
1、字符集
字符集实质上是将字符表示为数值编码的一组比特序列。
Oracle中常用的字符集包括US7ASCII、WE8ISO8859P1、ZHS16GBK、AL32UTF8等。遵循以下命名规则:
<Language><bit size><encoding>
<语 言><比特数><编码>
ZHS 16 GBK
如果只需要存储英文信息,那么选择US7ASCII作为字符集就可以;但是如果要存储中文,那么我们就需要选择能够支持中文的字符集(如ZHS16GBK);如果需要存储多国语言文字,那就要选择UTF8了,但是需要额外的存储空间和网络传输。
当一种字符集(字符集A)的编码数值包含另一种字符集(字符集B)的所有编码数值,并且两种字符集相同编码数值代表相同的字符时,则字符集A是字符集B的超级,或称字符集B是字符集A的子集。由于US7ASCII是最早的Oracle数据库编码格式,因此有许多字符集是US7ASCII的超集,例如WE8ISO8859P1、ZHS16GBK、AL32UTF8。
Oracle的字符集设置包含3个部分:服务器端字符集、客户端字符集以及客户端应用字符集。
1.1、服务器端字符集
在创建数据库时,可以指定字符集(CHARACTER SET)和国家字符集(NATIONAL CHARACTER SET)。
字符集用来存储CHAR、VARCHAR2、CLOB、LONG等类型数据;标示诸如表名、列名以及 PL/SQL变量等; SQL和PL/SQL程序单元等。
国家字符集用以存储NCHAR、NVARCHAR2、NCLOB等类型数据。
使用DBCA创建数据库时,在以下界面选择字符集和国家字符集。
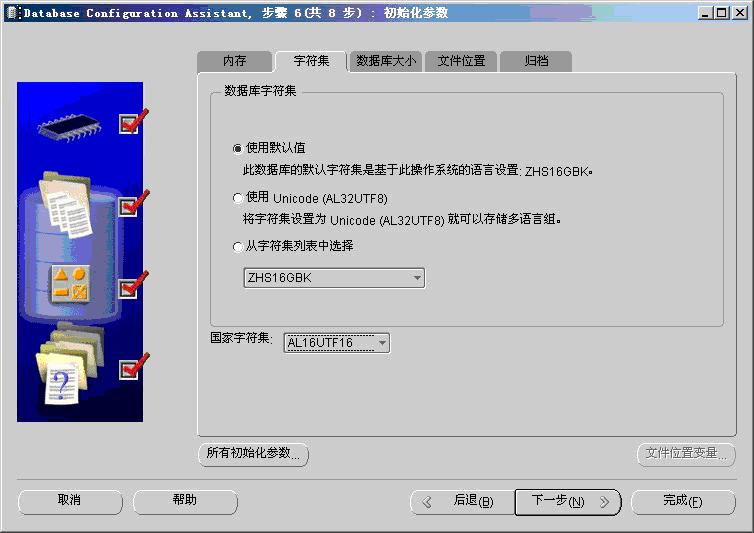
数据库字符集实际上说明这个数据库所能处理的字符的集合及其编码方式,由于字符集选定后再进行更改会有诸多的限制,所以在数据库创建时一定要考虑清楚后再选择。
可以查询以下数据字典或视图查看字符集设置情况:
nls_database_parameters、sys.props$、v$nls_parameters
查询结果中NLS_CHARACTERSET表示字符集,NLS_NCHAR_CHARACTERSET表示国家字符集。
还有下面一种比较直观的查询方法:
SQL> select USERENV ('language') from dual;
USERENV ('LANGUAGE')
----------------------------------------------------
AMERICAN_AMERICA.US7ASCII
1.2、客户端字符集
客户端字符集定义了客户端字符数据的编码方式,任何发自或发往客户端的字符数据均使用客户端定义的字符集编码。客户端字符集是通过设置NLS_LANG参数来设定的。
NLS_LANG=<language>_<territory>.<client character set>
其中,Language是语言,显示Oracle消息、校验、日期命名;Territory是地区,指定默认日期、数字、货币等格式;Client character set:指定客户端将使用的字符集。
NLS_LANG中真正影响字符集设置的是第三部分,如果设置与服务器字符集不同,在传输过程中需要进行字符集转换。转换是Oracle自动进行的,但是可能会产生数据丢失。
客户端字符集的设置方法如下:
Windows:HKEY_LOCAL_MACHINE\SOFTWARE\ORACLE\KEY_OraDb10g_home1下的NLS_LANG项;或者在CMD中设置环境变量(优先级高,但只作用于当前窗口):
C:\ > set NLS_LANG=SIMPLIFIED CHINESE_CHINA.ZHS16GBK
Unix:设置环境变量NLS_LANG
$NLS_LANG=“simplified chinese”_china.zhs16gbk
$export NLS_LANG
1.3、客户端应用字符集
客户端应用,如SQLPLUS、CMD、NOTEPAD等能够显示什么样的字符取决于客户端操作系统语言环境。客户端能够显示什么字符,就可以在应用中录入这些字符。字符能否在数据库中正常存储,只与另外的两个字符集设置相关。
2、一些测试
测试环境:
服务器端Windows Server2003,Oracle10G;
客户端Windows XP,简体中文。在CMD中右键“属性”查看代码页:
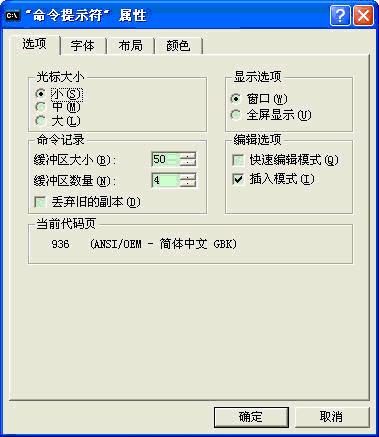
2.1、测试一
条件:客户端字符集与数据库字符集相同,与客户端应用字符集不同。
设置客户端字符集:
C:\Documents and Settings\dongxuyang>set NLS_LANG=AMERICAN_AMERICA.US7ASCII
查看数据库服务器端字符集:
SQL> conn scott/tiger@us7
Connected.
SQL> select * from nls_database_parameters where parameter='NLS_CHARACTERSET';
PARAMETER VALUE
------------------------------ ----------------------------------------
NLS_CHARACTERSET US7ASCII
创建测试表:
SQL> create table test(v1 varchar2(10));
Table created.
SQL> insert into test values('中国');
1 row created.
SQL> select * from test;
V1
----------
中国
数据的存取与显示都正确,好像没有什么问题,但是US7ASCII字符集只定义了128个符号,并不支持汉字。查看一下实际存储的内容:
SQL> select dump(v1,1016) from test;
DUMP(V1,1016)
--------------------------------------------------------------------------------
Typ=1 Len=4 CharacterSet=US7ASCII: d6,d0,b9,fa
由于Oracle检查数据库与客户端的字符集设置是同样的(US7ASCII),那么数据在客户端与数据库之间的存取过程中将不发生任何转换。使用Oracle10G提供的Locale Builder工具查看“中国”在输入系统中(ZHS16GBK)的编码如下:
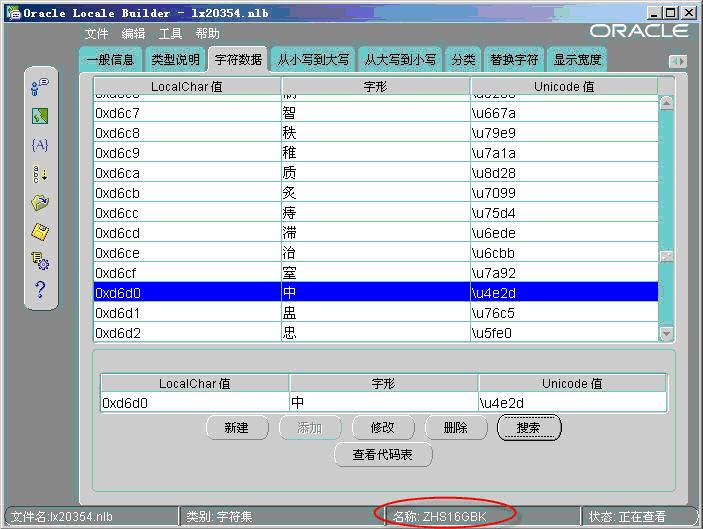
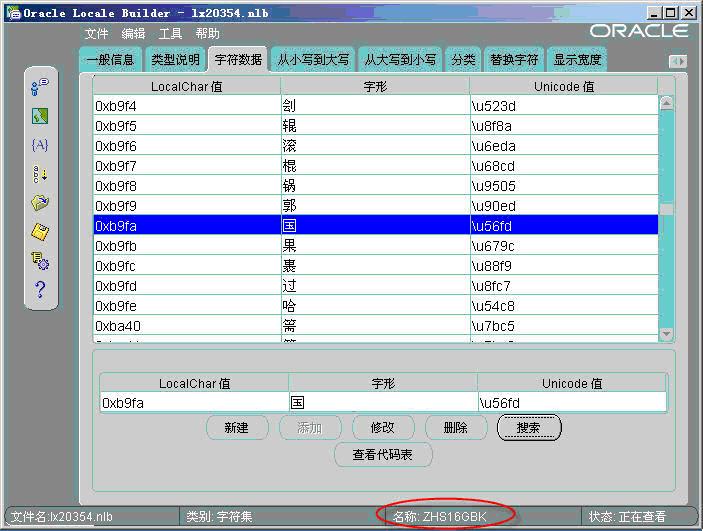
显然,Oracle直接将“中国”的ZHS16GBK内码(0xd6d0和0xb9fa)存入了US7ASCII字符集中。
同样在select查询语句中,Oracle将数据库中的编码直接传输到客户端而不进行转换,客户端操作系统(ZHS16GBK)正好能识别为“中国”。
这种使用方式表面上好像没有问题,实际上却可能存在隐患。例如,在应用 length或substr等字符串函数时,就可能得到意外的结果。
SQL> select length(v1) from test;
LENGTH (V1)
------------------
4
如果使用ZHS16GBK存储,结果为2。
2.2、测试二
条件:客户端字符集与客户端应用字符集相同,与数据库字符集不同。
设置客户端字符集为ZHS16GBK:
C:\Documents and Settings\dongxuyang>set NLS_LANG=AMERICAN_AMERICA.ZHS16GBK
查看之前录入的数据:
SQL> conn scott/tiger@us7
Connected.
SQL> select * from test;
V1
--------------------
VP9z
由于Oracle检查发现数据库设置的字符集与客户端配置字符集不同,它将对数据进行字符集的转换。
数据库中实际存放的数据为 0xD6(11010110)、0xD0(11010000)、0xB9(10111001)、0xFA(11111010)。US7ASCII是一个7bit的字符集,存储在8bit的字节中, Oracle忽略各字节的最高bit,则D6(11010110)就变成了 0x56(01010110),在ZHS16GBK中代表数字符号“V”(当然在其它字符集中也是“V”)。
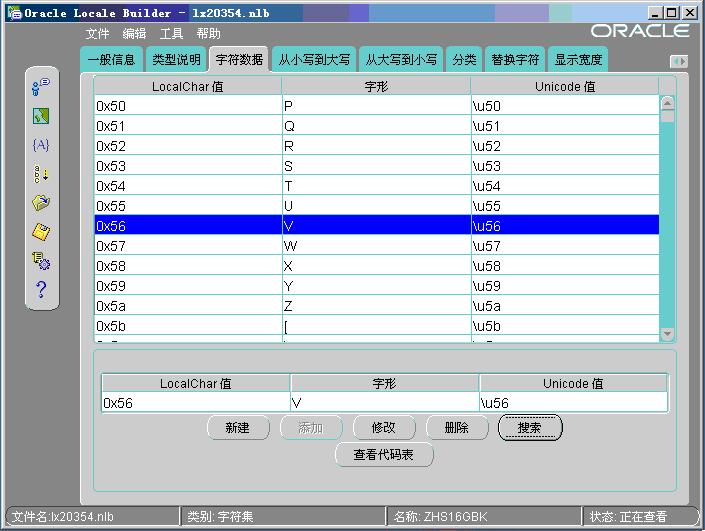
其它3个字节也一样进行转换,这样“中国”就变成了“VP9z”。
此时,再插入一个记录“中国”:
SQL> insert into test values('中国');
1 row created.
SQL> select * from test;
V1
--------------------
VP9z
??
同样,Oracle检查发现数据库设置的字符集与客户端不一致,插入数据时需要进行转换。但字符集ZHS16GBK中的“中国”两字在US7ASCII中没有对应的字符,所以Oracle用统一的“替换字符”插入数据库,即“?”,编码为0x3F(00111111)。
SQL> select dump(v1,fa
Typ=1 Len=2 CharacterSet=US7ASCII: 3f,3f
此时,输入的信息实际上已经丢失。不管字符集设置如何改变,第二行查询的结果都是两个“?”(注意是2个,而不是4个)。
如果再次更改客户端字符集为US7ASCII:
C:\Documents and Settings\dongxuyang>set NLS_LANG=AMERICAN_AMERICA.US7ASCII
SQL> conn scott/tiger@us7
Connected.
SQL> select * from test;
V1
----------
中国
??
可以显示用US7ASCII插入的“中国”,而用ZHS16GBK插入的“中国”实际上已存储为两个“?”,编码为0x3F。
2.3、测试三
条件:更改服务器字符集为ZHS16GBK
数据库创建后通常不建议更改字符集,在此只做测试使用。更改前进行全库备份。
SQL> connect sys/password@us7 as sysdba;
Connected.
SQL> update props$ set value$='ZHS16GBK' where name='NLS_CHARACTERSET';
1 row updated.
SQL> commit;
Commit complete.
SQL> select * from nls_database_parameters where parameter='NLS_CHARACTERSET';
PARAMETER
------------------------------------------------------------
VALUE
--------------------------------------------------------------------------------
NLS_CHARACTERSET
ZHS16GBK
关闭数据库,重新启动。
客户端字符集与数据库字符集以及客户端应用字符集三者相同
设置客户端字符集为ZHS16GBK:
C:\Documents and Settings\dongxuyang> SET NLS_LANG=AMERICAN_AMERICA.ZHS16GBK
SQL> conn scott/tiger@us7
Connected.
SQL> select * from test;
V1
--------------------
中国
??
SQL> select dump(v1,3f
结果与“测试一”相同,这是因为客户端字符集与数据库字符集相同,不需要转换;同时客户端应用可以显示中文。
此时再插入一行数据:
SQL> insert into test values('中国');
1 row created.
SQL> commit;
Commit complete.
SQL> select * from test;
V1
--------------------
中国
??
中国
SQL> select dump(v1,3f
Typ=1 Len=4 CharacterSet=US7ASCII: d6,fa
同样可以正确显示新插入的一行。
数据库字符集与客户端应用字符集相同,与客户端字符集不同
更改客户端字符集为US7ASCII:
C:\Documents and Settings\dongxuyang>set NLS_LANG=AMERICAN_AMERICA.US7ASCII
SQL> conn scott/tiger@us7
Connected.
SQL> select * from test;
V1
----------
??
??
??
由于Oracle检查发现数据库字符集为ZHS16GBK而客户端字符集为US7ASCII,需要进行字符集转换。
第一行与第三行的汉字“中”与“国”在客户端字符集US7ASCII中没有对应字符,所以转换为“替换字符”。第二行数据在数据库中存的就是两个“?”号。在客户端显示的三行都是两个“?”号,但在数据库中存储的内容却是不同的。
再次插入一行数据:
SQL> insert into test values('中国');
1 row created.
SQL> commit;
Commit complete.
SQL> select * from test;
V1
----------
??
??
??
VP9z
SQL> select dump(v1,fa
Typ=1 Len=2 CharacterSet=US7ASCII: 3f,fa
Typ=1 Len=4 CharacterSet=US7ASCII: 56,50,39,7a
在客户端字符集设置为US7ASCII时,向字符集为ZHS16GBK的数据库中插入“中国”,需要进行字符转换。“中国”的ZHS16GBK编码为D6(11010110)、D0(11010000)和B9(10111001)、FA(11111010)。由于US7ASCII为7bit编码,Oracle将这两个汉字当作四个字符并忽略各字节的最高位,从而存入数据库的编码就变成了0x56(01010110)、0x50(01010000)与0x39(00111001)、0x7A(01111010),也就是“VP9z”,原始信息被改变了。
此时,即使再将客户端字符集改为与数据库字符集相同,最新插入的数据(第四个“中国”)也不能再还原了。
C:\Documents and Settings\dongxuyang>set NLS_LANG=AMERICAN_AMERICA. ZHS16GBK
QL> conn scott/tiger@us7
Connected.
SQL> select * from test;
V1
--------------------
中国
??
中国
VP9z
为了在使用Oracle时少一些字符集的问题,建议使用以下设置:
l 创建数据库时选择当前与将来都能满足需求的字符集;
l 客户端设置为操作系统默认的字符集
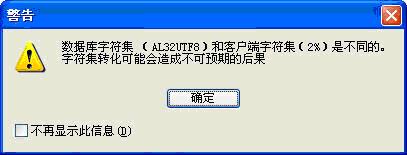
但即使按照以上设置,如果客户端字符集与数据库字符集不相同,就会产生转换;因而可能产生信息丢失。如数据库字符集为AL32UTF8,客户端字符集为ZHS16GBK时,使用PL/SQL Developer 8登陆时会提示以下警告信息:
3、更改数据库字符集
数据库字符集在创建后原则上不能更改。如果需要修改字符集,通常需要导出数据库数据,重建数据库,再导入数据库数据的方式来转换。
也可以通过ALTER DATABASE CHARACTER SET语句修改字符集,但只有新的字符集是当前字符集的超集时才能修改数据库字符集。
SQL> select userenv('language') from dual;
USERENV('LANGUAGE')
----------------------------------------------------
SIMPLIFIED CHINESE_CHINA.ZHS16GBK
SQL> alter database character set ZHS16CGB231280;
alter database character set ZHS16CGB231280
*
ERROR 位于第 1 行:
ORA-12712: 新字符集必须为旧字符集的超集
上文“测试三”中使用了修改props$的方法修改数据库字符集,实际上该方法存在许多隐患。以下测试修改数据库字符集的过程,以SYS登录:
SQL> select * from props$ where name='NLS_CHARACTERSET';
NAME
------------------------------------------------------------
VALUE$
--------------------------------------------------------------------------------
COMMENT$
--------------------------------------------------------------------------------
NLS_CHARACTERSET
US7ASCII
Character set
SQL> show user
USER is "SYS"
SQL> shutdown immediate
Database closed.
Database dismounted.
ORACLE instance shut down.
SQL> startup nomount
ORACLE instance started.
Total System Global Area 180355072 bytes
Fixed Size 788028 bytes
Variable Size 145750468 bytes
Database Buffers 33554432 bytes
Redo Buffers 262144 bytes
SQL> alter database mount;
Database altered.
打开跟踪功能:
SQL> alter session set sql_trace=true;
Session altered.
SQL> alter system enable restricted session;
System altered.
SQL> alter system set job_queue_processes=0;
System altered.
SQL> alter system set aq_tm_processes=0;
System altered.
SQL> alter database open;
Database altered.
SQL> alter database character set ZHS16GBK;
alter database character set ZHS16GBK
*
ERROR at line 1:
ORA-12716: Cannot ALTER DATABASE CHARACTER SET when CLOB data exists
数据库中存在CLOB字段时不允许修改字符集,可以先删除这些表,修改字符集后再重建。
SQL> truncate table METASTYLESHEET;
Table truncated.
同样删除以下表:
SQL> truncate table RULE$;
Table truncated.
SQL> truncate table WRH$_SQLTEXT;
Table truncated.
SQL> truncate table WRI$_DBU_FEATURE_USAGE;
Table truncated.
SQL> truncate table WRI$_DBU_FEATURE_METADATA;
Table truncated.
SQL> truncate table WRI$_DBU_HWM_METADATA;
Table truncated.
SQL> truncate table DMSYS.DM$PMML_DTD;
Table truncated.
SQL> truncate table MDSYS.SDO_GEOR_XMLSCHEMA_TABLE;
Table truncated.
SQL> truncate table SYSMAN.MGMT_JOB_OUTPUT;
Table truncated.
修改数据库字符集:
SQL> alter database character set ZHS16GBK;
Database altered.
SQL> ALTER SESSION SET SQL_TRACE=False;
Session altered.
SQL> disconn
Disconnected from Oracle Database 10g Enterprise Edition Release 10.1.0.2.0 - Production
With the Partitioning,OLAP and Data Mining options
SQL> exit
在初始化参数user_dump_dest指定的目录下找到最新的跟踪文件,可以看到以上过程主要涉及了12个基本表。因此,“测试三”中的方法只是进行了很小一部分的操作。
update col$ set charsetid = :1 where charsetform = :2
update argument$ set charsetid = :1 where charsetform = :2
update collection$ set charsetid = :1 where charsetform = :2
update attribute$ set charsetid = :1 where charsetform = :2
update parameter$ set charsetid = :1 where charsetform = :2
update result$ set charsetid = :1 where charsetform = :2
update partcol$ set spare1 = :1 where charsetform = :2
update subpartcol$ set spare1 = :1 where charsetform = :2
update props$ set value$ = :1 where name = :2
update "SYS"."KOTAD$" set SYS_NC_ROWINFO$ = :1 where SYS_NC_OID$ = :2
update seq$ set increment$=:2,minvalue=:3,maxvalue=:4,cycle#=:5,order$=:6,cache=:7,highwater=:8,audit$=:9,flags=:10 where obj#=:1
update kopm$ set metadata = :1, length = :2 where name='DB_FDO'
4、导入与导出
Import / Export是Oracle数据库导入与导出的一对工具。
4.1导出过程
在Export过程中,如果数据库字符集与Export用户会话字符集(NLS_LANG)不一致,则会发生字符集转换,并在导出文件的头部几个字节中存储Export用户会话字符集的ID号。在这个转换过程中可能发生数据的丢失。
例如:源数据库使用ZHS16GBK,而Export用户会话字符集使用US7ASCII。在这个转换过程中,中文字符在US7ASCII中不能够找到对等的字符,所以所有中文字符都会丢失而变成“?? ”形式,这样转换后生成的导出文件已经发生了数据丢失。
因此如果想正确导出源数据库数据,则Export过程中用户会话字符集应等于源数据库字符集或是源数据库字符集的超集。
4.2导入过程
查看导出文件的字符集设置:
导出文件的第2和第3个字节记录了文件的字符集。如果文件不大,可以用UltraEdit打开(16进制方式),然后用以下SQL查出它对应的字符集:

SQL> select nls_charset_name(to_number('0354','xxxx')) from dual;
ZHS16GBK
确定导入session的字符集,即导入Session使用的NLS_LANG环境变量。IMP进程读取导出文件字符集ID,和导入进程的NLS_LANG进行比较。如果导出文件字符集和导入Session字符集相同,那么在这一步骤内就不需要转换;否则,就需要把数据转换为导入Session使用的字符集。
可以看出,导入数据到数据库过程中发生两次字符集转换:导入文件字符集与导入Session使用的字符集之间的转换;导入Session字符集与数据库字符集之间的转换。
当数据库字符集不等于EXP过程中NLS_LANG参数,且数据库字符集是EXP过程中NLS_LANG的子集才能保证导出文件正确,其他情况则导出文件字符乱码。
导出文件字符集(EXP过程中NLS_LANG)不等于IMP过程中NLS_LANG字符集,且导出文件字符集是IMP过程中NLS_LANG的子集才能保证第一次转换正常;否则,出现乱码。
如果第一次转换正常,IMP过程中NLS_LANG字符集是目标数据库字符集的子集或相同才能保证第二次转换正常,否则第二次转换中出现乱码。
Done.
原文地址:https://tonydong.blog.csdn.net
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。