
以下内容说的都是 python 2.x 版本
简介
- 基本概念
- Python “帮”你做的事情
- 推荐姿势
1、基本概念
我们看到的输入输出都是‘字符’(characters),计算机(程序)并不能直接处理,需要转化成字节数据(bytes),因为程序只能处理 bytes 数据。
例如:文件、网络传输等,处理的都是 bytes 数据——二进制数字。
1.1 ASCII / Unicode
孤立的 byte 是毫无意义的,所以我们来赋予他们含义。就引入‘字符集’的概念,‘字符集’就是一个码位(code point)对应的一个字符的表。
该表用于赋予 byte 意义。还需要知道一个点:因为 ASCII 字符集支持的字符太少,不能表示各个国家语言中的字符。所以就发明了
Unicode ——万国码,该字符集包含了你能用到的所有的字符。
1.2 Encode / Decode
在 python 中字符串分为两个对象:str 和 unicode
- str: a sequence of bytes
- unicode:a sequence of code point(码位——字符集中的数字)
unicode_obj.encode() ——> bytes ‘编码’(encode)
bytes_obj.decode() ——> unicode ‘解码’(decode)
UTF-8 是最流行的一种对 Unicode 进行传播和存储的编码方式。所以,多用它作为编码方式。
s = 'hello' # str
u = u'你好' # unicode
back_to_bytes = u.encode('utf-8')
back_to_utf8 = back_to_bytes.decode('utf-8') # 或 unicode(s,'utf-8')
1.3 声明编码
正如前面所说的,计算机只能操作 bytes,所以 Python 在编译原文件的时候,会先把源文件进行编码,默认以‘ASCII’进行编码。这就是为什么如果源文件中带有‘中文’,需要在源文件的起始行声明编码方式。
完成编码后,源码中的所有字符,都变成了 bytes 计算机就可以进行编译和处理了。编译过程:
- 读取文件
- 不同的文件,根据其声明的编码去解析为Unicode
- 转换为UTF-8字符串
- 针对UTF-8字符串,去分词
- 编译,创建Unicode对象(Python解释器处理)
根据这个过程,在自己的代码中也应该按照这个逻辑处理,意思是:
- 接收外部数据时,统一转化为Unicode
- 代码内部处理的都是Unicode
- 输出时统一转化为UTF-8(网络数据传输、文本输出)
参考:PEP 263 -- Defining Python Source Code Encodings
1.4 小结
- 程序中所有的输入和输出均为 byte
- 世界上的文本需要比 256 更多的符号来表现(ASCII是不够的)
- 你的程序必须能够处理 byte 和 unicode
- byte 流中不会包含编码信息(编码信息会在:文件的开头、协议中等地方声明)
Content-Type:text/html; charset=UTF-8 - 指明的编码有可能是错误的(出现乱码)
2、python “帮”你做的事情
在 python 中处理编码问题,会出现很多问题,这里就不一一列举。
这些问题大都是使用了不匹配的编码方式进行解码、编码造成的。而 python 为了语法更加简介,在一些内置方法中,使用了一些隐性转换。这种隐形的转换带了的便捷的同时也会带来一些非预期的错误。下面就一一道来。
2.1 a = "abc" + u"bcd"
a = "abc" + u"bcd",Python 会如此转换 "abc".decode(sys.getdefaultencoding()) 然后将两个 Unicode 字符合并。
2.2 两个内建方法str()和unicode(),
- str:something.encode(sys.getdefaultencoding())
- unicode:something.decode(sys.getdefaultencoding())
sys.getdefaultencoding()默认为:ASCII,这就是为什么str(u'中文')和unicode('中文')分别会报错:UnicodeEncodeError和UnicodeDecodeError。因为ASCII编码方式,编码/解码不了中文(支持的字符有限)。
2.3 print函数
print函数,会对输出的内容进行编码,这是因为:所谓的输出,也是从一个程序到另外一个程序。程序之间的交互都是都是传递 bytes。比方说print,就是把数据传递给 终端 ,终端也是个程序,所以print函数就把需要输出的内容编码成了 bytes,采用那种编码方式,就是
由sys.stdout.encoding参数决定的。
在交互环境下(python、ipython)输入的数据的编码则由sys.stdin.encoding参数决定。参考:What does python print() function actually do?
2.4 默认编码方式
python 的默认编发方式为 ASCII。
如何改变python的默认编码方式?:
import sys
# sys.setdefaultencoding() does not exist,here!
reload(sys) # Reload does the trick!
sys.setdefaultencoding('UTF8')
为什么要重载sys模块?
因为如果在编译.py文件的之前,改变默认编码,会影响Python的编译。
当编译完,再重载sys模块,它就是变成了第三方模块,可以随便更改,不回影响编译。setdefaultencoding()函数才可以调用。参考:Changing default encoding of Python?
3、推荐姿势
本片文章没有列举出常见的异常,因为如果看懂了上面所有的解释。再按照下面的姿势使用,那么 python2 中的编码问题,因该就不会再困扰你了。
-
Unicode 三明治:尽可能的让你程序处理的文本都为 Unicode 。如下图:
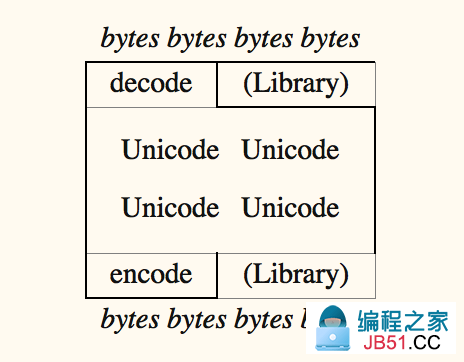
-
了解你的字符串。你应该知道你的程序中,哪些是 unicode,哪些是 byte,对于这些 byte 串。你应该知道,他们的编码是什么。(详情见上述小结第 4 条)
-
测试 Unicode 支持。使用一些奇怪的符号来测试你是否已经做到了以上几点。(测试看看你的程序是否支持中文)
参考
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。