
在上一篇文章Python基础之Scrapy简介中,简述了Scrapy的基本原理,安装步骤,创建项目以及如何通过Scrapy进行简单的爬虫,同时遗留了两个问题,即分页爬取,和异步内容爬取。本文以一个简单的爬取某股票网站为例,简述Scrapy在分页和接口数据爬取的相关应用,仅供学习分享使用,如有不足之处,还请指正。
Scrapy架构图
关于Scrapy架构图,如下所示: 绿线是数据流向

关于Scrapy架构各项说明,如下所示:
- Scrapy Engine(引擎): 负责 Spider、ItemPipeline、Downloader、Scheduler 中间的通讯, 信号、数据传递等。
- Scheduler(调度器): 它负责接受引擎发送过来的 Request 请求,并按照一定的方式进行 整理排列,入队,当引擎需要时,交还给引擎。
- Downloader(下载器):负责下载 Scrapy Engine(引擎)发送的所有 Requests 请求,并将 其获取到的 Responses 交还给 Scrapy Engine(引擎),由引擎交给 Spider 来处理,
- Spider(爬虫):它负责处理所有 Responses,从中分析提取数据,获取 Item 字段需要的 数据,并将需要跟进的 URL 提交给引擎,再次进入 Scheduler(调度器),
- Item Pipeline(管道):它负责处理 Spider 中获取到的 Item,并进行进行后期处理(详细 分析、过滤、存储等)的地方。
- Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能 的组件。
- Spider Middlewares(Spider 中间件):你可以理解为是一个可以自定扩展和操作引擎和 Spider 中间通信的功能组件(比如进入 Spider 的 Responses;和从 Spider 出去的 Requests)
目标分析
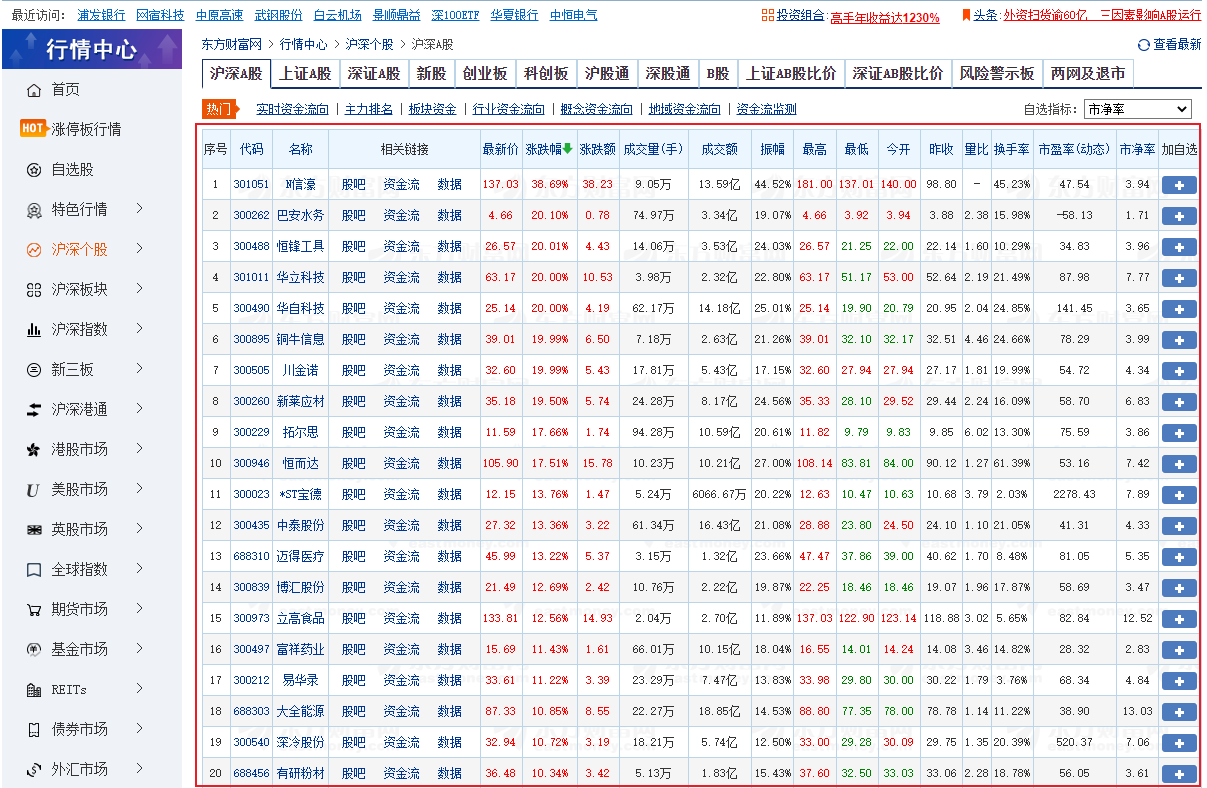
本次爬取的是某财富网站的沪深A股,共232页,如下所示:
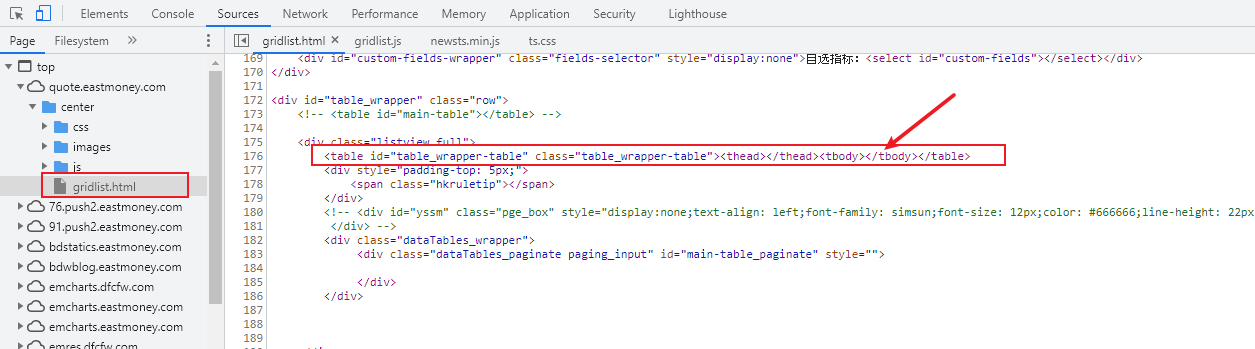
在Chrome浏览器,通过开发者工具(F12),进行分析,发现我们需要爬取的内容,均在id为table_wraper_table中,如下所示:

通过以上分析,似乎已经胜利在望,但通过查询源代码,发现网址请求到的页面中,table是空的,并没有我们想要的股票数据内容,如下所示:
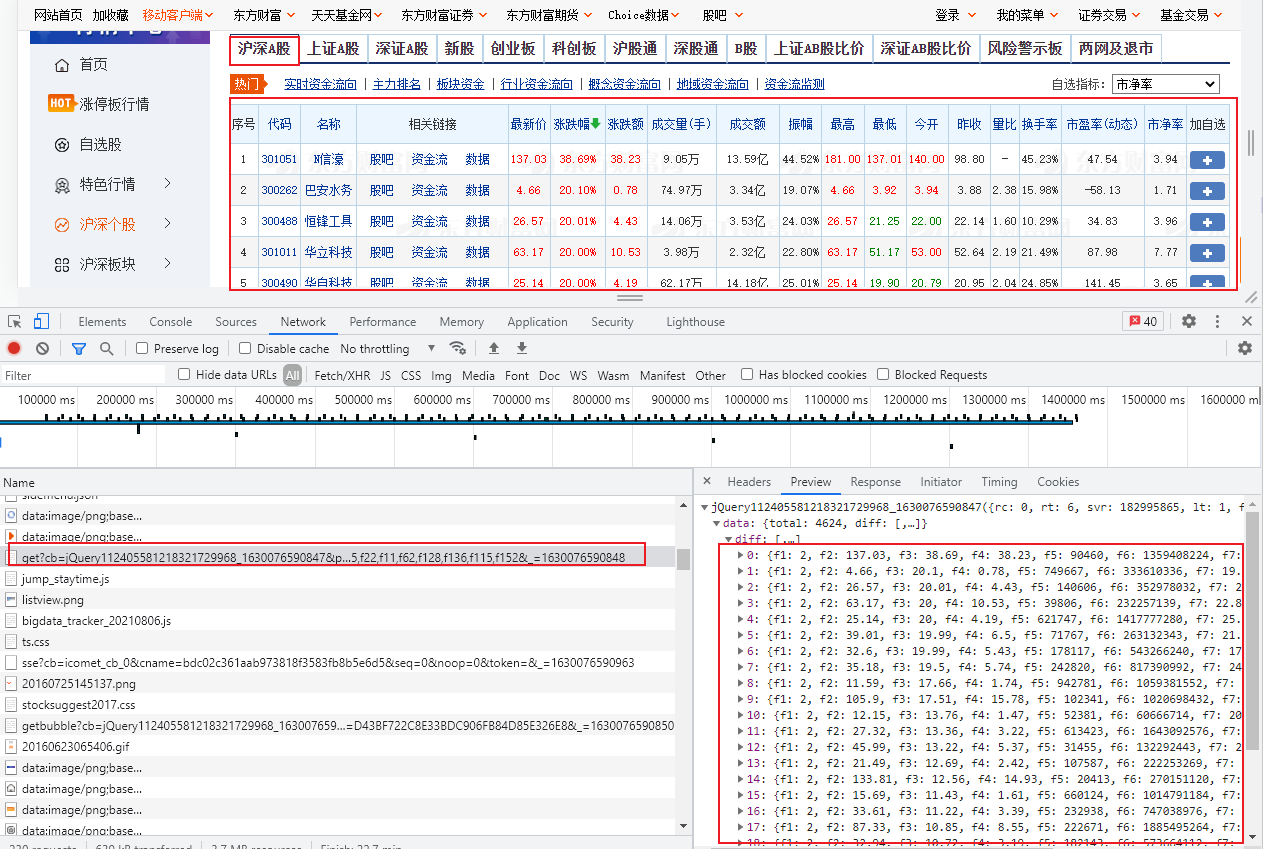
通过以上步骤的排查,说明所见即所得,有时也不一定通用。既然页面不是一次请求获取的,那么就可能是通过ajax的方式异步获取的,需要进一步排查Network,即网络请求信息。继续排查跟踪网络请求信息,发现股票信息是通过以下接口获取的,返回的是json格式的字符串,我们获取对应内容后,只需要解析json即可获取相应的数据,如下所示:
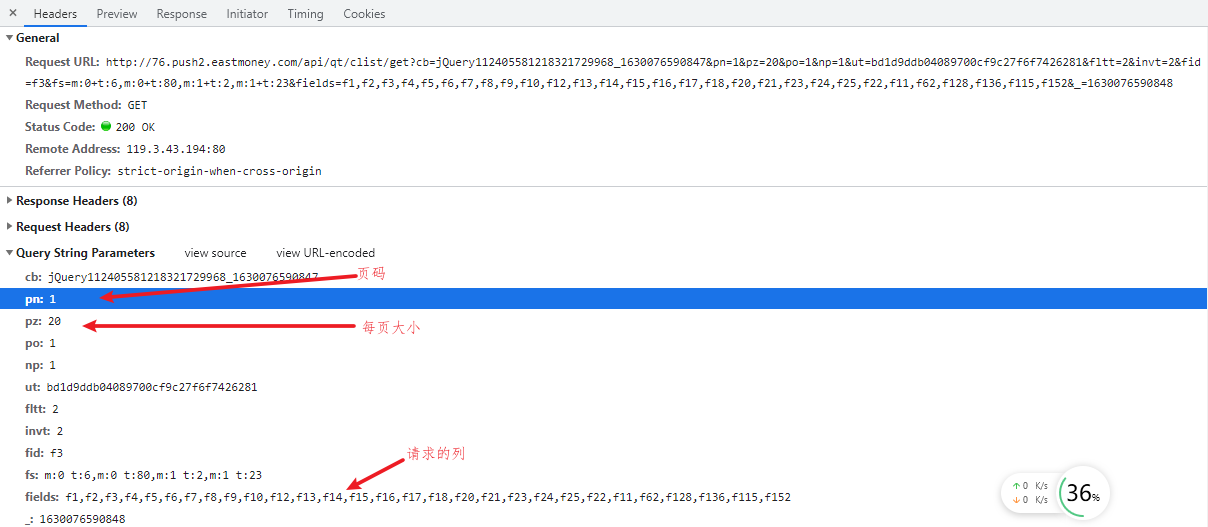
通过分析接口请求的url,发现对应的页码和每页请求条数,即可以变化的量,对于多页,则轮询并替换即可,如下所示:
创建爬虫
在之前stockstar项目的基础上,再次创建一个爬虫,如下所示:
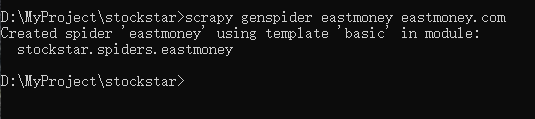
Scrapy爬虫开发
通过命令行创建项目后,基本Scrapy爬虫框架已经形成,剩下的就是业务代码填充。
定义爬取内容
定义需要爬取哪些字段内容,如下所示:
1 # Define here the models for your scraped items 2 # 3 See documentation in: 4 https://docs.scrapy.org/en/latest/topics/items.html 5 6 import scrapy 7 8 9 class StockstarItem(scrapy.Item): 10 """ 11 定义需要爬取的字段名称 12 13 define the fields for your item here like: 14 name = scrapy.Field() 15 stock_type = scrapy.Field() 股票类型 16 stock_id = scrapy.Field() 股票ID 17 stock_name = scrapy.Field() 股票名称 18 stock_price = scrapy.Field() 股票价格 19 stock_chg = scrapy.Field() 涨跌幅
定制业务逻辑
Scrapy的爬虫结构是固定的,定义一个类,继承自scrapy.Spider,类中定义属性【爬虫名称,域名,起始url】,重写父类方法【parse】,根据需要爬取的页面逻辑不同,在parse中定制不同的爬虫代码,如下所示:
EastmoneySpider(scrapy.Spider): 2 name = 'eastmoney' 3 allowed_domains = [eastmoney.com/'] 4 start_urls = [ 5 http://**.****.********.com/api/qt/clist/get?cb=jQuery112405581218321729968_1630076590847&pn=1&pz=20&po=1&np=1&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f136,f115,f152&_=1630076590848 6 index = 1 8 def parse(self,response): 9 item = StockstarItem() 10 text = response.text 11 text = text[text.find((') + 1:] 去掉小括号前面的 12 text = text[0:-2] 去掉小括号后面的 13 print(text) # 此处用于打印处理好的原始字符 14 obj = json.loads(text) 15 print(********************本次抓取第' + str(self.index) + 页股票********************) 16 data = obj[data17 total = data[total18 diffs = data[diff19 total_page = total / 20 20 if total % 20 > 0: 21 total_page += 1 如果求模大于0,则也码加1 22 for diff in diffs: 23 item[stock_type'] = 沪深A股24 item[stock_id'] = str(diff[f12]) 25 item[stock_namef1426 item[stock_pricef227 item[stock_chgf3']) + %28 yield item 29 当第一页解析完,进行下一页解析 30 self.index += 1 31 总页码:' + str(total_page)) 32 if self.index <= total_page: 33 next_page = http://**.****.******.com/api/qt/clist/get?cb=jQuery112405581218321729968_1630076590847&pn= str( 34 self.index) + &pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fields=f1,f11,f62,f128,1)">35 yield scrapy.Request(next_page,callback=self.parse,dont_filter=True) 36 else: 37 当前是最后一页')
注意:为了不泄露目标网站,爬取地址做了模糊处理
数据处理
在Pipeline中,对抓取的数据进行处理,本例为简便,在控制进行输出,如下所示:
StockstarPipeline: 2 process_item(self,item,spider): 3 str_item = 股票类型:'+item[']+ 股票代码: 股票名称: 股票价格: 股票涨跌幅: 4 print(str_item) 打印 5 self.save_data(str_item) 保存 6 return save_data(self,str_item): 9 10 保存数据 :param str_item: 保存的内容文件 12 :return: 13 14 with open(stocks.txt',autf-8) as f: 15 f.write(str_item+\n')
注意:在对item进行赋值时,只能通过item['key']=value的方式进行赋值,不可以通过item.key=value的方式赋值。
Scrapy运行
因scrapy是各个独立的页面,只能通过终端命令行的方式运行,格式为:scrapy crawl 爬虫名称,如下所示:
1 scrapy crawl eastmoney
结果展示
本文爬取的内容,存储在文本文件中,可以用于后续的进一步分析,如下所示:
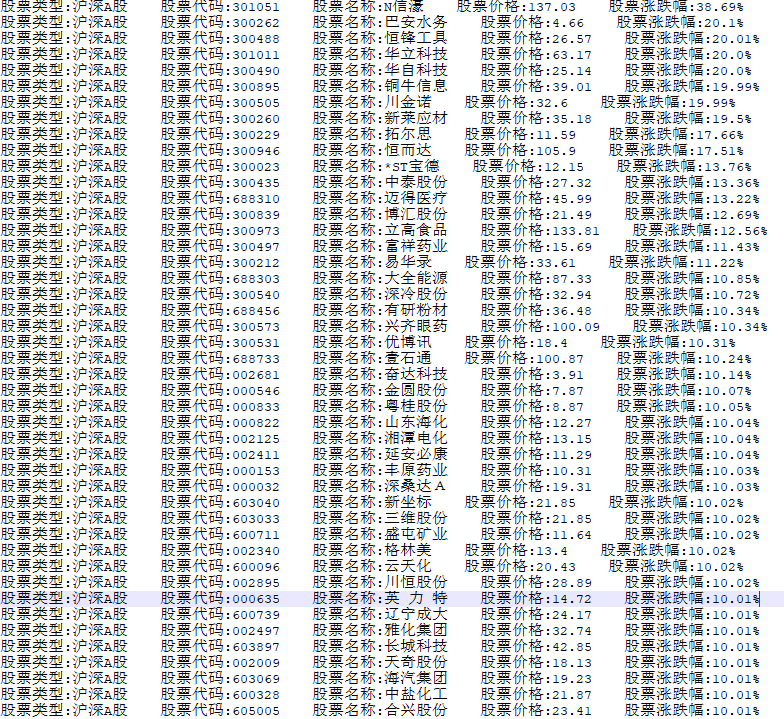
备注
以上就是Scrapy爬取异步内容,及多页爬取的简单介绍,希望能够抛转引玉,共同学习。
夏日南亭怀辛大
散发乘夕凉,开轩卧闲敞。
荷风送香气,竹露滴清响。
欲取鸣琴弹,恨无知音赏。
感此怀故人,中宵劳梦想。
原文地址:https://www.cnblogs.com/hsiang
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。