
关于自动化测试报告:
之前用过testNG自带的测试报告、优化过reportNG的测试报告、extentreport、Zreport(大飞总原创),这些是我之前都用过的,也是在去年雯姐和我说过Allure2这个报告不错,一直没时间,正巧最近有用到,接触下发现确实是个神器。
Allure(已经有allure2了,小编用的就是allure2),生成的测试报告与上述对比,简直堪称完美!先上个测试报告的图表,给大家直观感受下:

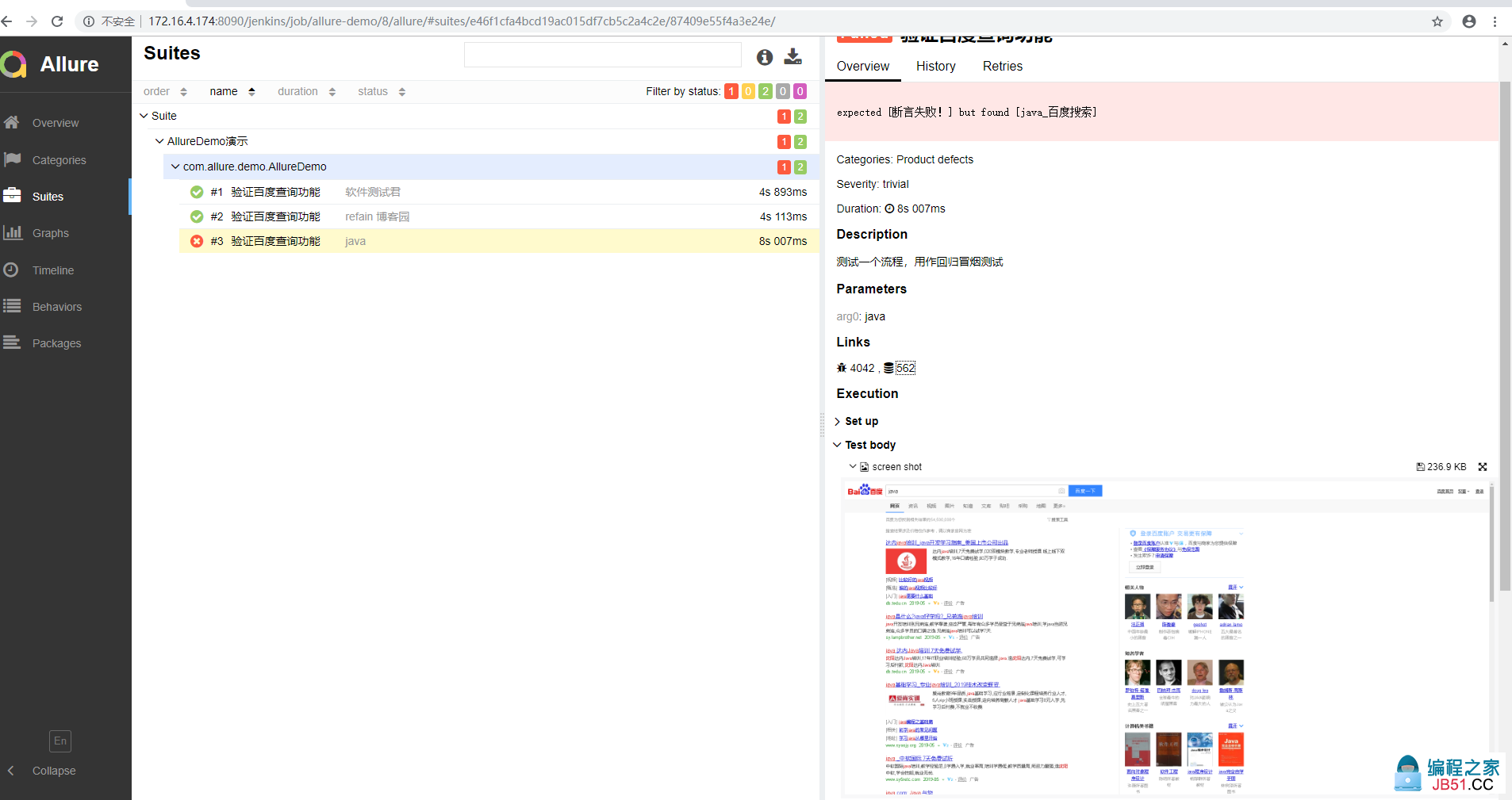
下面让我们一起走进Allure的世界,跟上步伐,相信我这一切并不难
一、pom文件部分
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> modelVersion>4.0.0</> groupId>allure-demoartifactIdversion>1.0-SNAPSHOTproperties> allure.version>2.10.0project.build.sourceEncoding>UTF-8java.version>1.8aspectj.version>1.9.2suiteXmlFile>src/test/resources/suite/test-moudle/testng.xmldependencies> dependency> >selenium-server-standalone>3.9.1>io.qameta.allure>allure-testng>${allure.version}scope>test>org.hamcrest>hamcrest-all>1.3>org.testng>testng>6.14.3>allure-java-commonsbuildpluginsplugin> >org.apache.maven.plugins>maven-compiler-plugin>3.3configuration> sourcetargetencoding>maven-surefire-plugin>2.22.1argLine> -javaagent:"${settings.localRepository}/org/aspectj/aspectjweaver/${aspectj.version}/aspectjweaver-${aspectj.version}.jar" suiteXmlFiles> <!--该文件位于工程根目录时,直接填写名字,其它位置要加上路径--> >src/test/resources/testng.xml>org.aspectj>aspectjweaver>${aspectj.version}reportingexcludeDefaults>true>allure-mavenreportVersion> project>
二、安装插件
在Jenkins插件管理中,搜索Allure即可

三、安装Allure Commandline
- 安装完allure插件后,进入系统管理-->全局工具配置,安装Allure Commandline
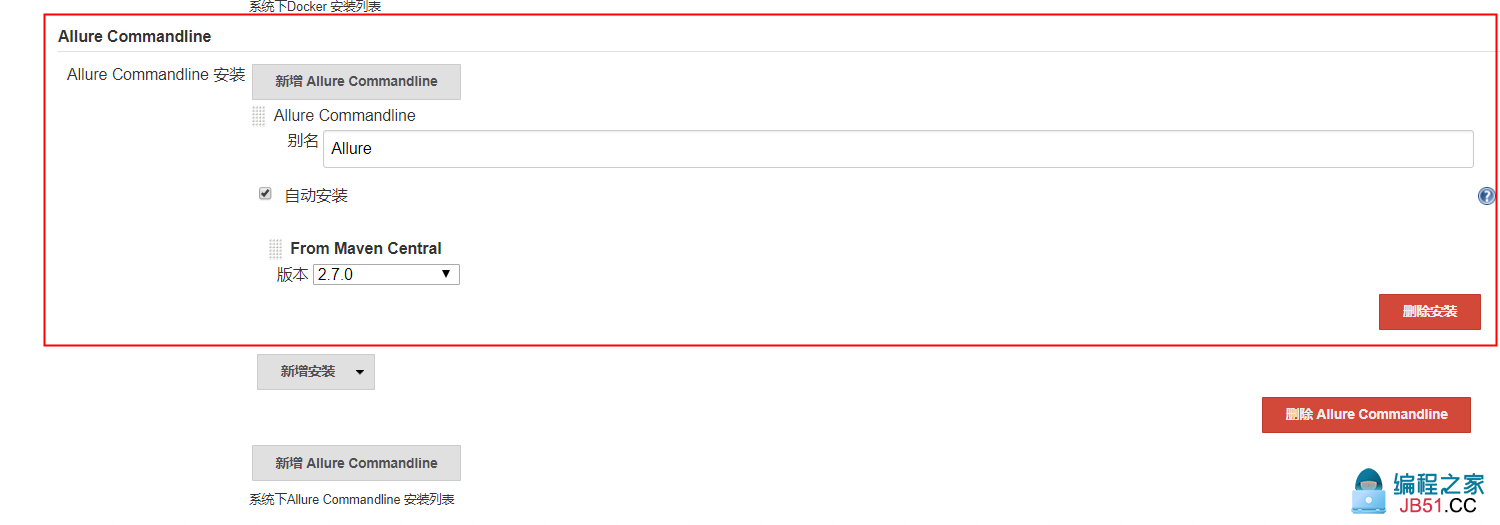
保存即可
此时再通过Jenkins构建并执行测试代码后,就可以看到Allure的测试报告了。以上,完成了Allure的基本配置。
四、Allure用法
1、注解:
我只列举一些常用的注解,其他的可以自行去官网查阅
//用例编号 @TmsLink("562") bug编号 @Issue("4042"bug严重等级,优先级,包含blocker,critical,normal,minor,trivial 几个不同的等级 @Severity(SeverityLevel.TRIVIAL) 用例描述 @Description("测试一个流程,用作回归冒烟测试")
添加@TmsLink, @Issue注解后,在allure report中会生成相应的链接,但是它是如何访问我们的缺陷管理系统以及用例管理系统给的呢,在官网文档有说明。
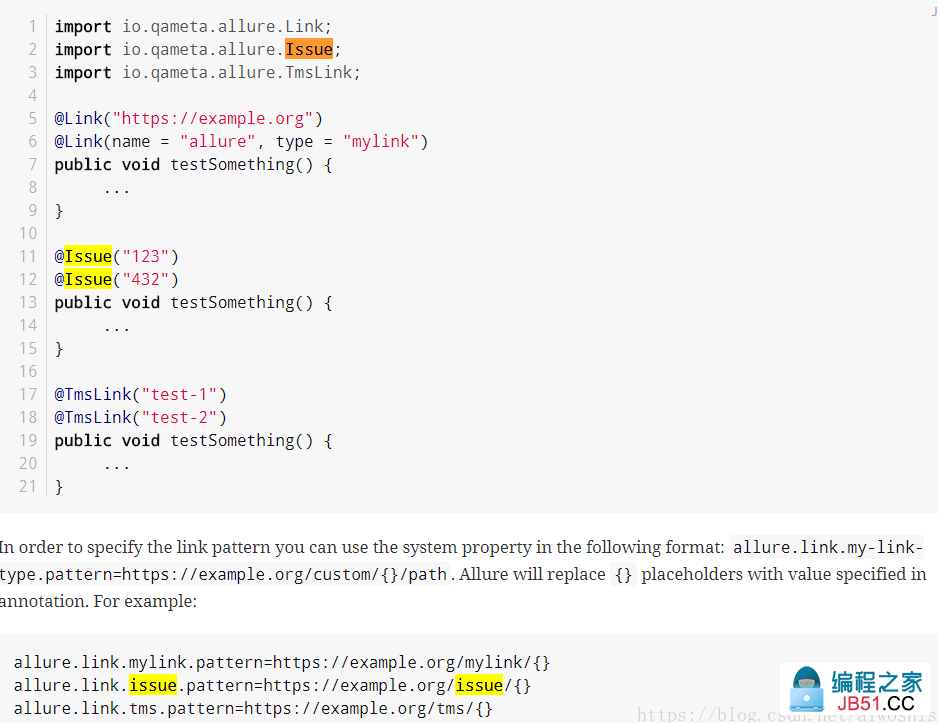
查看文档发现,需要有一个配置文件,将我们系统域名预先设置好,再将{}的内容使用注解进行替换,这样就能访问到我们想范文的连接了。但是官方并没有说明这个配置文件的具体配置,好在官方有一些简单的小demo可供产考;
这是官方的testng的demo地址https://github.com/allure-examples/allure-testng-example/tree/master/src/test/resources
可以看到它有一个文件名叫做allure.properties
这是文件的内容
allure.results.directory=target/allure-results allure.link.issue.pattern=https:example.org/issue/{} allure.link.tms.pattern=https:example.org/tms/{}
第一个应该是默认的输出路径,暂时未用到先不研究,将你需要访问的url替换就可以,比如:
allure.link.issue.pattern=http:jira.XXX.com/browse/{} allure.link.tms.pattern=http:testlink.XXX.com/{}
这里需要注意一点,allure.properties的位置必须是跟你路径下的test同级否则会找不到这个文件;
我用的是idea创建的maven项目

最终效果如下:
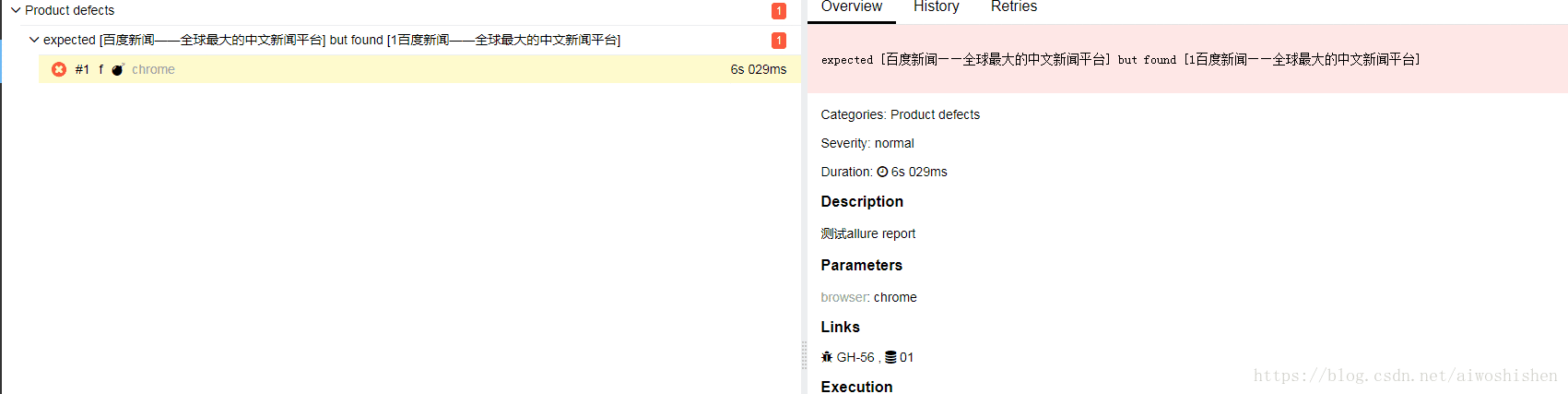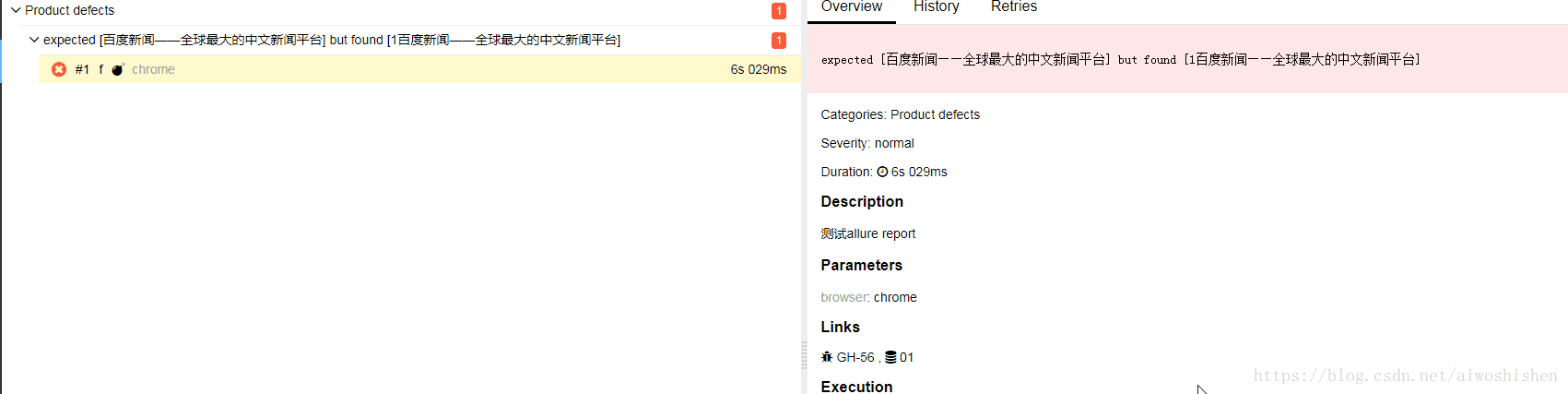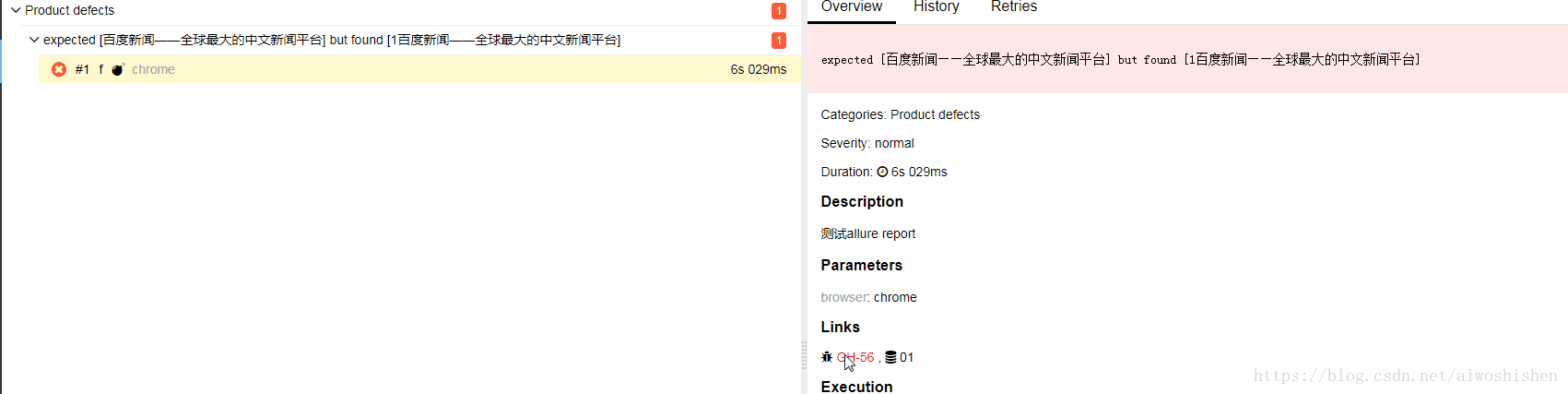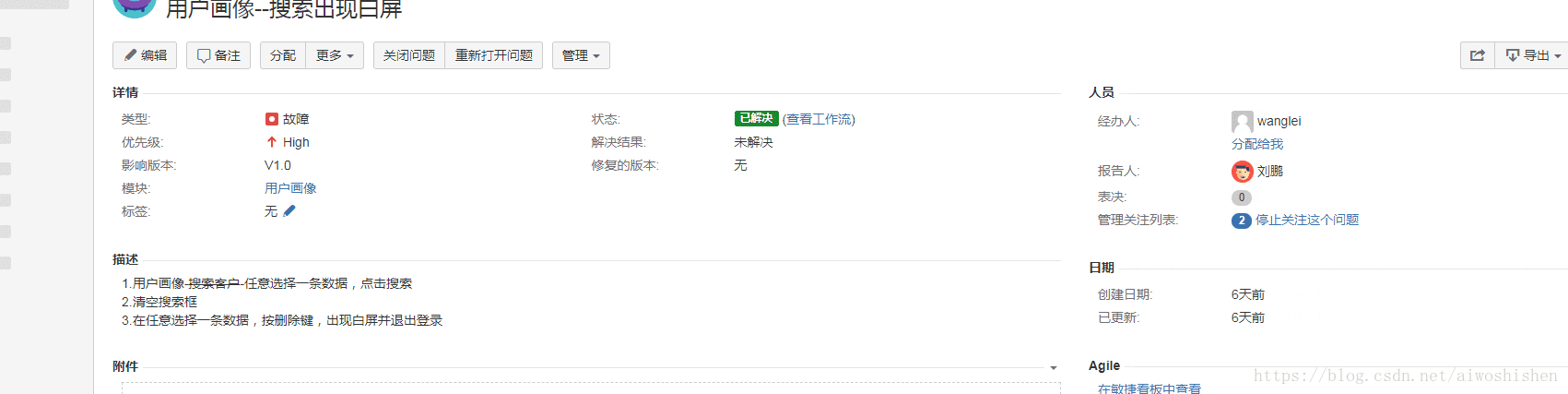
2、自动截图
allure最吸引我的地方是,不用存到本地,它能将selenium的截图放到report中
第一步:写一个监听类,当执行失败自动截图
package com.allure.demo; import io.qameta.allure.Attachment; org.openqa.selenium.OutputType; org.openqa.selenium.TakesScreenshot; org.testng.ITestResult; org.testng.TestListenerAdapter; public class TestFailListener extends TestListenerAdapter { @Override void onTestFailure(ITestResult result) { screenshot(); } @Attachment(value = "screen shot",type = "image/png"byte[] screenshot(){ byte[] screenshotAs = ((TakesScreenshot)GetDriver.driver).getScreenshotAs(OutputType.BYTES); return screenshotAs; } }
第二步:在测试类上,添加Listeners的注解
import io.qameta.allure.*; org.openqa.selenium.By; org.openqa.selenium.Keys; org.openqa.selenium.WebDriver; org.testng.Assert; import org.testng.annotations.*; java.util.concurrent.TimeUnit; @Epic("百度查询功能测试") @Feature("百度查询功能") @Listeners(TestFailListener.class) AllureDemo { static WebDriver driver; static final int MAX_TIMEOUT_IN_SECONDS = 5; @BeforeClass void beforeClass() throws Exception { driver = new GetDriver().getDriver(); String url = "https://www.baidu.com/"; driver.manage().window().maximize(); driver.manage().timeouts().implicitlyWait(MAX_TIMEOUT_IN_SECONDS,TimeUnit.SECONDS); driver.get(url); } 用例描述 @Description("测试一个流程,用作回归冒烟测试"/** *功能块,具有相同feature或astory的用例将规整到相同模块下,执行时可用于筛选 */ @Story("查询场景-正向查询功能") @Test(description = "验证百度查询功能",dataProvider = "testDemo"void testDemo(String key) Exception { driver.findElement(By.id("kw")).clear(); driver.findElement(By.id("kw")).sendKeys(key,Keys.ENTER); Thread.sleep(3000); Assert.assertEquals(driver.getTitle(),key + "_百度搜索"); if (key.equals("java")){ Assert.assertEquals(driver.getTitle(),"断言失败!"); } } @AfterClass tearDownAfterClass() { if (driver != null) { System.out.println("运行结束!"); driver.quit(); } } @DataProvider(name = "testDemo"public Object[][] testDemo() { return Object[][]{ {"软件测试君"},{"refain 博客园"是不是很nice,还不动手试一试········
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。