0;
fpid=fork();
if (fpid < 0)
printf("error in fork!");
else if (fpid == 0) {
printf("i am the child process,my process id is %d/n",getpid());
printf("我是爹的儿子/n");//对某些人来说中文看着更直白。
count++;
}
else {
printf("i am the parent process,getpid());
printf("我是孩子他爹/n");
count++;
}
printf("统计结果是: %d/n",count);
return 0;
}
运行结果:
i am the child process,my process id is 5574
我是爹的儿子
统计结果是: 1
i am the parent process,my process id is 5573
我是孩子他爹
统计结果是: 1
在语句fpid=fork()之前,只有一个进程在执行这段代码,但在这条语句之后,就变成两个进程在执行了,这两个进程的几乎完全相同,将要执行的下一条语句都是if(fpid<0)
为什么两个进程的fpid不同呢,这与fork函数的特性有关。fork调用的一个奇妙之处就是它仅仅被调用一次,却能够返回两次,它可能有三种不同的返回值:
1)在父进程中,fork返回新创建子进程的进程ID;
2)在子进程中,fork返回0;
3)如果出现错误,fork返回一个负值;
在fork函数执行完毕后,如果创建新进程成功,则出现两个进程,一个是子进程,一个是父进程。在子进程中,fork函数返回0,在父进程中,fork返回新创建子进程的进程ID。我们可以通过fork返回的值来判断当前进程是子进程还是父进程。
引用一位网友的话来解释fpid的值为什么在父子进程中不同。“其实就相当于链表,进程形成了链表,父进程的fpid(p 意味point)指向子进程的进程id,因为子进程没有子进程,所以其fpid为0.
fork出错可能有两种原因:
1)当前的进程数已经达到了系统规定的上限,这时errno的值被设置为EAGAIN。
2)系统内存不足,这时errno的值被设置为ENOMEM。
创建新进程成功后,系统中出现两个基本完全相同的进程,这两个进程执行没有固定的先后顺序,哪个进程先执行要看系统的进程调度策略。
每个进程都有一个独特(互不相同)的进程标识符(process ID),可以通过getpid()函数获得,还有一个记录父进程pid的变量,可以通过getppid()函数获得变量的值。
fork执行完毕后,出现两个进程
有人说两个进程的内容完全一样啊,怎么打印的结果不一样啊,那是因为判断条件的原因,上面列举的只是进程的代码和指令,还有变量啊。
执行完fork后,进程1的变量为count=0,fpid!=0(父进程)。进程2的变量为count=0,fpid=0(子进程),这两个进程的变量都是独立的,存在不同的地址中,不是共用的,这点要注意。可以说,我们就是通过fpid来识别和操作父子进程的。
还有人可能疑惑为什么不是从#include处开始复制代码的,这是因为fork是把进程当前的情况拷贝一份,执行fork时,进程已经执行完了int count=0;fork只拷贝下一个要执行的代码到新的进程。
struct tms 结构体
struct tms 结构体定义在 <sys/times.h> 头文件里,具体定义如下:
引用
/* Structure describing CPU time used by a process and its children. */
struct tms
{
clock_t tms_utime ; /* User CPU time. 用户程序 CPU 时间*/
clock_t tms_stime ; /* System CPU time. 系统调用所耗费的 CPU 时间 */
clock_t tms_cutime ; /* User CPU time of dead children. 已死掉子进程的 CPU 时间*/
clock_t tms_cstime ; /* System CPU time of dead children. 已死掉子进程所耗费的系统调用 CPU 时间*/
};
用户CPU时间和系统CPU时间之和为CPU时间,即命令占用CPU执行的时间总和。实际时间要大于CPU时间,因为Linux是多任务操作系统,往往在执行一条命令时,系统还要处理其他任务。另一个需要注意的问题是即使每次执行相同的命令,所花费的时间也不一定相同,因为其花费的时间与系统运行相关。
数据类型 clock_t
关于该数据类型的定义如下:
#ifndef _CLOCK_T_DEFINED
typedef long clock_t;
#define _CLOCK_T_DEFINED
#endif
clock_t 是一个长整型数。
在 time.h 文件中,还定义了一个常量 CLOCKS_PER_SEC ,它用来表示一秒钟会有多少个时钟计时单元,其定义如下:
#define CLOCKS_PER_SEC ((clock_t)1000)
下文就模拟cpu操作,定义 H Z = 100 HZ=100 HZ=100,内核的标准时间是jiffy,一个jiffy就是一个内部时钟周期,而内部时钟周期是由100HZ的频率所产生中的,也就是一个时钟滴答,间隔时间是10毫秒(ms).计算出来的时间也并非真实时间,而是时钟滴答次数,乘以10ms可以得到真正的时间。
代码实现
下面给出代码:
#include <stdio.h>
#include <unistd.h>
#include <time.h>
#include <sys/times.h>
#define HZ 100
void cpuio_bound(int last, int io_time);
int main(int argc, char * argv[])
{
pid_t n_proc[10]; /*10个子进程 PID*/
int i;
for(i=0;i<10;i++)
{
n_proc[i] = fork();
/*子进程*/
if(n_proc[i] == 0)
{
cpuio_bound(20,2*i,20-2*i); /*每个子进程都占用20s*/
return 0; /*执行完cpuio_bound 以后,结束该子进程*/
}
/*fork 失败*/
else if(n_proc[i] < 0 )
{
printf("Failed to fork child process %d!\n",i+1);
return -1;
}
/*父进程继续fork*/
}
/*打印所有子进程PID*/
for(i=0;i<10;i++)
printf("Child PID: %d\n",n_proc[i]);
/*等待所有子进程完成*/
wait(&i); /*Linux 0.11 上 gcc要求必须有一个参数,gcc3.4+则不需要*/
return 0;
}
/*
* 此函数按照参数占用CPU和I/O时间
* last: 函数实际占用CPU和I/O的总时间,不含在就绪队列中的时间,>=0是必须的
* cpu_time: 一次连续占用CPU的时间,>=0是必须的
* io_time: 一次I/O消耗的时间,>=0是必须的
* 如果last > cpu_time + io_time,则往复多次占用CPU和I/O
* 所有时间的单位为秒
*/
void cpuio_bound(int last, int io_time)
{
struct tms start_time, current_time;
clock_t utime, stime;
int sleep_time;
while (last > 0)
{
/* CPU Burst */
times(&start_time);
/* 其实只有t.tms_utime才是真正的CPU时间。但我们是在模拟一个
* 只在用户状态运行的CPU大户,就像“for(;;);”。所以把t.tms_stime
* 加上很合理。*/
do
{
times(¤t_time);
utime = current_time.tms_utime - start_time.tms_utime;
stime = current_time.tms_stime - start_time.tms_stime;
} while ( ( (utime + stime) / HZ ) < cpu_time );
last -= cpu_time;
if (last <= 0 )
break;
/* IO Burst */
/* 用sleep(1)模拟1秒钟的I/O操作 */
sleep_time=0;
while (sleep_time < io_time)
{
sleep(1);
sleep_time++;
}
last -= sleep_time;
}
}
答疑
❓ 为什么说它可以用来检验有关 log 文件的修改是否正确,同时还是数据统计工作的基础?
- 每个子进程都通过
cpuio_bound函数实现了占用CPU和I/O时间的操作,并且可以精确的知道每个操作的时间。所以下面的 log 文件(日志文件)正确与否可以借此推算。
尽早打开log文件
操作系统启动后先要打开 /var/process.log,然后在每个进程发生状态切换的时候向 log 文件内写入一条记录,其过程和用户态的应用程序没什么两样。然而,因为内核状态的存在,使过程中的很多细节变得完全不一样。
为了能尽早开始记录,应当在内核启动时就打开 log 文件。内核的入口是 init/main.c 中的 main(),其中一段代码是:
//……
move_to_user_mode();
if (!fork()) { /* we count on this going ok */
init();
}
//……
这段代码在进程 0 中运行,先切换到用户模式,然后全系统第一次调用 fork() 建立进程 1。进程 1 调用 init()。
在 init()中:
// ……
//加载文件系统
setup((void *) &drive_info);
// 打开/dev/tty0,建立文件描述符0和/dev/tty0的关联
(void) open("/dev/tty0",O_RDWR,0);
// 让文件描述符1也和/dev/tty0关联
(void) dup(0);
// 让文件描述符2也和/dev/tty0关联
(void) dup(0);
// ……
这段代码建立了文件描述符 0、1 和 2,它们分别就是 stdin、stdout 和 stderr。这三者的值是系统标准(Windows 也是如此),不可改变。
可以把 log 文件的描述符关联到 3。文件系统初始化,描述符 0、1 和 2 关联之后,才能打开 log 文件,开始记录进程的运行轨迹。
为了能尽早访问 log 文件,我们要让上述工作在进程 0 中就完成。所以把这一段代码从 init() 移动到 main() 中,放在 move_to_user_mode() 之后(不能再靠前了),同时加上打开 log 文件的代码。
修改后的 main() 如下:
//……
move_to_user_mode();
/***************添加开始***************/
setup((void *) &drive_info);
// 建立文件描述符0和/dev/tty0的关联
(void) open("/dev/tty0",0);
//文件描述符1也和/dev/tty0关联
(void) dup(0);
// 文件描述符2也和/dev/tty0关联
(void) dup(0);
(void) open("/var/process.log",O_CREAT|O_TRUNC|O_WRONLY,0666);
/***************添加结束***************/
if (!fork()) { /* we count on this going ok */
init();
}
//……
打开 log 文件的参数的含义是建立只写文件,如果文件已存在则清空已有内容。文件的权限是所有人可读可写。
这样,文件描述符 0、1、2 和 3 就在进程 0 中建立了。根据 fork() 的原理,进程 1 会继承这些文件描述符,所以 init() 中就不必再 open() 它们。此后所有新建的进程都是进程 1 的子孙,也会继承它们。但实际上,init() 的后续代码和 /bin/sh 都会重新初始化它们。所以只有进程 0 和进程 1 的文件描述符肯定关联着 log 文件,这一点在接下来的写 log 中很重要。
小结
其实就是为了尽早打开log日志文件开始记录,那必须满足在用户模式且可以进行文件读写,因此最前的位置只能在 move_to_user_mode() 之后(不能再靠前了),并且建立文件描述符 0、1 和 2,它们分别就是 stdin、stdout 和 stderr。
编写fprintk()函数
log 文件将被用来记录进程的状态转移轨迹。所有的状态转移都是在内核进行的。
在内核状态下,write() 功能失效,其原理等同于《系统调用》实验中不能在内核状态调用 printf(),只能调用 printk()。编写可在内核调用的 write() 的难度较大,所以这里直接给出源码。它主要参考了 printk() 和 sys_write() 而写成的:
#include "linux/sched.h"
#include "sys/stat.h"
static char logbuf[1024];
int fprintk(int fd, const char *fmt, ...)
{
va_list args;
int count;
struct file * file;
struct m_inode * inode;
va_start(args, fmt);
count=vsprintf(logbuf, fmt, args);
va_end(args);
/* 如果输出到stdout或stderr,直接调用sys_write即可 */
if (fd < 3)
{
__asm__("push %%fs\n\t"
"push %%ds\n\t"
"pop %%fs\n\t"
"pushl %0\n\t"
/* 注意对于Windows环境来说,是_logbuf,下同 */
"pushl $logbuf\n\t"
"pushl %1\n\t"
/* 注意对于Windows环境来说,是_sys_write,下同 */
"call sys_write\n\t"
"addl $8,%%esp\n\t"
"popl %0\n\t"
"pop %%fs"
::"r" (count),"r" (fd):"ax","cx","dx");
}
else
/* 假定>=3的描述符都与文件关联。事实上,还存在很多其它情况,这里并没有考虑。*/
{
/* 从进程0的文件描述符表中得到文件句柄 */
if (!(file=task[0]->filp[fd]))
return 0;
inode=file->f_inode;
__asm__("push %%fs\n\t"
"push %%ds\n\t"
"pop %%fs\n\t"
"pushl %0\n\t"
"pushl $logbuf\n\t"
"pushl %1\n\t"
"pushl %2\n\t"
"call file_write\n\t"
"addl $12,"r" (file),"r" (inode):"ax","dx");
}
return count;
}
因为和 printk 的功能近似,建议将此函数放入到 kernel/printk.c 中。fprintk() 的使用方式类同与 C 标准库函数 fprintf(),唯一的区别是第一个参数是文件描述符,而不是文件指针。
例如:
// 向stdout打印正在运行的进程的ID
fprintk(1, "The ID of running process is %ld", current->pid);
// 向log文件输出跟踪进程运行轨迹
fprintk(3, "%ld\t%c\t%ld\n", current->pid, 'R', jiffies);
jiffies,滴答
jiffies 在 kernel/sched.c 文件中定义为一个全局变量:
long volatile jiffies=0;
它记录了从开机到当前时间的时钟中断发生次数。在 kernel/sched.c 文件中的 sched_init() 函数中,时钟中断处理函数被设置为:
set_intr_gate(0x20,&timer_interrupt);
而在 kernel/system_call.s 文件中将 timer_interrupt 定义为:
timer_interrupt:
! ……
! 增加jiffies计数值
incl jiffies
! ……
这说明 jiffies 表示从开机时到现在发生的时钟中断次数,这个数也被称为 “滴答数”。
另外,在 kernel/sched.c 中的 sched_init() 中有下面的代码:
// 设置8253模式
outb_p(0x36, 0x43);
outb_p(LATCH&0xff, 0x40);
outb_p(LATCH>>8, 0x40);
这三条语句用来设置每次时钟中断的间隔,即为 LATCH,而 LATCH 是定义在文件 kernel/sched.c 中的一个宏:
// 在 kernel/sched.c 中
#define LATCH (1193180/HZ)
// 在 include/linux/sched.h 中
#define HZ 100
再加上 PC 机 8253 定时芯片的输入时钟频率为 1.193180MHz,即 1193180/每秒,LATCH=1193180/100,时钟每跳 11931.8 下产生一次时钟中断,即每 1/100 秒(10ms)产生一次时钟中断,所以 jiffies 实际上记录了从开机以来共经过了多少个 10ms。
注意这里是 H Z = 100 HZ=100 HZ=100 的情况,前文也介绍过。所以时间其实就是近似等于中断次数乘以 1 / H Z 1/HZ 1/HZ
寻找状态切换点
必须找到所有发生进程状态切换的代码点,并在这些点添加适当的代码,来输出进程状态变化的情况到 log 文件中。
此处要面对的情况比较复杂,需要对 kernel 下的 fork.c、sched.c 有通盘的了解,而 exit.c 也会涉及到。
例子 1:记录一个进程生命期的开始
第一个例子是看看如何记录一个进程生命期的开始,当然这个事件就是进程的创建函数 fork(),由《系统调用》实验可知,fork() 功能在内核中实现为 sys_fork(),该“函数”在文件 kernel/system_call.s 中实现为:
sys_fork:
call find_empty_process
! ……
! 传递一些参数
push %gs
pushl %esi
pushl %edi
pushl %ebp
pushl %eax
! 调用 copy_process 实现进程创建
call copy_process
addl $20,%esp
所以真正实现进程创建的函数是 copy_process(),它在 kernel/fork.c 中定义为:
int copy_process(int nr,……)
{
struct task_struct *p;
// ……
// 获得一个 task_struct 结构体空间
p = (struct task_struct *) get_free_page();
// ……
p->pid = last_pid;
// ……
// 设置 start_time 为 jiffies
p->start_time = jiffies;
// ……
/* 设置进程状态为就绪。所有就绪进程的状态都是
TASK_RUNNING(0),被全局变量 current 指向的
是正在运行的进程。*/
p->state = TASK_RUNNING;
return last_pid;
}
因此要完成进程运行轨迹的记录就要在 copy_process() 中添加输出语句。
这里要输出两种状态,分别是“N(新建)”和“J(就绪)”。
例子 2:记录进入睡眠态的时间
第二个例子是记录进入睡眠态的时间。sleep_on() 和 interruptible_sleep_on() 让当前进程进入睡眠状态,这两个函数在 kernel/sched.c 文件中定义如下:
void sleep_on(struct task_struct **p)
{
struct task_struct *tmp;
// ……
tmp = *p;
// 仔细阅读,实际上是将 current 插入“等待队列”头部,tmp 是原来的头部
*p = current;
// 切换到睡眠态
current->state = TASK_UNINTERRUPTIBLE;
// 让出 CPU
schedule();
// 唤醒队列中的上一个(tmp)睡眠进程。0 换作 TASK_RUNNING 更好
// 在记录进程被唤醒时一定要考虑到这种情况,实验者一定要注意!!!
if (tmp)
tmp->state=0;
}
/* TASK_UNINTERRUPTIBLE和TASK_INTERRUPTIBLE的区别在于不可中断的睡眠
* 只能由wake_up()显式唤醒,再由上面的 schedule()语句后的
*
* if (tmp) tmp->state=0;
*
* 依次唤醒,所以不可中断的睡眠进程一定是按严格从“队列”(一个依靠
* 放在进程内核栈中的指针变量tmp维护的队列)的首部进行唤醒。而对于可
* 中断的进程,除了用wake_up唤醒以外,也可以用信号(给进程发送一个信
* 号,实际上就是将进程PCB中维护的一个向量的某一位置位,进程需要在合
* 适的时候处理这一位。感兴趣的实验者可以阅读有关代码)来唤醒,如在
* schedule()中:
*
* for(p = &LAST_TASK ; p > &FIRST_TASK ; --p)
* if (((*p)->signal & ~(_BLOCKABLE & (*p)->blocked)) &&
* (*p)->state==TASK_INTERRUPTIBLE)
* (*p)->state=TASK_RUNNING;//唤醒
*
* 就是当进程是可中断睡眠时,如果遇到一些信号就将其唤醒。这样的唤醒会
* 出现一个问题,那就是可能会唤醒等待队列中间的某个进程,此时这个链就
* 需要进行适当调整。interruptible_sleep_on和sleep_on函数的主要区别就
* 在这里。
*/
void interruptible_sleep_on(struct task_struct **p)
{
struct task_struct *tmp;
…
tmp=*p;
*p=current;
repeat: current->state = TASK_INTERRUPTIBLE;
schedule();
// 如果队列头进程和刚唤醒的进程 current 不是一个,
// 说明从队列中间唤醒了一个进程,需要处理
if (*p && *p != current) {
// 将队列头唤醒,并通过 goto repeat 让自己再去睡眠
(**p).state=0;
goto repeat;
}
*p=NULL;
//作用和 sleep_on 函数中的一样
if (tmp)
tmp->state=0;
}
总的来说,Linux 0.11 支持四种进程状态的转移:就绪到运行、运行到就绪、运行到睡眠和睡眠到就绪,此外还有新建和退出两种情况。其中就绪与运行间的状态转移是通过 schedule()(它亦是调度算法所在)完成的;运行到睡眠依靠的是 sleep_on() 和 interruptible_sleep_on(),还有进程主动睡觉的系统调用 sys_pause() 和 sys_waitpid();睡眠到就绪的转移依靠的是 wake_up()。所以只要在这些函数的适当位置插入适当的处理语句就能完成进程运行轨迹的全面跟踪了。
修改fork.c文件
fork.c文件在kernel目录下,这里要输出两种状态,分别是“N(新建)”和“J(就绪)”,下面做出两处修改:
int copy_process(int nr,……)
{
struct task_struct *p;
// ……
// 获得一个 task_struct 结构体空间
p = (struct task_struct *) get_free_page();
// ……
p->pid = last_pid;
// ……
// 设置 start_time 为 jiffies
p->start_time = jiffies;
//新增修改,新建进程
fprintk(3,"%d\tN\t%d\n",p->pid,jiffies);
// ……
/* 设置进程状态为就绪。所有就绪进程的状态都是
TASK_RUNNING(0),被全局变量 current 指向的
是正在运行的进程。*/
p->state = TASK_RUNNING;
//新增修改,进程就绪
fprintk(3,"%d\tJ\t%d\n",jiffies);
return last_pid;
}
修改sched.c文件
文件位置:kernel/sched.c
修改schedule函数
//这里仅仅说一下改动了什么
/* check alarm,wake up any interruptible tasks that have got a signal */
for(p = &LAST_TASK ; p > &FIRST_TASK ; --p)
if (*p) {
if ((*p)->alarm && (*p)->alarm < jiffies) {
(*p)->signal |= (1<<(SIGALRM-1));
(*p)->alarm = 0;
}
if (((*p)->signal & ~(_BLOCKABLE & (*p)->blocked)) &&
(*p)->state==TASK_INTERRUPTIBLE){
(*p)->state=TASK_RUNNING;
fprintk(3,(*p)->pid,jiffies);
}
}
while (1) {
c = -1; next = 0; i = NR_TASKS; p = &task[NR_TASKS];
// 找到 counter 值最大的就绪态进程
while (--i) {
if (!*--p) continue;
if ((*p)->state == TASK_RUNNING && (*p)->counter > c)
c = (*p)->counter, next = i;
}
// 如果有 counter 值大于 0 的就绪态进程,则退出
if (c) break;
// 如果没有:
// 所有进程的 counter 值除以 2 衰减后再和 priority 值相加,
// 产生新的时间片
for(p = &LAST_TASK ; p > &FIRST_TASK ; --p)
if (*p)
(*p)->counter = ((*p)->counter >> 1) + (*p)->priority;
}
//切换到相同的进程不输出
if(current->pid != task[next] ->pid)
{
/*新建修改--时间片到时程序 => 就绪*/
if(current->state == TASK_RUNNING)
fprintk(3,current->pid,jiffies);
fprintk(3,"%d\tR\t%d\n",task[next]->pid,jiffies);
}
// 切换到 next 进程
switch_to(next);
修改sys_pause函数
int sys_pause(void)
{
current->state = TASK_INTERRUPTIBLE;
/*
*修改--当前进程 运行 => 可中断睡眠
*/
if(current->pid != 0)
fprintk(3,"%d\tW\t%d\n",jiffies);
schedule();
return 0;
}
修改sleep_on函数
void sleep_on(struct task_struct **p)
{
struct task_struct *tmp;
if (!p)
return;
if (current == &(init_task.task))
panic("task[0] trying to sleep");
tmp = *p;
*p = current;
current->state = TASK_UNINTERRUPTIBLE;
/*
*修改--当前进程进程 => 不可中断睡眠
*/
fprintk(3,jiffies);
schedule();
if (tmp)
{
tmp->state=0;
/*
*修改--原等待队列 第一个进程 => 唤醒(就绪)
*/
fprintk(3,tmp->pid,jiffies);
}
}
修改interruptible_sleep_on函数
void interruptible_sleep_on(struct task_struct **p)
{
struct task_struct *tmp;
if (!p)
return;
if (current == &(init_task.task))
panic("task[0] trying to sleep");
tmp=*p;
*p=current;
repeat: current->state = TASK_INTERRUPTIBLE;
/*
*修改--唤醒队列中间进程,过程中使用Wait
*/
fprintk(3,jiffies);
schedule();
if (*p && *p != current) {
(**p).state=0;
/*
*修改--当前进程 => 可中断睡眠
*/
fprintk(3,jiffies);
goto repeat;
}
*p=NULL;
if (tmp)
{
tmp->state=0;
/*
*修改--原等待队列 第一个进程 => 唤醒(就绪)
*/
fprintk(3,jiffies);
}
}
修改wake_up函数
void wake_up(struct task_struct **p)
{
if (p && *p) {
(**p).state=0;
/*
*修改--唤醒 最后进入等待序列的 进程
*/
fprintk(3,jiffies);
*p=NULL;
}
}
修改exit.c文件
当一个进程结束了运行或在半途中终止了运行,那么内核就需要释放该进程所占用的系统资源。这包括进程运行时打开的文件、申请的内存等。
当一个用户程序调用exit()系统调用时,就会执行内核函数do_exit()。该函数会首先释放进程代码段和数据段占用的内存页面,关闭进程打开着的所有文件,对进程使用的当前工作目录、根目录和运行程序的i节点进行同步操作。如果进程有子进程,则让init进程作为其所有子进程的父进程。如果进程是一个会话头进程并且有控制终端,则释放控制终端(如果按照实验的数据,此时就应该打印了),并向属于该会话的所有进程发送挂断信号 SIGHUP,这通常会终止该会话中的所有进程。然后把进程状态置为僵死状态 TASK_ZOMBIE。并向其原父进程发送 SIGCHLD 信号,通知其某个子进程已经终止。最后 do_exit()调用调度函数去执行其他进程。由此可见在进程被终止时,它的任务数据结构仍然保留着。因为其父进程还需要使用其中的信息。
在子进程在执行期间,父进程通常使用wait()或 waitpid()函数等待其某个子进程终止。当等待的子进程被终止并处于僵死状态时,父进程就会把子进程运行所使用的时间累加到自己进程中。最终释放已终止子进程任务数据结构所占用的内存页面,并置空子进程在任务数组中占用的指针项。
int do_exit(long code)
{
int i;
free_page_tables(get_base(current->ldt[1]),get_limit(0x0f));
free_page_tables(get_base(current->ldt[2]),get_limit(0x17));
// ……
current->state = TASK_ZOMBIE;
/*
*修改--退出一个进程
*/
fprintk(3,"%d\tE\t%d\n",jiffies);
current->exit_code = code;
tell_father(current->father);
schedule();
return (-1); /* just to suppress warnings */
}
// ……
int sys_waitpid(pid_t pid,unsigned long * stat_addr, int options)
{
int flag, code;
struct task_struct ** p;
// ……
// ……
if (flag) {
if (options & WNOHANG)
return 0;
current->state=TASK_INTERRUPTIBLE;
/*
*修改--当前进程 => 等待
*/
fprintk(3,jiffies);
schedule();
if (!(current->signal &= ~(1<<(SIGCHLD-1))))
goto repeat;
else
return -EINTR;
}
return -ECHILD;
}
小结
总的来说,Linux 0.11 支持四种进程状态的转移:就绪到运行、运行到就绪、运行到睡眠和睡眠到就绪,此外还有新建和退出两种情况。其中就绪与运行间的状态转移是通过 schedule()(它亦是调度算法所在)完成的;运行到睡眠依靠的是 sleep_on() 和 interruptible_sleep_on(),还有进程主动睡觉的系统调用 sys_pause() 和 sys_waitpid();睡眠到就绪的转移依靠的是 wake_up()。所以只要在这些函数的适当位置插入适当的处理语句就能完成进程运行轨迹的全面跟踪了。
为了让生成的 log 文件更精准,以下几点请注意:
- 进程退出的最后一步是通知父进程自己的退出,目的是唤醒正在等待此事件的父进程。从时序上来说,应该是子进程先退出,父进程才醒来。
- 系统无事可做的时候,进程 0 会不停地调用
sys_pause(),以激活调度算法。此时它的状态可以是等待态,等待有其它可运行的进程;也可以叫运行态,因为它是唯一一个在 CPU 上运行的进程,只不过运行的效果是等待。
编译
重新编译
make all
编译运行process.c
将process.c拷贝到linux0.11系统中,这个过程需要挂载一下系统硬盘,挂载拷贝成功之后再卸载硬盘,然后启动模拟器进入系统内编译一下process.c文件,过程命令及截图如下:
// oslab目录下运行
sudo ./mount-hdc
cp ./test3/process.c ./hdc/usr/root/
sudo umonut hdc
进入linux-0.11
gcc -o process process.c
./process
sync
使用./process即可运行目标文件,运行后会生成log文件,生成log文件后一定要记得刷新,然后将其拷贝到oslab/test3目录,命令如下:
sudo ./mount-hdc
cp ./hdc/var/process.log ./test3/
sudo umonut hdc
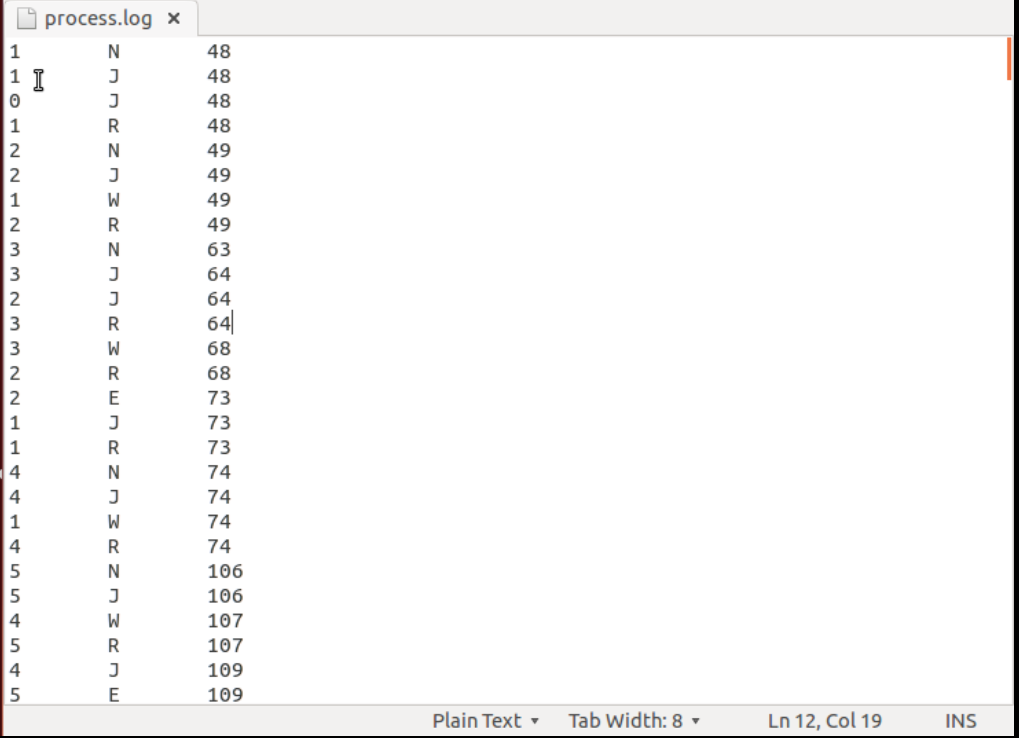
process.log自动化分析
只要给 stat_log.py 加上执行权限(使用的命令为 chmod +x stat_log.py)就可以直接运行它。
在结果中我们可以看到各个进程的周转时间(Turnaround,指作业从提交到完成所用的总时间)、等待时间等,以及平均周转时间和等待时间。
修改时间片
MOOC哈工大操作系统实验3:进程运行轨迹的跟踪与统计_ZhaoTianhao的博客-CSDN博客
这段没有耐心实现了,摘录了一位博主的解释
linux0.11采用的调度算法是一种综合考虑进程优先级并能动态反馈调整时间片的轮转调度算法。 那么什么是轮转调度算法呢?它为每个进程分配一个时间段,称作它的时间片,即该进程允许运行的时间。如果在时间片结束时进程还在运行,则CPU将被剥夺并分配给另一个进程;如果进程在时间片结束前阻塞或结束,则CPU当即进行切换。调度程序所要做的就是维护一张就绪进程列表,当进程用完它的时间片后,它被移到队列的末尾。那什么是综合考虑进程优先级呢?就是说一个进程在阻塞队列中停留的时间越长,它的优先级就越大,下次就会被分配更大的时间片。
进程之间的切换是需要时间的,如果时间片设定得太小的话,就会发生频繁的进程切换,因此会浪费大量时间在进程切换上,影响效率;如果时间片设定得足够大的话,就不会浪费时间在进程切换上,利用率会更高,但是用户交互性会受到影响,举一个很直观的例子:我在银行排队办业务,假设我要办的业务很简单只需要占用1分钟,如果每个人的时间片是30分钟,而我前面的每个人都要用满这30分钟,那我就要等上好几个小时!如果每个人的时间片是2分钟的话,我只需要等十几分钟就可以办理我的业务了,前面没办完的会在我之后轮流地继续去办。所以时间片不能过大或过小,要兼顾CPU利用率和用户交互性。
时间片的初始值是进程0的priority,是在linux-0.11/include/linux/sched.h的宏 INIT_TASK 中定义的,如下:我们只需要修改宏中的第三个值即可,该值即时间片的初始值。
#define INIT_TASK \
{ 0,
// 上述三个值分别对应 state、counter 和 priority;
修改完后再次编译make all,进入模拟器后编译运行测试文件process.c,然后运行统计脚本stat_log.py查看结果,与之前的结果进行对比。
问题回答
问题1:单进程编程和多进程编程的区别?
1.执行方式:单进程编程是一个进程从上到下顺序进行;多进程编程可以通过并发执行,即多个进程之间交替执行,如某一个进程正在I/O输入输出而不占用CPU时,可以让CPU去执行另外一个进程,这需要采取某种调度算法。
2.数据是否同步:单进程的数据是同步的,因为单进程只有一个进程,在进程中改变数据的话,是会影响这个进程的;多进程的数据是异步的,因为子进程数据是父进程数据在内存另一个位置的拷贝,因此改变其中一个进程的数据,是不会影响到另一个进程的。
3.CPU利用率:单进程编程的CPU利用率低,因为单进程在等待I/O时,CPU是空闲的;多进程编程的CPU利用率高,因为当某一进程等待I/O时,CPU会去执行另一个进程,因此CPU的利用率高。
4.多进程用途更广泛。
问题2:仅针对样本程序建立的进程,在修改时间片前后,log 文件的统计结果都是什么样?结合你的修改分析一下为什么会这样变化,或者为什么没变化?
依次将时间偏设为1,5,10,15,20,25,50,100,150后,经统计分析log文件可以发现:
1)在一定的范围内,平均等待时间,平均完成时间的变化随着时间片的增大而减小。这是因为在时间片小的情况下,cpu将时间耗费在调度切换上,所以平均等待时间增加。
2)超过一定的范围之后,这些参数将不再有明显的变化,这是因为在这种情况下,RR轮转调度就变成了FCFS先来先服务了。随着时间片的修改,吞吐量始终没有明显的变化,这是因为在单位时间内,系统所能完成的进程数量是不会变的。
警示
编译好后进入linux-0.11
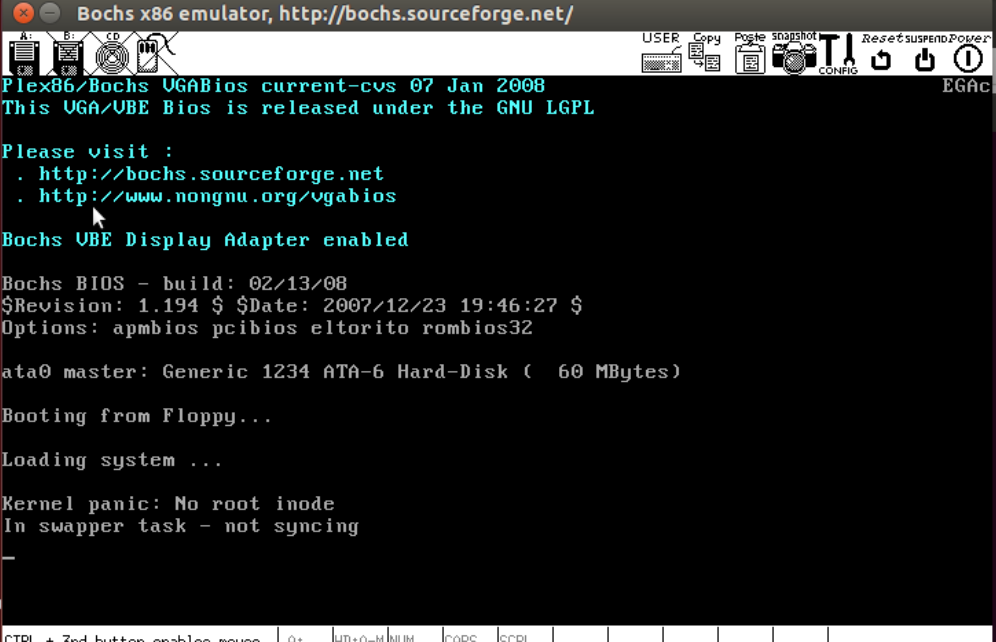
直接报了内核错误,这肯定是之前的代码打错了。那么多代码,我怎么知道错误在哪。但是注意以前正常情况下会打印剩余空间。
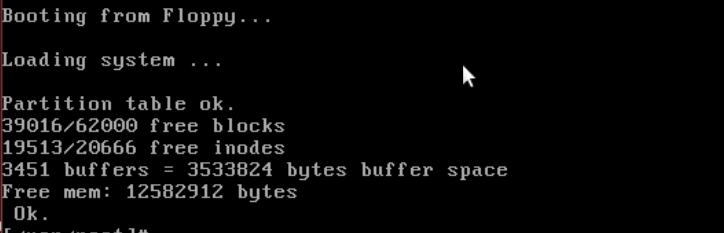
而先前改代码的时候发现这段打印的代码就在进程1 init() 函数内,所以推断是修改进程0时出现了错误

好家伙,顺序反了。之前说了,文件系统初始化,描述符 0、1 和 2 关联之后,才能打开 log 文件。这里却直接先打开 log 文件了。
原文地址:https://blog.csdn.net/leoabcd12
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。