
1. 为什么要使用数据库连接池
使用数据库连接池主要考虑到程序与数据库建立连接的性能。创建一个新的数据库是一个很耗时的过程,在使用完之后,可能还需要不断的释放建立的连接,对资源的损耗大。
而采用数据库连接池之后,首先就创建了固定数量的数据库连接,需要用的时候使用即可。当然,这样做的一个缺点是,可能某些时候完全没有数据库请求,但是也保持了数据库的最小连接数。浪费了资源。不过这种浪费资源相对于完全不采用数据库连接池还是很有优势的。
2. 常见的数据库连接池
常见的数据库连接池主要有c3p0,dbcp,tomcat-jdbc-pool,druid,HiKariCP。
c3p0
来源于《星球大战》中的一个机器人名称,同时这个名称也包含connection pool中的英文字母。不提供对数据库的监控。使用时是单线程的。
dbcp
(database connection pool)是Apache基金会下面的数据库连接池,同时也是tomcat7.0以前的内置数据库连接池(tomcat也是apache基金会下)。独立使用时,需要提供common-dbcp.jar,common-pool.jar,common-connection.jar这三个包。不提供数据库的监控。使用时是单线程的。
tomcat jdbc pool
这个是tomcat7.0后新增的数据库连接池,它兼容dbcp。但是比dbcp性能更高。
druid
是阿里巴巴开源的数据库连接池,提供对数据库的监控,就是为监控而生。它的功能最为全面,可扩展性好,具有sql拦截的功能。
HiKariCP
是数据库连接池里面的后起之秀,出来的比较往,但是性能很好。
总的来说:性能方面HiKariCP>druid>tomcat jdbc pool>dbcp>c3p0(参考),因为我这边要选择可以监控数据库的,所以选择了druid。
3. druid配置详解
druid的详细源码可以从 https://github.com/alibaba/druid进行下载。
druid的DataSource基类为:com.alibaba.druid.pool.DruidDataSource。基本的参数配置如下:
| 配置 | 缺省值 | 说明 |
| name | 配置这个属性的意义在于,如果存在多个数据源,监控的时候可以通过名字来区分开来。 如果没有配置,将会生成一个名字,格式是:"DataSource-" + System.identityHashCode(this) |
|
| jdbcUrl | 连接数据库的url,不同数据库不一样。例如: mysql : jdbc:mysql://localhost:3306/druid oracle : jdbc:oracle:thin:@localhost:1521:mydb |
|
| username | 连接数据库的用户名 | |
| password | 连接数据库的密码。如果你不希望密码直接写在配置文件中,可以使用ConfigFilter。详细看这里:https://github.com/alibaba/druid/wiki/%E4%BD%BF%E7%94%A8ConfigFilter | |
| driverClassName | 根据url自动识别 | 这一项可配可不配,如果不配置druid会根据url自动识别dbType,然后选择相应的driverClassName(建议配置下) |
| initialSize | 0 | 初始化时建立物理连接的个数。初始化发生在显示调用init方法,或者第一次getConnection时 |
| maxActive | 8 | 最大连接池数量 |
| maxIdle | 8 | 已经不再使用,配置了也没效果 |
| minIdle | 最小连接池数量 | |
| maxWait | 获取连接时最大等待时间,单位毫秒。配置了maxWait之后,缺省启用公平锁,并发效率会有所下降,如果需要可以通过配置useUnfairLock属性为true使用非公平锁。 | |
| poolPreparedStatements | false | 是否缓存preparedStatement,也就是PSCache。PSCache对支持游标的数据库性能提升巨大,比如说oracle。在mysql下建议关闭。 |
| maxOpenPreparedStatements | -1 | 要启用PSCache,必须配置大于0,当大于0时,poolPreparedStatements自动触发修改为true。在Druid中,不会存在Oracle下PSCache占用内存过多的问题,可以把这个数值配置大一些,比如说100 |
| validationQuery | 用来检测连接是否有效的sql,要求是一个查询语句。如果validationQuery为null,testOnBorrow、testOnReturn、testWhileIdle都不会其作用。 | |
| testOnBorrow | true | 申请连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能。 |
| testOnReturn | false | 归还连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能 |
| testWhileIdle | false | 建议配置为true,不影响性能,并且保证安全性。申请连接的时候检测,如果空闲时间大于timeBetweenEvictionRunsMillis,执行validationQuery检测连接是否有效。 |
| timeBetweenEvictionRunsMillis | 有两个含义: 1) Destroy线程会检测连接的间隔时间2) testWhileIdle的判断依据,详细看testWhileIdle属性的说明 |
|
| numTestsPerEvictionRun | 不再使用,一个DruidDataSource只支持一个EvictionRun | |
| minEvictableIdleTimeMillis | ||
| connectionInitSqls | 物理连接初始化的时候执行的sql | |
| exceptionSorter | 根据dbType自动识别 | 当数据库抛出一些不可恢复的异常时,抛弃连接 |
| filters | 属性类型是字符串,通过别名的方式配置扩展插件,常用的插件有: 监控统计用的filter:stat日志用的filter:log4j防御sql注入的filter:wall |
|
| proxyFilters | 类型是List<com.alibaba.druid.filter.Filter>,如果同时配置了filters和proxyFilters,是组合关系,并非替换关系 |
4. druid使用demo
springboot的默认数据源是org.apache.tomcat.jdbc.pool.DataSource。因为我们在这里使用的是druid,所以需要修改spring.datasource.type为druid。
a.添加pom依赖
<!-- https://mvnrepository.com/artifact/com.alibaba/druid -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.10</version>
</dependency>b.将与数据库连接的配置进行修改
修改前:
spring:
application:
name: dev-manager
datasource:
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/dev_manage?useUnicode=true&characterEncoding=UTF-8
username: root
password: abc12345修改后:
spring:
application:
name: dev-manager
datasource:
# 配置数据源类型
type:
com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/dev_manage?useUnicode=true&characterEncoding=UTF-8
username: root
password: abc12345
# 初始化,最小,最大连接数
initialSize: 3
minidle: 3
maxActive: 18
# 获取数据库连接等待的超时时间
maxWait: 60000
# 配置多久进行一次检测,检测需要关闭的空闲连接 单位毫秒
timeBetweenEvictionRunsMillis: 60000
validationQuery: SELECT 1 FROM dual
# 配置监控统计拦截的filters,去掉后,监控界面的sql无法统计
filters: stat,wall,log4jc.配置监控统计功能
@Configuration
public class DruidConfiguration {
/**
* 注册一个StatViewServlet
* @return
*/
@Bean
public ServletRegistrationBean DruidStatViewServle(){
//org.springframework.boot.context.embedded.ServletRegistrationBean提供类的进行注册.
ServletRegistrationBean servletRegistrationBean = new ServletRegistrationBean(new StatViewServlet(),"/druid/*");
//添加初始化参数:initParams
//白名单:
servletRegistrationBean.addInitParameter("allow","127.0.0.1");
//IP黑名单 (存在共同时,deny优先于allow) : 如果满足deny的话提示:Sorry,you are not permitted to view this page.
servletRegistrationBean.addInitParameter("deny","192.168.0.114");
//登录查看信息的账号密码.
servletRegistrationBean.addInitParameter("loginUsername","admin");
servletRegistrationBean.addInitParameter("loginPassword","123456");
//是否能够重置数据.
servletRegistrationBean.addInitParameter("resetEnable","false");
return servletRegistrationBean;
}
/**
* 注册一个:filterRegistrationBean
* @return
*/
@Bean
public FilterRegistrationBean druidStatFilter(){
FilterRegistrationBean filterRegistrationBean = new FilterRegistrationBean(new WebStatFilter());
//添加过滤规则.
filterRegistrationBean.addUrlPatterns("/*");
//添加不需要忽略的格式信息.
filterRegistrationBean.addInitParameter("exclusions","*.js,*.gif,*.jpg,*.png,*.css,*.ico,/druid/*");
return filterRegistrationBean;
}
}5. 访问监控页面
访问监控页面http://ip:port/druid/index.html
6. 数据结果对比
在使用数据库连接池前后,可以通过在数据库执行:show full processlist,判断当前数据库有多少连接数。
在实际项目中,我在未使用数据库连接池时,腾讯云数据库24小时的监控如下
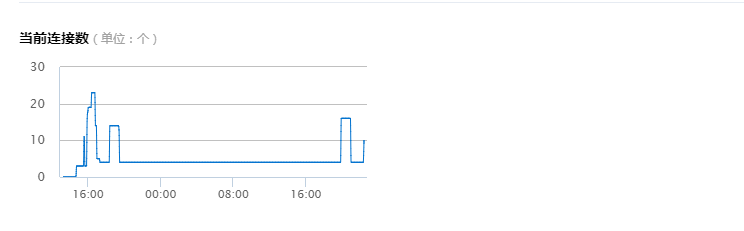
使用后的连接数
7. 总结
在实际项目中,数据库连接池的使用是必不可少的。没有采用数据库连接池时,系统是按照数据库默认的方式保持一定的连接数,将一定的连接数保持在休眠状态。采用druid数据库连接池后,正常保持多少连接数,最大保持多少连接数都是可配置的。也有一台完整的平台监控整个数据库。
8. 参考
数据库连接池性能比对(hikari druid c3p0 dbcp jdbc)
数据库连性池性能测试(hikariCP,druid,tomcat-jdbc,dbcp,c3p0)
c3p0、dbcp、tomcat jdbc pool 连接池区别(推荐使用jdbc pool)
Spring Boot使用Druid和监控配置【从零开始学Spring Boot】
原文地址:https://blog.csdn.net/u014209205
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。