
我们都知道,提高系统性能的最简单也最流行的方法之一其实就是使用缓存。我们引入缓存,相当于对数据进行了复制。每当系统数据更新时,保持缓存和数据源(如 MySQL 数据库)同步至关重要,当然,这也取决于系统本身的要求,看系统是否允许一定的数据延迟。
最常见的几种缓存策略、它们的优缺点以及使用场景,分别是:
- Cache-Aside
- Read-Through
- Write-Through
- Write-Behind
Cache-Aside 策略
Cache-Aside 可能是最常用的缓存策略。在这种策略下,应用程序(Application)会与缓存(Cache)和数据源(Data Source)进行通信,应用程序会在命中数据源之前先检查缓存。如下图所示:

我们来看一次请求数据的过程:
- 首先,应用程序先确定数据是否保留在缓存中;
- 如果数据在缓存中,也即
Cache hit,称作“缓存命中”。数据直接从缓存中读取并返回给客户端应用程序; - 如果数据不在缓存中,也即
Cache miss,称作“缓存未命中”。应用程序会从数据存储的地方,如 MySQL 数据源中读取该数据,并将数据存储在缓存中,然后将其返回给客户端。
Cache-Aside 策略特别适合“读多”的应用场景。使用 Cache Aside 策略的系统可以在一定程度上抵抗缓存故障。如果缓存服务发生故障,系统仍然可以通过直接访问数据库进行操作。
然而,这种策略并不能保证数据存储和缓存之间的一致性,需要配合使用其它策略来更新或使缓存无效。另外,首次请求数据时,总是会导致缓存未命中,这种情况下需要额外的时间来将数据加载到缓存中。为了解决这个问题,开发人员可以通过手动触发查询操作来对数据进行“预热”。
Read-Through 策略
在上面的 Cache-Aside 策略中,应用程序需要与缓存和数据源“打交道”,而在 Read-Through 策略下,应用程序无需管理数据源和缓存,只需要将数据源的同步委托给缓存提供程序 Cache Provider 即可。所有数据交互都是通过抽象缓存层完成的。
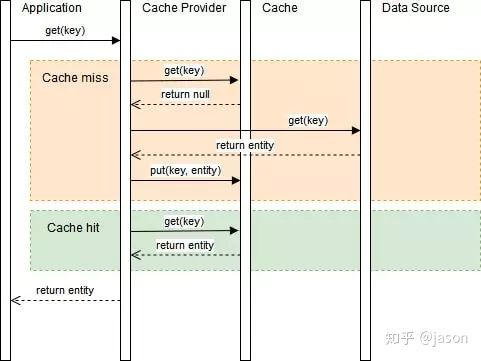
在进行大量读取时,Read-Through 可以减少数据源上的负载,也对缓存服务的故障具备一定的弹性。如果缓存服务挂了,则缓存提供程序仍然可以通过直接转到数据源来进行操作。
然而,首次请求数据时,总是会导致缓存未命中,并需要额外的时间来将数据加载到缓存中,相信大家都知道怎么处理了吧,还是“缓存预热”的老套路。Read-Through 适用于多次请求相同数据的场景。这与 Cache-Aside 策略非常相似,但是二者还是存在一些差别,这里再次强调一下:
- 在
Cache-Aside中,应用程序负责从数据源中获取数据并更新到缓存。 - 而在
Read-Through中,此逻辑通常是由独立的缓存提供程序支持。
原文地址:https://www.cnblogs.com/tracydzf
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。