
目录
问题引出
人们经常把CNN看做黑箱,所以CNN到底干了些什么
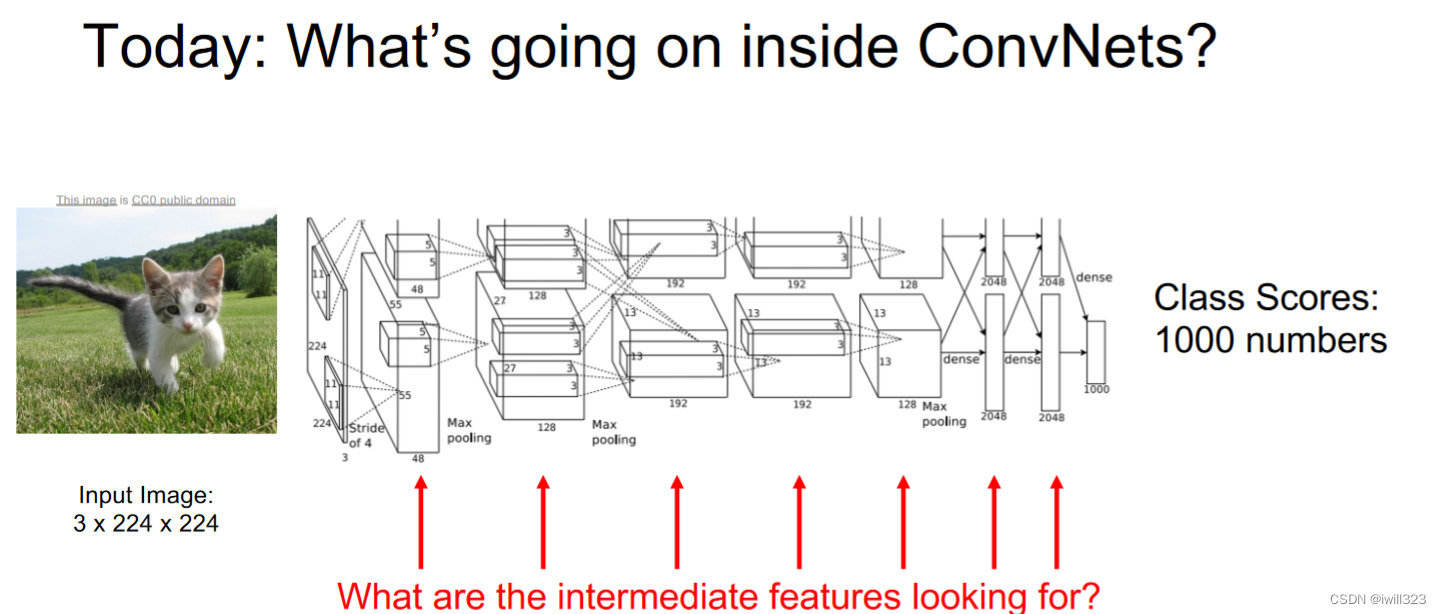
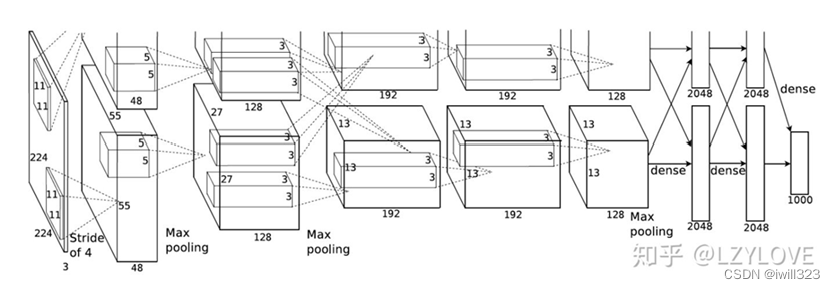
可视化模型学到了什么
可视化卷积核
通过可视化卷积核,知道卷积核在寻找什么。让模板向量和另一个向量相乘,得到标量结果,当这两个向量匹配(match up)的时候,结果最大化(比如,让一个向量与自己相乘,结果最大)。
比如,将AlexNet中第一层64个尺寸为3*11*11的卷积核展示位64个11*11、3通道的图片。
可以看到,几个模型中第一层卷积核都在寻找有向边(oriented edge)


可视化最后一层的特征
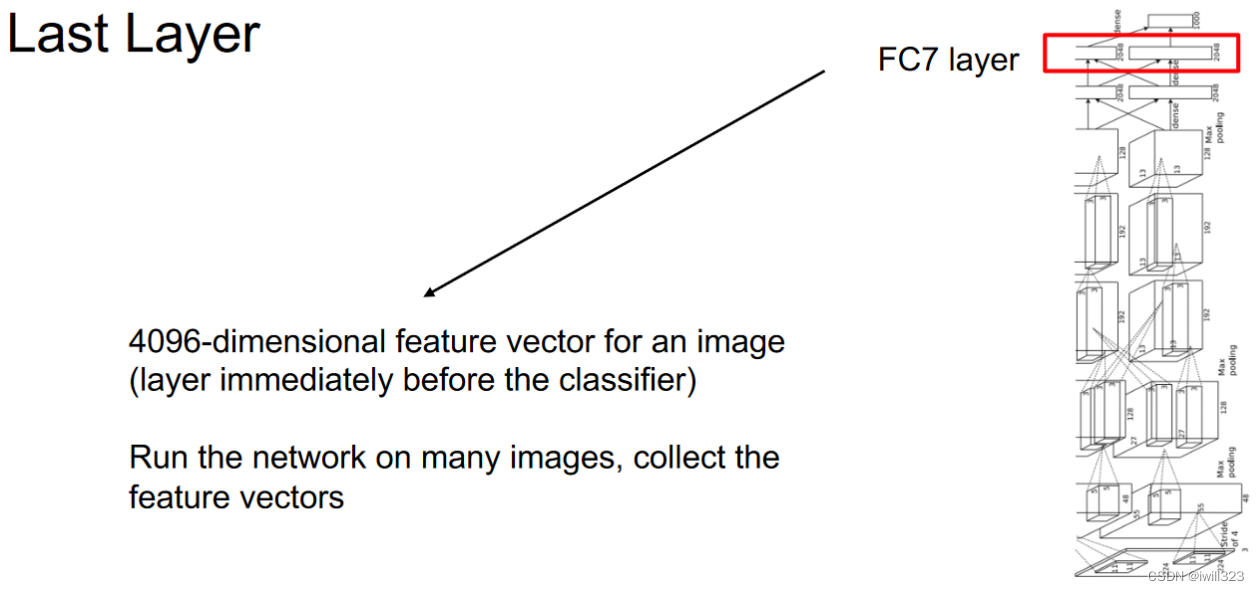
近邻法
将一些图片送入CNN,收集他们在最后一层的4096维特征向量,用L2近邻法将这些特征向量与第一列(红线左侧)测试图片的特征向量比较,红线右侧是得到的近邻。观察第二行的大象,红线右侧第三个大象位于右侧,而测试图片位于左侧,按道理讲他们的像素几乎完全不同(almost entirely different),但是特征向量差别不大,据此Justin认为特征向量捕捉的是图片的语义内容

维度压缩
mnist数据集图片尺寸28*28,运用t-SNE将28*28维的原始像素特征空间压缩成2维,可以看到下图中的自然集群,这些集群对应了mnist数据集中的数据
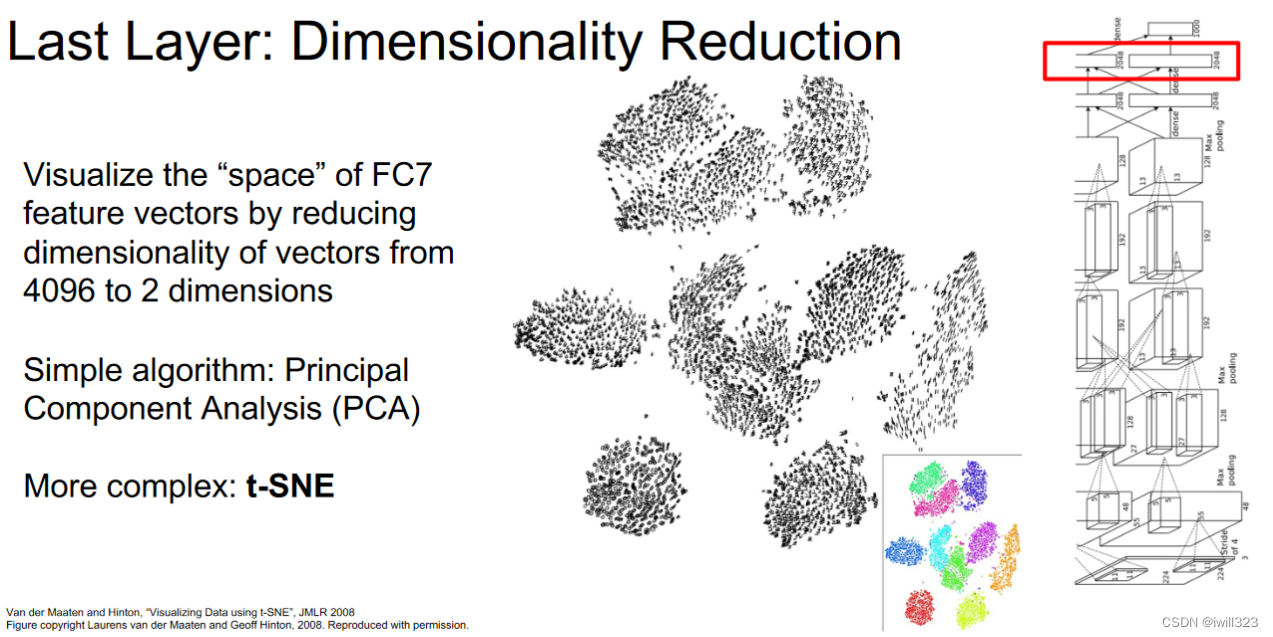
将大量图片送入CNN,收集他们的4096维特征向量,通过t-SNE降维把4096维特征空间压缩到2维特征空间
可视化激活值
AlexNet第五层的激活结果是13*13*256向量,其中一个GUP给出的结果是13*13*128向量,将这些向量可视化为128张图片(因为只有1个通道,所以图是灰色的)。测试图下面的那个图片是右边绿色框内图片的放大,可以看到该层激活量的一个slice(即feature map)正在寻找类似人脸的东西

Yosinski et al, “Understanding Neural Networks Through Deep Visualization”, ICML DL Workshop 2014
理解输入图片像素
识别重要的像素
maximally activating patches
图像中什么样的块可以最大限度地激活不同的神经元。取AlexNet中第五层卷积层的第17个通道,将大量图片送入AlexNet,记录下每个图片在该通道的值,找到该通道中被激活程度最大的neuron(即该feature map / channel中的一个标量),记录下输入图片中对应于该neuron的感受野(即图片中的一块图像)。由于卷积的性质,一个通道中的神经元(标量)共享权重,换句话说,一个通道由且只由一个卷积核产生,于是通过上面的操作,可以知道这个卷积核在寻找什么特征。
比如下图中的第一行对应于某个卷积核,说明网络中特定层的该卷积核寻找的是输入图像中蓝色的圆形物体。底部的几行对应于同一神经网络的较高层中最大化激活了neuron的图像块,因为他们来自于较高层,所以具有更大的感受野,可以感受到输入图像中更大的图像块,可以发现他们在寻找输入图像中较大的结构

遮挡实验
输入图像中的哪个部分导致CNN做出分类决定。在图像中遮挡某个区域,然后替换成图像值的平均像素值,送入CNN,得到预测概率

将遮挡住的区域多换几个位置(划过整个图片),绘制热力图heat map,热力图显示了预测概率与遮挡区域的关系。概率下降越大,说明遮挡的区域越重要。红色是低预测概率,黄色是高预测概率

Saliency Map
计算分类得分关于输入图片每个像素的梯度。图片中每一个像素的扰动,对该分类得分的影响有多大。能看到下图中小狗的轮廓。


在语义分割中可以用到Saliency Map,尤其是在没有标签的情况下。可以细分出图像汇总的对象,不过效果与有监督学习的情况相比,要差的多


通过Guided backprop生成图片
选取网络中间层的neuron(maximally activating patches选取的是中间层的一个channel),计算它关于输入图片像素的梯度,得到输入图像的哪个部分会影响该neuron的得分。计算的时候可以采用 Saliency Map。在方向传播的时候对算法进行微调,只传播正梯度,不传播负梯度。

这种方式更容易得到更清晰(cleaner)、更好(nicer)的图像,该图像说明哪些像素影响了那个特定的神经元。下图分别展示了maximally activating patches和Guided backprop 的结果。第一行右边显示了圆形区域对神经元的影响,和左边一样。


通过梯度上升可视化特征
什么样的输入会激活特定neuron:权重保持固定,合成图片,来最大化某个中间层neuron对某个分类的得分。需要正则项防止生成的图片像素过拟合,让生成的图片自然些

计算过程
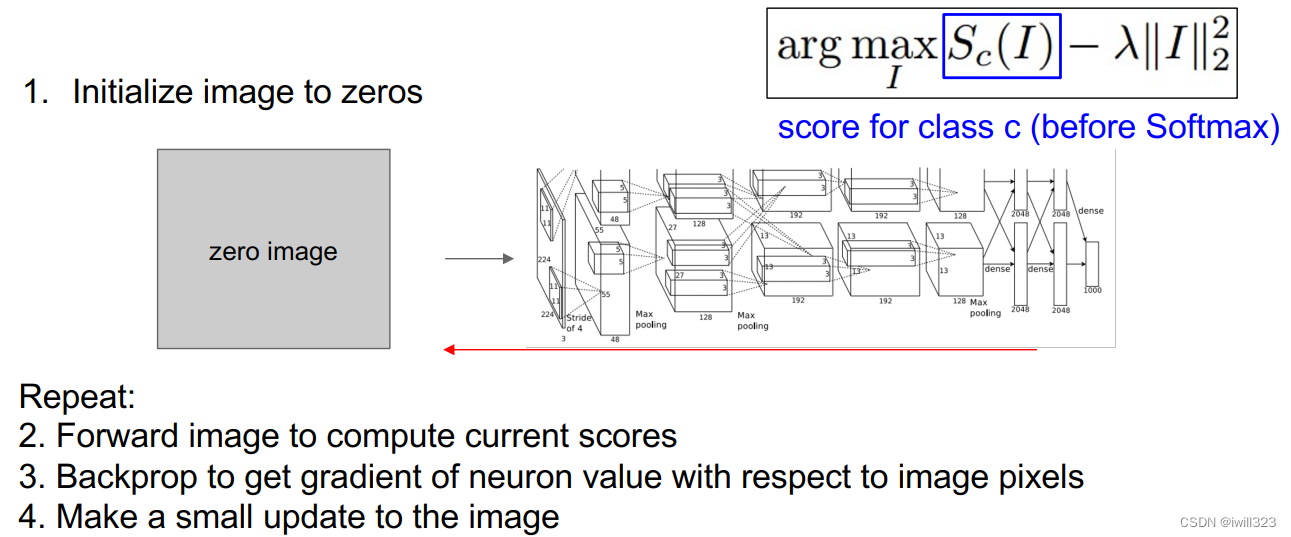
右边是生成的图像

使用Gaussian blur,得到的图片更平滑
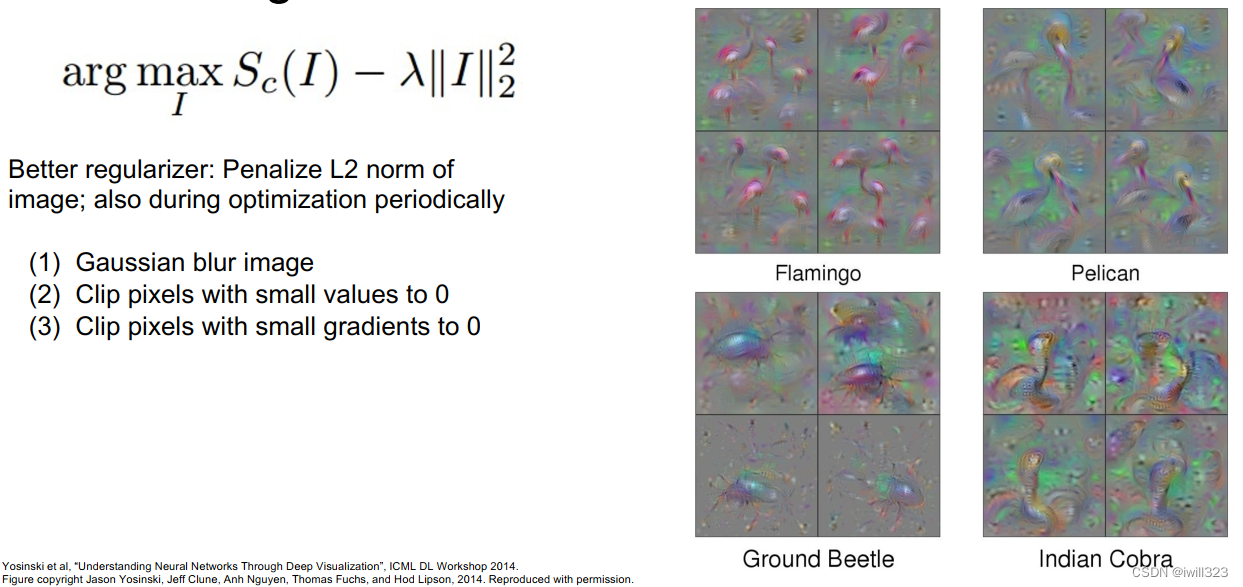
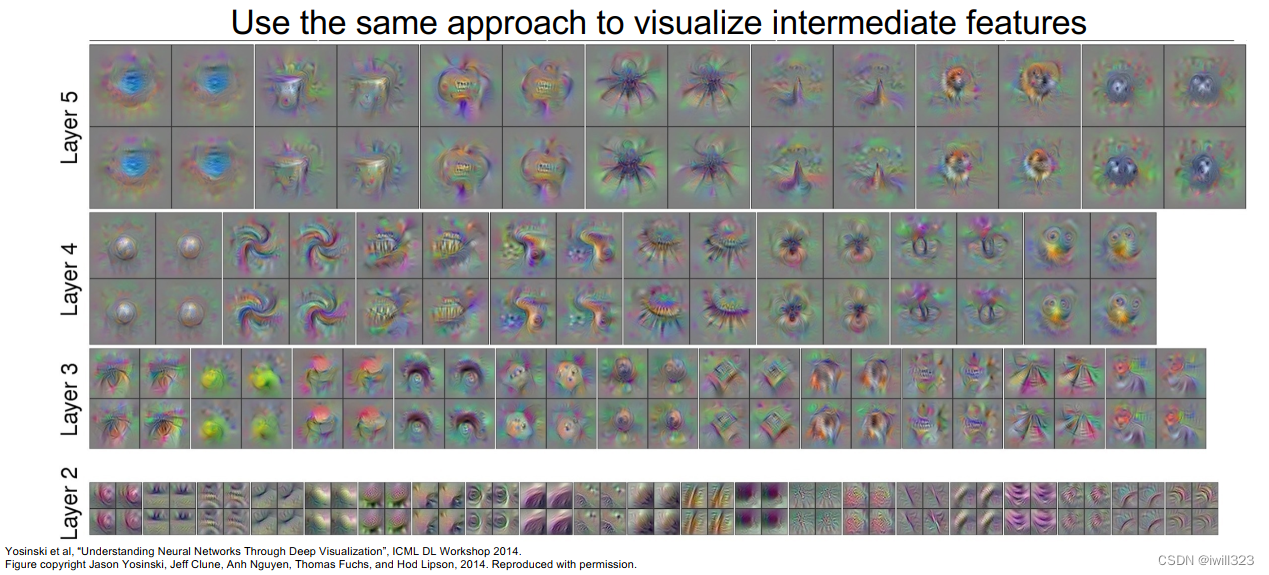
使用相同的方法使特定中间层中的neuron最大化激活,从而知道该neuron在寻找什么
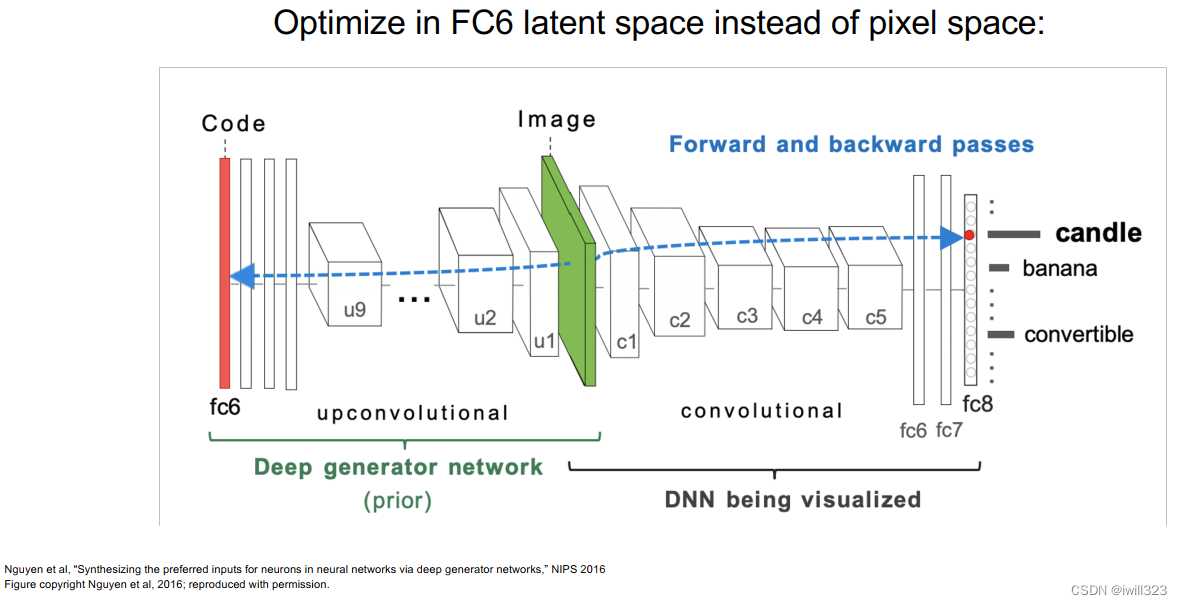
下图中八张图片都是杂货店,虽然第一排和第二排差别很大。在优化过程中考虑多模态multi modality,把这两种杂货店图像都模拟出来了

Adversarial perturbations
比如,选一个大象的图片,改变这张图片以让网络对考拉的得分最大化。涉及到对抗性机器学习,pytorch官网上有教程,讲的更为详细Adversarial Example Generation — PyTorch Tutorials 1.12.1+cu102 documentation
(1) Start from an arbitrary image
(2) Pick an arbitrary class
(3) Modify the image to maximize the class
(4) Repeat until network is fooled

版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。