
StackExchange.Redis驱动。
由于封装代码啥的都是网上下载的,第一反应就是把上面的“connectTimeout”设为5000 * 60 =3min,但是丝毫没有用处,也就是3min没有起
到作用,码蛋的,这可怎么办???只能硬着头皮去看StackExchange的源码,终于在1个小时的地毯式搜索中找到了两处凶杀现场,如下所示:
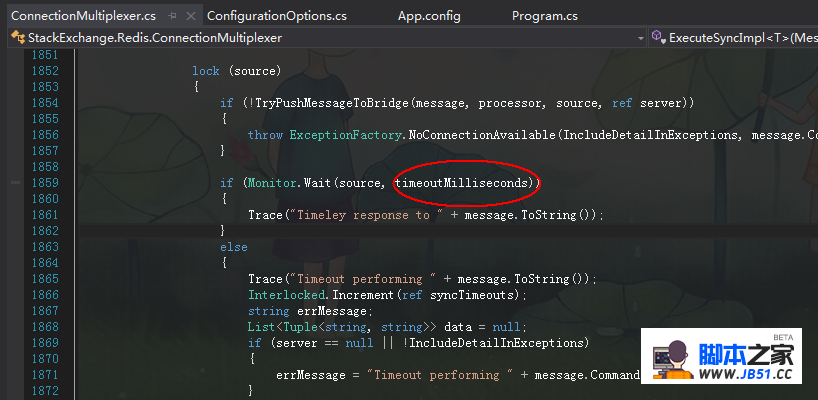

接着我发现其中的 timeoutMilliseconds 和 this.multiplexer.RawConfig.ResponseTimeout的取值决定着是否会抛异常,感谢感谢,接下来我继续
顺藤摸瓜,找到了两个属性的赋值处。
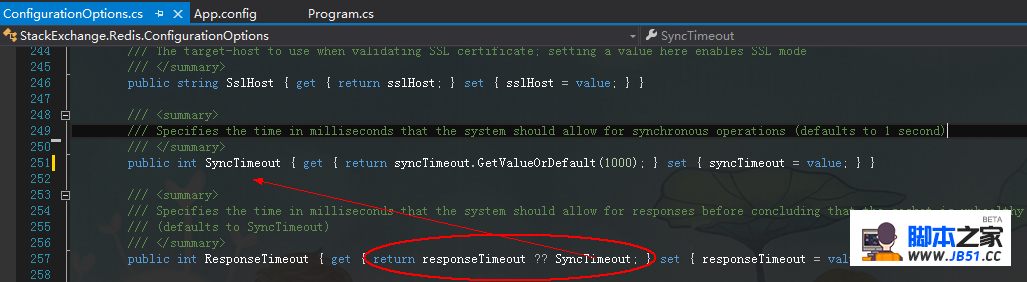
当我看到了上面的syncTimeout.GetValueOrDefault(1000)的时候一颗悬着的心也就放下了,也懒得改了,直接将这里的1000改成1000*60*5
就好啦,commit代码后让同事再运行下看看效果。。。终于拨开迷雾见青天,数据出来啦,遗憾的是,读写操作需要耗时3s,虽然问题表面上看似
解决了,但是问题来了,3s延时真的不是什么好事情,我们都知道redis是单线程的,那就意味着什么??? 意味着这3s的时间内其他redis客户端
是阻塞的。。。虽然心里是这么想的,但是还是存有一点侥幸心理觉得不是这样的,不过还是决定做一个实验看一看。
我决定开一个线程将一个txt中140M的数据插入到redis的hashset中,同时我开另一个线程1秒钟一次的从string中获取数据,同时记录下获
取时间,如果获取string的时间间隔太大,说明阻塞产生了,想法就是这样,说干就干。。。

读取string的线程被Hashset阻塞了6s之多,很恐怖,这个就属于典型的慢查询,它的慢果然阻塞了其他client,接下来就拿着问题找同事,第一个想
法就是问同事为什么要存这么大的数据,得知为了避免海量运算必须要存这么大数据之后,没撤只能从假定80M的数据量做优化,第二个想法就是拆,
既然是80M的数据,我可以拆成8份10M的数据,这样有两个好处,第一个不会太拖长Hset的时间,第二个尽最大努力不阻塞其他client,但是呢,同
事不想改动代码,还要问我还有其他解决方案不???然后我就提了一个下下策,隔离你的缓存业务,既然你都是存储大数据,那我专门给你开一个
redis去存储缓存,几秒钟就几秒钟吧,估计对他业务还能够承受,我可不能让我的主redis因为这个吊毛业务挂了。。。
自从发生这个事情之后,我就有一个想法了,我是不是也需要记录一下主redis中那些“慢操作”的命令,然后找到相关的业务方,不然的话,阻塞
就不好玩了。然后就直接在redis手册中就找到了相关的命令。
Slow log 是 Redis 用来记录查询执行时间的日志系统。
查询执行时间指的是不包括像客户端响应(talking)、发送回复等 IO 操作,而单单是执行一个查询命令所耗费的时间。
另外,slow log 保存在内存里面,读写速度非常快,因此你可以放心地使用它,不必担心因为开启 slow log 而损害 Redis 的速度。
设置 SLOWLOG
Slow log 的行为由两个配置参数(configuration parameter)指定,可以通过改写 redis.conf 文件或者用 CONFIG GET 和 CONFIG SET 命令对它们动态地进行修改。
第一个选项是 slowlog
-log-slower-than ,它决定要对执行时间大于多少微秒(microsecond,1秒 = <span style="color: #800080;">1,<span style="color: #800080;">000,<span style="color: #800080;">000<span style="color: #000000;"> 微秒)的查询进行记录。比如执行以下命令将让 slow log 记录所有查询时间大于等于 <span style="color: #800080;">100<span style="color: #000000;"> 微秒的查询:
CONFIG SET slowlog-log-slower-than <span style="color: #800080;">100<span style="color: #000000;">
而以下命令记录所有查询时间大于 <span style="color: #800080;">1000<span style="color: #000000;"> 微秒的查询:
CONFIG SET slowlog-log-slower-than <span style="color: #800080;">1000<span style="color: #000000;">
另一个选项是 slowlog-max-len ,它决定 slow log 最多能保存多少条日志, slow log 本身是一个 FIFO 队列,当队列大小超过 slowlog-max-<span style="color: #000000;">len 时,最旧的一条日志将被删除,而最新的一条日志加入到 slow log ,以此类推。
以下命令让 slow log 最多保存 <span style="color: #800080;">1000<span style="color: #000000;"> 条日志:
CONFIG SET slowlog-max-len <span style="color: #800080;">1000
从上面这段话中,大概看出了两个属性: slowlog-log-slower-than 和 slowlog-max-len,为了测试方便,我就不config set了,直接改掉
redis.conf文件即可。。。
You can reclaim memory used by the slow log with SLOWLOG RESET.
slowlog
-max-len <span style="color: #800080;">10然后我简单测试一下,所有command都会被记录到slowlog里面去了,下图中的红色框框就是comand的执行时间。
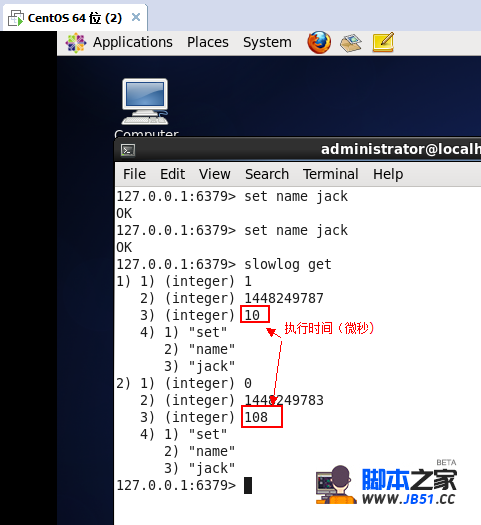
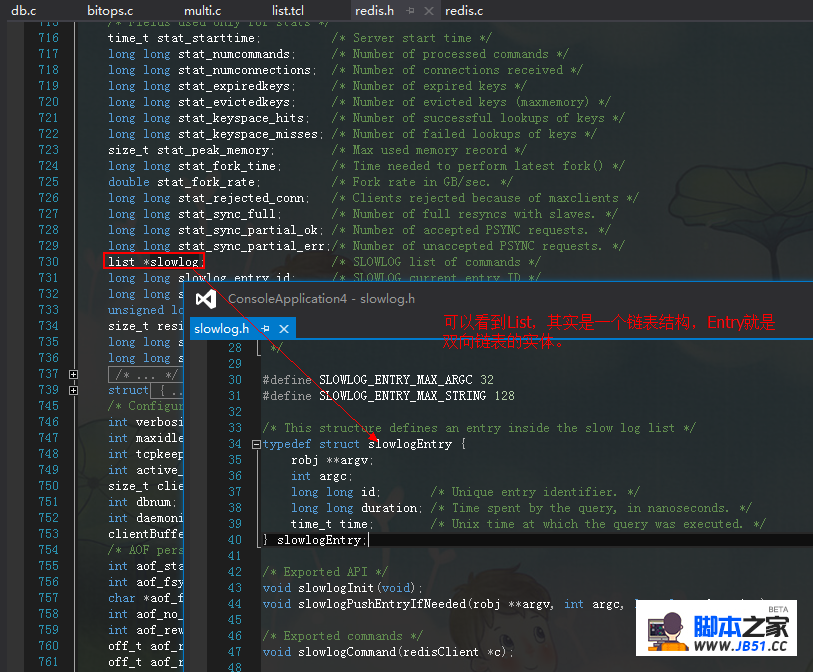
有了这个,我现在是不是可以找到所有生产线上哪些慢的command命令呢???这样大家就不会扯皮了。。。最后我们简单看下他们的源码,从源码
中你可以看到其实slowlog是用List实现的,而我们也知道在Redis中List是用“双向链表”实现的。
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。