
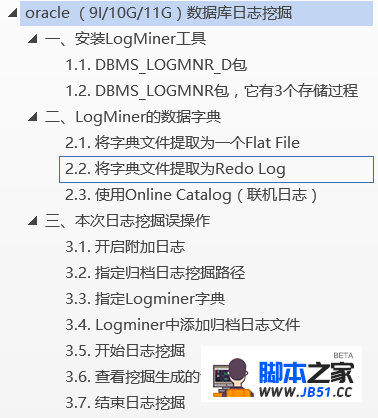
文档结构:
资料来自官方网站:
来自论坛:
来自朋友网站:
https://www.cnblogs.com/sky2088/p/9273351.html
Oracle 9i后可以分析DDL语句,另外还可分析得到一些必要的回滚SQL语句。LogMiner一个最重要的用途就是不用全部恢复数据库就可以恢复数据库的某个变化。该工具特别适用于调试、审计或者回退某个特定的事务。
LogMiner工具既可以用来分析在线日志,也可以用来分析离线日志文件,既可以分析本身自己数据库的重作日志文件,也可以用来分析其它数据库的重作日志文件。当分析其它数据库的重作日志文件时,需要注意的是,LogMiner必须使用被分析数据库实例产生的字典文件,而不是安装LogMiner的数据库产生的字典文件,另外,必须保证安装LogMiner数据库的字符集和被分析数据库的字符集相同。源数据库(Source Database)平台必须和分析数据库(Mining Database)平台一样。
一、安装LogMiner工具
在默认情况下,Oracle已经安装了LogMiner工具。若是没有安装,则可以运行下面两个脚本:
SQL>@$ORACLE_HOME/rdbms/admin/dbmslm.sql
SQL>@$ORACLE_HOME/rdbms/admin/dbmslmd.sql
这两个脚本必须均以SYS用户身份运行。其中第一个脚本用来创建DBMS_LOGMNR包,该包用来分析日志文件。第二个脚本用来创建DBMS_LOGMNR_D包,该包用来创建数据字典文件。若要使普通用户具有日志挖掘的权限,则可以执行如下的SQL进行赋权:
GRANT EXECUTE ON DBMS_LOGMNR TO username;
脚本执行完毕后,LogMiner包含两个PL/SQL包和几个视图:
1.1. DBMS_LOGMNR_D包
包括一个用于提取数据字典信息的过程,即DBMS_LOGMNR_D.BUILD()过程,还包含一个重建LogMiner表的过程,DBMS_LOGMNR_D.SET_TABLESPACE。在默认情况下,LogMiner的表是建在SYSTEM表空间下的。
1.2. DBMS_LOGMNR包,它有3个存储过程
ADD_LOGFILE(NAME VARCHAR2,OPTIONS NUMBER) 用来添加或删除用于分析的日志文件
START_LOGMNR(START_SCN NUMBER,END_SCN NUMBER,START_TIME NUMBER,END_TIME NUMBER,DICTFILENAME VARCHAR2,OPTIONS NUMBER) 用来开启日志分析,同时确定分析的时间或SCN窗口以及确认是否使用提取出来的数据字典信息
END_LOGMNR()存储过程用来终止分析会话,它将回收LogMiner所占用的内存
与LogMiner相关的数据字典视图:
V$LOGHIST:显示历史日志文件的一些信息
V$LOGMNR_DICTIONARY:因为LOGMINER可以有多个字典文件,所以该视图显示字典文件信息
V$LOGMNR_PARAMETERS:显示LOGMINER的参数
V$LOGMNR_LOGS:显示用于分析的日志列表信息
V$LOGMNR_CONTENTS:LOGMINER结果
二、LogMiner的数据字典
为了完全地转换Redo Log中的内容,LogMiner需要访问一个数据库字典。LogMiner使用该字典将Oracle内部的对象标识符和数据类型转换为对象名称和外部的数据格式。没有字典,LogMiner将使用16进制字符显示内部对象ID。
LogMiner提供了3种提取字典文件的方式:
① 将字典文件提取为一个Flat File(平面文件或中间接口文件)
② 将字典文件提取为Redo Log
③ 使用Online Catalog(联机日志)
下面分别介绍这3种方式:
2.1. 将字典文件提取为一个Flat File
(平面文件或中间接口文件)
为了将数据库字典信息提取为Flat File,需要使用带有STORE_IN_FLAT_FILE参数的DBMS_LOGMNR_D.BUILD程序。DBMS_LOGMNR_D.BUILD程序需要访问一个能够放置字典文件的目录。因为PL/SQL 程序通常不能直接访问用户目录,必须手动指定一个由DBMS_LOGMNR_D.BUILD程序使用的目录。为了指定该目录,必须修改初始化文件中的UTL_FILE_DIR参数:
ALTER SYSTEM SET UTL_FILE_DIR ='/home/oracle' SCOPE=SPFILE;
然后重新启动数据库。确保在创建Flat File文件的过程中,不能有DDL操作被执行。在创建Flat File文件时,数据库必须处于OPEN状态,然后执行DMBS_LOGMNR_D.BUILD程序:
EXECUTE DBMS_LOGMNR_D.BUILD('dictionary.ora','/home/oracle');
脚本执行完成后会在/home/oracle下生成一个dictionary.ora的文本文件。该文件中包含一系列的建表语句和插入语句。
2.2. 将字典文件提取为Redo Log
为了将字典文件提取为Redo日志,数据库必须处于OPEN状态,并且处于归档模式。将字典提取为Redo日志的过程中,数据库系统不能有DDL语句被执行。为了将字典提取为Redo日志,需要使用带有STORE_IN_REDO_FILES参数的DBMS_LOGMNR_D.BUILD程序:
SQL> EXECUTE DBMS_LOGMNR_D.BUILD(OPTIONS=>DBMS_LOGMNR_D.STORE_IN_REDO_LOGS);
需要注意的是,将字典文件提取为Redo文件的时候需要开启附加日志,如下所示:
ALTER DATABASE ADD SUPPLEMENTAL LOG DATA;
在这些Redo日志被归档之后,可以通过查询V$ARCHIVED_LOG视图来查询:
SELECT *
FROM V$ARCHIVED_LOG A
WHERE A.NAME IS NOT NULL
AND (A.DICTIONARY_BEGIN = 'YES' OR A.DICTIONARY_END = 'YES');
如果将字典信息提取为Redo文件,那么在使用DBMD_LOGMNR.ADD_LOGFILE指定所需要分析的日志文件时,需要将这些包含字典信息的Redo文件也添加进去。同时在使用START_LOGMNR开始分析时,需要指定DICT_FROM_REDO_LOGS的参数。
2.3. 使用Online Catalog(联机日志)
为了使LogMiner直接使用数据库当前使用的字典,在开始LogMiner时可以指定将联机目录作为字典源:
SQL> EXECUTE DBMS_LOGMNR.START_LOGMNR(OPTIONS => DBMS_LOGMNR.DICT_FROM_ONLINE_CATALOG);
使用联机目录,意味着不需要再提取字典文件,是开始分析日志的最快的方式。除了可以分析联机Redo日志外,还可以在和产生归档日志文件相同的系统上分析归档日志文件。然而,记住联机目录只能重建应用于表的最新版本上的SQL语句。一旦表被修改,联机目录就无法反映出表之前的版本。这就意味着LogMiner不能重建执行于表的旧版本上的SQL语句。
三、本次日志挖掘误操作
由于本次是oracle9I数据库,采用的是2.1将字典文件提取为一个Flat File这种办法,其他两种貌似行不通;挖掘是基于会话的,如果直接退出,就停止了挖掘,以下操作要在一个会话中进行,如果会话被异常退出,需要重新抽取字典到平面文件中以及以后的步骤。
注意:注意此种方法要事先设置好UTL_FILE_DIR,否则要设置了进行数据库重启,生产上要慎重。
3.1. 开启附加日志
SELECT SUPPLEMENTAL_LOG_DATA_MIN,SUPPLEMENTAL_LOG_DATA_PK,SUPPLEMENTAL_LOG_DATA_UI FROM V$DATABASE;
如果没有最小附加日志,开启如下:
SQL> ALTER DATABASE ADD SUPPLEMENTAL LOG DATA;

3.2. 指定归档日志挖掘路径
SELECT NAME FROM V$ARCHIVED_LOG WHERE FIRST_TIME between to_date('2018-12-03 9:00:00','yyyy-mm-dd hh24:mi:ss') and to_date('2018-12-03 17:00:00','yyyy-mm-dd hh24:mi:ss') order by 1;

3.3. 指定Logminer字典
Oracle 11g 指定Logminer字典有三种方法
1.Using the Online Catalog 使用在线目录
2.Extracting a LogMiner Dictionary to the Redo Log Files 抽取字典到redo日志文件中
3.Extracting the LogMiner Dictionary to a Flat File 抽取字典到平面文件中(需要设置UTL_FILE_DIR参数,本次之前已经设置好)
9I建议使用第三种,9I+版本建议使用前面两种方法。

EXECUTE DBMS_LOGMNR.START_LOGMNR(OPTIONS => DBMS_LOGMNR.DICT_FROM_ONLINE_CATALOG);
OR
EXECUTE DBMS_LOGMNR_D.BUILD( OPTIONS=> DBMS_LOGMNR_D.STORE_IN_REDO_LOGS);
OR
EXECUTE DBMS_LOGMNR_D.BUILD('dictionary.ora',' /oracle/utl',DBMS_LOGMNR_D.STORE_IN_FLAT_FILE); --本次用的这种方法


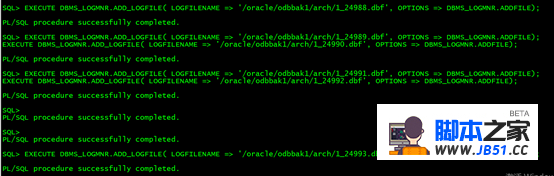
3.4. Logminer中添加归档日志文件
EXECUTE DBMS_LOGMNR.ADD_LOGFILE( LOGFILENAME => '/oracle/odbbak1/arch/1_24988.dbf',OPTIONS => DBMS_LOGMNR.ADDFILE);
EXECUTE DBMS_LOGMNR.ADD_LOGFILE( LOGFILENAME => '/oracle/odbbak1/arch/1_24989.dbf',OPTIONS => DBMS_LOGMNR.ADDFILE);
EXECUTE DBMS_LOGMNR.ADD_LOGFILE( LOGFILENAME => '/oracle/odbbak1/arch/1_24990.dbf',OPTIONS => DBMS_LOGMNR.ADDFILE);
EXECUTE DBMS_LOGMNR.ADD_LOGFILE( LOGFILENAME => '/oracle/odbbak1/arch/1_24991.dbf',OPTIONS => DBMS_LOGMNR.ADDFILE);
EXECUTE DBMS_LOGMNR.ADD_LOGFILE( LOGFILENAME => '/oracle/odbbak1/arch/1_24992.dbf',OPTIONS => DBMS_LOGMNR.ADDFILE);
EXECUTE DBMS_LOGMNR.ADD_LOGFILE( LOGFILENAME => '/oracle/odbbak1/arch/1_24993.dbf',OPTIONS => DBMS_LOGMNR.ADDFILE);
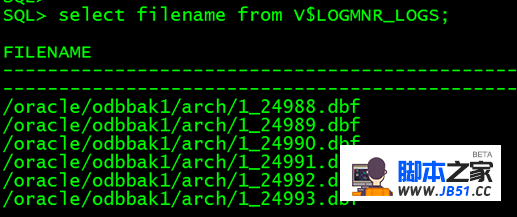
select filename from V$LOGMNR_LOGS;
3.5. 开始日志挖掘
前面两种对应的是如下语句(11g用的1,2两种方法,本次第三句)
EXECUTE DBMS_LOGMNR.START_LOGMNR(OPTIONS => DBMS_LOGMNR.DICT_FROM_ONLINE_CATALOG);
OR
EXECUTE DBMS_LOGMNR.START_LOGMNR(OPTIONS => DBMS_LOGMNR.DICT_FROM_REDO_LOGS );
OR
EXECUTE DBMS_LOGMNR.START_LOGMNR(DICTFILENAME =>'/oracle/utl/dictionary.ora');

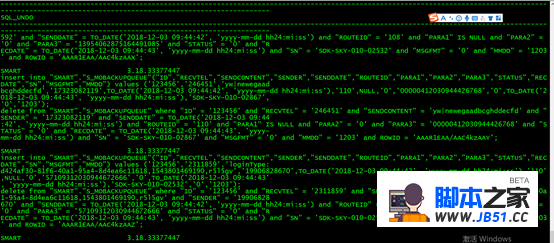
3.6. 查看挖掘生成的语句
SELECT username AS USR,(XIDUSN || '.' || XIDSLT || '.' || XIDSQN) AS XID,
SQL_REDO,SQL_UNDO FROM V$LOGMNR_CONTENTS WHERE username IN ('SMART') where rownum <=2;
把整个挖掘结果存进一张表,方便查询
create table logtab as select * from v$logmnr_contents;
select *
from sys.logtab
where username = 'SMART'
AND lower(SQL_REDO) LIKE '%s_sms_template_db%'

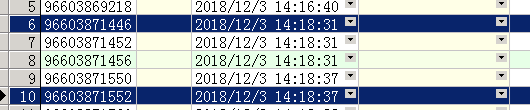

经排查,是业务人员在14:38进行表的删除和重建,并且机器名为MD177
3.7. 结束日志挖掘
EXECUTE DBMS_LOGMNR.END_LOGMNR(); --此句是基于会话的,如果直接退出,就停止了挖掘。
ALTER DATABASE drop SUPPLEMENTAL LOG DATA;
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。