
《大数据最大难关之模糊检索,PostgreSQL如何攻克!》要点:
本文介绍了大数据最大难关之模糊检索,PostgreSQL如何攻克!,希望对您有用。如果有疑问,可以联系我们。
活动要写在最前面,因为本日的干货文章实在太长了!:)提醒超过20000字了.只好删减一些,详细阅读请看云栖社区头条.
云栖社区也有”小金人“了!送给3月云栖社区2016年第2-10期在线培训的8位CTO大神.目前,3月4日10:00-10:40,第2期《游族网络:如何运维千台以上游戏云服务器》正在火热报名.转发”小金人“到朋友圈,并在直播期间积极留言,我们将挑选优秀留言提问者赠送技术册本哦!

正文来了!感谢德哥的分享.重要的事情重复三遍:技术干货,技术干货,技术干货!
作者:阿里云数据库专家 德哥
来源:云栖社区
链接:https://yq.aliyun.com/articles/7444
转载分享请带上述版权声明!
大数据正在向我们奔来.尽管业务场景不会完全相同,但在其中一个最典型场景——模糊检索中,技术需求却出奇的一致.
好比说:
物联网,往往会产生大量的数据,除了数字数据,还有字符串类的数据,例如条形码,车牌,手机号,邮箱,姓名等.假设用户需要在大量的传感数据中进行模糊检索,甚至规则表达式匹配,有什么高效的办法呢?
医药,市面上发现了一批药品可能有问题,需要对药品条码进行规则表达式查找,找出复合条件的药品流向.但怎么才能在如此复杂的系统中,用高效办法来实现?
公安,侦查行动时,有可能需要线索的检索.如用户提供的残缺的电话号码,IP地址,QQ号码,微信号码等进行交叉搜索,根据这些信息加上时间的叠加,模糊匹配和关联,最终找出罪犯.但这个流程,可有高效办法?
相同的需求还有很多.几乎每一个模糊匹配的场景下,都必要正则表达式匹配,这和人脸拼图有点类似,我们已经看到强烈的需求已经产生.但技术方面,要怎么做更好?
在我看来:正则匹配和模糊匹配通常是搜索引擎的特长,但是如果你使用的是PostgreSQL数据库照样能实现,而且性能不赖,加上分布式方案 (譬如 plproxy,pg_shard,fdw shard,pg-xc,pg-xl,greenplum),处理百亿以上数据量的正则匹配和模糊匹配效果杠杠的,同时还不失数据库固有的功能,绝对是一举多得.
首先对应用场景进行一下分类,以及现有技术下能使用的优化手段.
.1. 带前缀的模糊查询,例如 like 'ABC%',在PG中也可以写成 ~ '^ABC'
可以使用btree索引优化,或者拆列用多列索引叠加bit and或bit or进行优化(只适合固定长度的端字符串,例如char(8)).
.2. 带后缀的模糊查询,例如 like '%ABC',在PG中也可以写成 ~ 'ABC$'
可以使用reverse函数btree索引,例如char(8)).
.3. 不带前缀和后缀的模糊查询,例如 like '%AB_C%',在PG中也可以写成 ~ 'AB.C'
可以使用pg_trgm的gin索引,例如char(8)).
.4. 正则表达式查询,例如 ~ '[\d]+def1.?[a|b|0|8]{1,3}'
可以使用pg_trgm的gin索引,例如char(8)).
PostgreSQL pg_trgm插件自从9.1开始支持模糊查询使用索引,从9.3开始支持规则表达式查询使用索引,大大提高了PostgreSQL在刑侦方面的才能.
代码见 https://github.com/postgrespro/pg_trgm_pro
pg_trgm插件的原理,将字符串前加2个空格,后加1个空格,组成一个新的字符串,并将这个新的字符串依照每3个相邻的字符拆分成多个token.
当使用规则表达式或者模糊查询进行匹配时,会检索出他们的近似度,再进行filter.
GIN索引的图例:
从btree检索到匹配的token时,指向对应的list,从list中存储的ctid找到对应的记录.
因为一个字符串会拆成很多个token,所以没插入一条记录,会更新多条索引,这也是GIN索引必要fastupdate的原因.
正则匹配是怎么做到的呢?
详见 https://raw.githubusercontent.com/postgrespro/pg_trgm_pro/master/trgm_regexp.c
实际上它是将正则表达式转换成了NFA格式,然后扫描多个TOKEN,进行bit and|or匹配.
正则组合如果转换出来的的bit and|or很多的话,就必要大量的recheck,性能也不能好到哪里去.
下面针对以上四种场景,实例讲解如何优化.
带前缀的模糊查询,例如char(8)).
例子,1000万随机发生的MD5数据的前8个字符.
带前缀的模糊查询,不使用索引必要5483毫秒.
带前缀的模糊查询,使用索引只必要0.5毫秒.
.2. 带后缀的模糊查询,例如char(8)).
带后缀的模糊查询,使用索引只必要0.5毫秒.
.3. 不带前缀和后缀的模糊查询,例如char(8)).
前后模糊查询,使用索引只必要3.8毫秒.
.4. 正则表达式查询,使用索引只必要108毫秒.
时间主要花费在排他上面.
检索了14794行,remove了14793行.大量的时间花费在无用功上,但是比全表扫还是好很多.
优化:
使用gin索引后,必要考虑性能问题,因为info字段被打散成了多个char(3)的token,从而涉及到非常多的索引条目,如果有非常高并发的插入,最好把gin_pending_list_limit设大,来提高插入效率,降低实时合并索引带来的RT升高.
使用了fastupdate后,会在每次vacuum表时,自动将pengding的信息合并到GIN索引中.
还有一点,查询不会有合并的动作,对于没有合并的GIN信息是使用遍历的方式搜索的.
压测高并发的性能:
修改配置,让数据库的autovacuum快速迭代合并gin.
创建一个测试函数,用来产生随机的测试数据.依照这个速度,一天能支持超过40亿数据入库.
接下来对比一下字符串分离的例子,这个例子适用于字符串长度固定,并且很小的场景,如果字符串长度不固定,这种办法没用.
适用splict的办法,测试数据不尽人意,所以还是用pg_trgm比较靠谱.(省略一图)
大数据量性能测试:
模拟分区表,每小时一个分区,每小时数据量5000万,一天12亿,一个月360亿.
生成插入SQL
性能指标,范围扫描,落到单表5000万的数据量内,毫秒级返回(详细看图).
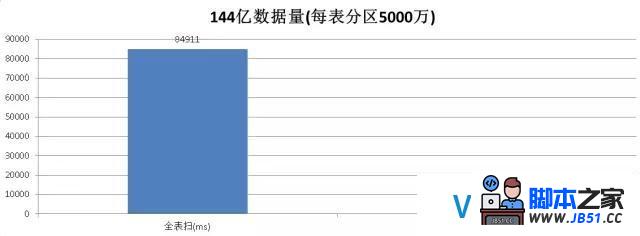
单表144亿的正则和模糊查询性能测试:
测试数据后续放出,分表后做到秒级是没有问题的.信心从何而来呢?
因为瓶颈不在IO上,主要在数据的recheck,把144亿数据拆分成29个5亿的表,并行执行,秒出是有可能的.
来看一个单表5亿的测试结果,秒出:
全表扫描必要,
性能对比图表:
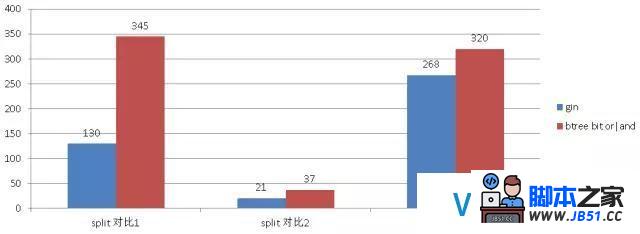
1000万数据对比
5亿数据对比
1000万数据btree bit or|and与gin对比
144亿分区表对比
大数据量的优化办法,例如百亿级别以上的数据量,如何能做到秒级的模糊查询响应.
对于单机,可以使用分区,同时使用并行查询,充分使用CPU的功能.或者使用MPP,SHARDING架构,利用多机的资源.
原则,减少recheck,尽量扫描搜索到最终必要的结果(大量扫描,大量remove checked false row,全表和索引都存在这种现象).
如果你能看到这行字,阐明是PG的真爱!云栖社区已经组建了 PG大牛群,2016学习PG技术,从社区开始,欢迎告诉我们你的需求!
欢迎参与《大数据最大难关之模糊检索,PostgreSQL如何攻克!》讨论,分享您的想法,编程之家PHP学院为您提供专业教程。
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。