
根据模型的数学原理进行简单的代码自我复现以及使用测试,仅作自我学习用。模型原理此处不作过多赘述。
如文中或代码有错误或是不足之处,还望能不吝指正。
本文侧重于使用numpy重新写出一个CNN模型,故而不像其他文章那样加入图片演示正向传播与反相传播的原理或是某个特定函数的求导过程以及结论。
CNN正向传播:
对于输入数据,对于每个通道与对应卷积进行相乘 之后相加得到结果中的1个通道。而在实际应用时,使用im2col(将各个通道以及图片打平成为一个矩阵),以此提升性能。然而由于此处我没有使用im2col,直接使用举证相乘,导致了计算相当缓慢。
反向传播:
对于反向传播而言,分为2种情况:
求dW时,正向传播时使用的是W * X = Z,在反向传播时,使用dW = dZ * X,需将记录的正向传播时的上一层输出作为输入。
而在求dX时,则需要将后面一层反向传播的delta进行补零,之后将卷积核旋转180度进行卷积。
具体实现参考了【一文读懂卷积神经网络(一)】可能是你看过的最全的CNN(步长为1,无填充)_深肚学习的博客-CSDN博客_步长为1的卷积
Batch Normalization:
在卷积过程中,势必会将原本的特征数量提升,而经过全连接层加权求和之后,会使得x变得很大,容易导致后续的softmax上溢出以及梯度爆炸,也限制了学习率不能太高。因此,需要在层与层之间使用Batch Normalization限制下一层的输入。
*CSDN的公式功能似乎损坏了,这里我就直接手打公式了
x* = gamma * (x-mu)/sigma + beta
其中,mu是x的均值,sigma为方差,sigma和beta是2个可以学习的参数。但是torch中没有对应learning rate的参数。
由于在numpy上实现的CNN过慢,我只能使用MNIST作为数据集进行测试,没有造成过多的数据量,故而训练时未加入Batch Normalization。
代码:
import numpy as np
from torchvision import datasets
from torchvision import transforms
from torch.utils.data import DataLoader
import math
from visdom import Visdom
import datetimemnist_train = datasets.MNIST('/public/torchvision_datasets',train=True,transform=transforms.Compose(
[transforms.Resize((28,28)),
transforms.ToTensor()]
),download = False)
mnist_test = datasets.MNIST('/public/torchvision_datasets',train=False,transform=transforms.Compose(
[transforms.Resize((28,28)),
transforms.ToTensor()]
),download = False)
train_loader = DataLoader(mnist_train,batch_size=512,shuffle=True)
test_loader = DataLoader(mnist_train,batch_size=512,shuffle=True)class Conv2d:
def __init__(self,input_size,output_size,kernel_size,stride,method = 'VALID'):
"""
输入shape = [Batch Size,宽,高,通道数]
初始化以下参数:
input_size 输入通道数
output_size 输出通道数
kernel_size 卷积核大小
stride 步长
method 填充方式,分为VALID核SAME2种
weights 卷积核的初始权重
bias 卷积核的初始偏置
conved_x = []
conved_res = []
"""
self.input_size = input_size
self.output_size = output_size
self.kernel_size = kernel_size
self.stride = stride
self.method = method
self.weights = np.random.standard_normal((input_size,kernel_size,kernel_size,output_size))
self.bias = np.random.standard_normal((input_size,kernel_size,kernel_size,output_size))
self.conved_x = []
self.conved_res = []
def forward(self,x):
"""
输入shape = [Batch Size,宽,高,通道数]
对于输入数据,对于每个通道与对应卷积进行相乘 之后相加得到结果中的1个通道
实际应用时,使用im2col(将各个通道以及图片打平成为一个矩阵),以此提升性能。
但是此处没有使用,故而计算十分缓慢
"""
self.origin_x_shape = x.shape #反向传播时delta的形状
batch_size = x.shape[0]
if self.method == 'SAME':
output_w = math.ceil(x.shape[1]/self.stride)
output_h = math.ceil(x.shape[2]/self.stride)
self.pad_w = max(0,(output_w-1)*self.stride+self.kernel_size-x.shape[1])
self.pad_h = max(0,(output_h-1)*self.stride+self.kernel_size-x.shape[2])
self.pad_right = math.ceil(self.pad_w/2)
self.pad_left = math.floor(self.pad_w/2)
self.pad_down = math.ceil(self.pad_h/2)
self.pad_up = math.floor(self.pad_h/2)
x = np.pad(x,((0,0),(self.pad_left,self.pad_right),(self.pad_up,self.pad_down),(0,0)),'constant')
self.x = x
self.conved_res = []
l=0
for bidx in range(batch_size):
conved_res_tmp = []
img = x[bidx]
#VALID: 输出为(input-ksize+1)/stride
#SAME:输出为input/stride
#for c in range(img.shape[-1]):
j=0
while j+self.kernel_size <= img.shape[0]:
#res_row = []
self.conved_x = []
k=0
while k+self.kernel_size <= img.shape[1]:
tmp = img[j:j+self.kernel_size,k:k+self.kernel_size,:]
self.conved_x.append(tmp)
k+=self.stride
#1行读完后,再将这一行的卷积核点乘结果计算出来
l = len(self.conved_x)
tmp_ch_row = []#np.zeros((output_size,l,kernel_size,kernel_size))
for out_ch in range(self.output_size):
for in_ch in range(self.input_size):
tmp_row = np.array([])#np.zeros((l,kernel_size,kernel_size))
for i in range(l):
try:
sub_img = self.conved_x[i]
except:
print(i,l,len(self.conved_x))
return
delta = np.sum(sub_img[:,:,in_ch]*self.weights[in_ch,:,:,out_ch]+self.bias[in_ch,:,:,out_ch])
#print(delta.shape)
if tmp_row.size == 0:
tmp_row = np.zeros((l))
tmp_row[i] += delta
tmp_ch_row.append(np.array(tmp_row))
conved_res_tmp.append(np.array(tmp_ch_row))
j+=self.stride
conved_res_tmp = np.array(conved_res_tmp)
conved_res_tmp = conved_res_tmp.swapaxes(0,1)
self.conved_res.append(conved_res_tmp)
self.conved_res = np.array(self.conved_res)
self.conved_res = self.conved_res.swapaxes(1,2)
self.conved_res = self.conved_res.swapaxes(2,3)
return self.conved_res
def backward(self,delta,lr=0.01):
"""
对delta进行卷积,目标形状为[Batch Size,宽,高,通道数]
反向输出的delta需要进行卷积核翻转
delta:和conved_res形状相同
策略:1、找出x中正向传播时的“单个卷积”所相乘的部分
2、为它们补零,以此可以适应卷积步长大于1以及有无填充的2种情况
参考:https://blog.csdn.net/weixin_43217928/article/details/88426172
"""
#求dW
conv_shape = [delta.shape[1],delta.shape[2]]
x=self.x
if self.stride>1:
x = self.change_for_bp(self.x,conv_shape)
delta_w = np.zeros_like(self.weights)
for bidx in range(delta.shape[0]):
for input_ch in range(self.input_size):
for out_ch in range(self.output_size):
sub_img = x[bidx,:,:,input_ch]
delta_w_row_idx = 0
i=0
while i+conv_shape[0]<=x.shape[1]:
j=0
delta_w_col_idx = 0
while j+conv_shape[1]<=x.shape[2]:
delta_w[input_ch,delta_w_row_idx,delta_w_col_idx,out_ch] += np.sum(sub_img[i:i+conv_shape[0],j:j+conv_shape[1]]*delta[bidx,:,:,out_ch])
j+=self.stride
delta_w_col_idx+=1
i+= self.stride
delta_w_row_idx+=1
self.weights -= lr*delta_w
#求db
dB = np.zeros_like(self.bias)
for bidx in range(delta.shape[0]):
for input_ch in range(self.input_size):
for out_ch in range(self.output_size):
i=0
while i+self.kernel_size<=delta.shape[1]:
j=0
while j+self.kernel_size<=delta.shape[2]:
dB[input_ch,:,:,out_ch] += delta[bidx,i:i+self.kernel_size,j:j+self.kernel_size,out_ch]
j+=self.stride
i+=self.stride
self.bias -= lr*dB
#求DA
delta = self.change_delta_for_bp(delta)
dA = np.zeros(self.origin_x_shape) #[Batch Size,宽,高,通道数(input)]
for bidx in range(delta.shape[0]):
for input_ch in range(self.output_size): #这2个channel反了,输入变输出,输出变输入
for out_ch in range(self.input_size):
sub_img = delta[bidx,:,:,input_ch]
#nrow = 0
for i in range(sub_img.shape[0]-self.kernel_size): #stride始终为1
for j in range(sub_img.shape[1]-self.kernel_size):
dA[bidx,i:i+sub_img.shape[0],j:j+sub_img.shape[1],out_ch]+=np.sum(sub_img[i:i+self.kernel_size,j:j+self.kernel_size]*np.rot90(self.weights[out_ch,:,:,input_ch],2))
return dA
def change_delta_for_bp(self,delta):
"""
反响传播计算delta时的补正
对于不同的正向补零规则以及步长,反向传播时也有不同的补零规则,
本人参考自https://blog.csdn.net/weixin_43217928/article/details/88426172的4篇文章
"""
dA_size = self.origin_x_shape
target_shape = [dA_size[0],dA_size[1]+self.kernel_size-1,dA_size[2]+self.kernel_size-1,delta.shape[-1]]
res = np.zeros(target_shape)
for bidx in range(delta.shape[0]):
for c in range(delta.shape[-1]):
#内部补零(stride>1),此处仅为个人理解,感觉会出现dZ过大的情况……
if self.stride>1:
#以下内容未测试,仅为本人理解
tmp = np.insert(delta[bidx,:,:,c],range(1,delta[bidx,:,:,c].shape[0],2),0,axis=1)
tmp = np.insert(tmp,range(1,tmp.shape[1],2),[0]*tmp.shape[0],axis=0)
else:
tmp = delta[bidx,:,:,c]
#外层补零
zero_width = int((target_shape[1]-tmp.shape[0])/2)
zero_height = int((target_shape[2]-tmp.shape[1])/2)
for _ in range(zero_width):
tmp = np.insert(tmp,0,0,axis=1)
for _ in range(zero_width):
tmp = np.insert(tmp,tmp.shape[1],0,axis=1)
for _ in range(zero_height):
tmp = np.insert(tmp,0,0*zero_height,axis=0)
for _ in range(zero_height):
tmp = np.insert(tmp,tmp.shape[0],0,axis=0)
res[bidx,:,:,c] = tmp
return res
def change_for_bp(self,x,conv_shape):
"""
反响传播计算更新用的参数的梯度时的补正
对于不同的正向补零规则以及步长,反向传播时也有不同的补零规则,
本人参考自https://blog.csdn.net/weixin_43217928/article/details/88426172的4篇文章
"""
res = np.zeros_like(x)
for bidx in range(x.shape[0]):
for output_ch in range(x.shape[-1]): #其实是input_ch,不过只是变量名称有误,不影响结果
sub_x = x[bidx,:,:,output_ch]
top_left_points = x[0:conv_shape[0],0:conv_shape[1]]
for i in range(conv_shape[0]):
for j in range(conv_shape[1]):
#p = top_left_points[i,j]
m=0
sub_res = np.zeros_like(top_left_points)
while i+m*self.stride<=conv_shape[0]:
n=0
while j+n*self.stride<=conv_shape[1]:
sub_res[m,n]=sub_x[i+m*self.stride,j+n*self.stride]
n+=self.stride
m+-self.stride
res[bidx,i:i+m*self.stride,j:j+n*self.stride,output_ch] = sub_res
return res
class MaxPooling:
def __init__(self,kernel_size,stride,method = 'VALID'):
"""
初始化以下参数:
kernel_size 池化核大小
stride 步长
method:补零规则
"""
self.kernel_size = kernel_size
self.stride = stride
self.method = method
def forward(self,x):
"""
输入shape = [Batch Size,宽,高,通道数]
同卷积层,不过把相乘变为了求最大值
"""
#self.origin_x_shape = x.shape #反向传播时delta的形状
batch_size = x.shape[0]
channels = x.shape[-1]
if self.method == 'SAME':
output_w = math.ceil(x.shape[1]/self.stride)
output_h = math.ceil(x.shape[2]/self.stride)
self.pad_w = max(0,(output_w-1)*self.stride+self.kernel_size-x.shape[1])
self.pad_h = max(0,(output_h-1)*self.stride+self.kernel_size-x.shape[2])
self.pad_right = math.ceil(self.pad_w/2)
self.pad_left = math.floor(self.pad_w/2)
self.pad_down = math.ceil(self.pad_h/2)
self.pad_up = math.floor(self.pad_h/2)
x = np.pad(x,((0,0),(self.pad_left,self.pad_right),(self.pad_up,self.pad_down),(0,0)),'constant')
self.x = x
self.maxed = np.zeros((batch_size,int((x.shape[1]-self.kernel_size)/self.stride+1),int((x.shape[1]-self.kernel_size)/self.stride+1),channels))
self.back_zeros = np.zeros_like(x)
for bidx in range(batch_size):
for c in range(channels):
maxed_i=0
for i in range(0,x.shape[1]-self.kernel_size+1,self.stride):
maxed_j=0
for j in range(0,x.shape[2]-self.kernel_size+1,self.stride):
pos = np.argmax(self.x[bidx,i:i+self.kernel_size,j:j+self.kernel_size,c])
row,col = divmod(pos,self.kernel_size)
row = i+row
col = j+col
self.maxed[bidx,maxed_i,maxed_j,c] = self.x[bidx,row,col,c]#np.max(self.x[bidx,i:i+self.kernel_size,j:j+self.kernel_size,c])
self.back_zeros[bidx,row,col,c]=1
maxed_j+=1
maxed_i+=1
return self.maxed
def backward(self,delta):
"""
同卷积层
"""
res = np.zeros(self.x.shape)
for bidx in range(delta.shape[0]):
for c in range(delta.shape[-1]):
delta_i=0
for i in range(0,self.back_zeros.shape[1]+1-self.kernel_size,self.stride):
delta_j=0
for j in range(0,self.back_zeros.shape[2]+1-self.kernel_size,self.stride):
res[bidx,i:i+self.kernel_size,j:j+self.kernel_size,c] += self.back_zeros[bidx,i:i+self.kernel_size,j:j+self.kernel_size,c]*delta[bidx,delta_i,delta_j,c]
delta_j+=1
delta_i+=1
if self.method == 'SAME':
res = np.delete(res,range(res.shape[1]-self.pad_right,res.shape[1]),axis=1)
res = np.delete(res,range(0,self.pad_left),axis=1)
res = np.delete(res,range(res.shape[2]-self.pad_down,res.shape[2]),axis=2)
res = np.delete(res,range(0,self.pad_up),axis=2)
return res
class Linear:
def __init__(self,input_size,output_size):
"""
初始化以下参数:
input_size 输入大小
output_size 输出大小
weight 权重矩阵
bias 偏置向量
"""
self.input_size = input_size
self.output_size = output_size
self.weight = np.random.normal(0,1,(input_size,output_size))
self.bias = np.random.normal(0,1,(output_size,))
def forward(self,x):
self.x = x
return np.dot(x,self.weight)+self.bias
def backward(self,delta,act=None,lr=0.01):
"""
其中act为激活函数,线性层的delta并非直接使用激活层反向传播的delta
而是将后一层的delta与之相乘得到的delta
"""
if act is not None:
d_act=act.backward(act.res)
delta *= d_act
w_grad = np.dot(self.x.T,delta)
b_grad = np.sum(delta,axis=0)
res = np.dot(delta,self.weight.T)
self.weight -= w_grad*lr
self.bias -= b_grad*lr
return res
class Relu:
def __init__(self):
pass
def forward(self,x):
self.res = np.maximum(x,0)
return self.res
def backward(self,delta):
delta[self.x<0]=0
return delta
class Sigmoid:
def __init__(self):
pass
def forward(self,x):
self.res = 1.0/(1.0+np.exp(-x))
return self.res
def backward(self,delta):
return delta*(1-delta)
class Softmax:
"""
使用softmax函数将数字集中中到某一个类别上
参考:https://blog.csdn.net/DuLNode/article/details/123878060
"""
def __init__(self):
pass
def forward(self,x):
x = x.T
m = np.max(x,axis=0)
t = np.exp((x-m.T)) #防止溢出
s = np.sum(t,axis=0)
self.res = t/s
self.res = self.res.T
return self.res
def backward(self,delta):
d = []
for i in range(delta.shape[0]):
yiyj = np.outer(self.res[i],self.res[i])
soft_grad = np.dot(np.diag(self.res[i])-yiyj,delta[i].T)
d.append(soft_grad)
return np.array(d)
class CrossEntropy:
"""
交叉熵损失函数
"""
def __init__(self,num_classes) -> None:
self.num_classes = num_classes
def forward(self,pred,label):
label = np.eye(self.num_classes)[label]
loss = -np.sum(label*np.log(pred))
delta = -label/pred
# loss = ((pred-label)**2)/2
# delta = pred-label
return loss,delta
class MSE:
"""
均方误差损失函数
"""
def __init__(self,num_classes):
self.num_classes = num_classes
def forward(self,pred,label):
label = np.eye(self.num_classes)[label]
loss = ((pred-label)**2)/2
delta = pred-label
return np.sum(loss),delta
class Flatten:
"""
将多维度打平为二维
"""
def __init__(self) -> None:
pass
def forward(self,x):
self.shape = x.shape
res = []
for i in range(x.shape[0]):
res.append(x[i].flatten())
return np.array(res)
def backward(self,delta):
return delta.reshape(self.shape)
class BatchNormalize:
"""
【未使用】将输入的数字“标准化”,避免后续计算溢出
其中beta和gamma是用来学习的参数,但是torch中没有对应learning rate的参数……?
参考https://zhuanlan.zhihu.com/p/45614576
1d
\gamma` and `\beta` are learnable parameter vectors
| of size `C` (where `C` is the input size). By default, the elements of :math:`\gamma` are set
| to 1 and the elements of :math:`\beta` are set to 0.
"""
def __init__(self):
self.beta = 0
self.gamma = 1
#self.lr = lr
def forward(self,x):
self.x = x
self.mu = np.mean(x,axis=0)
self.sigma = np.var(x,axis=0)
self.x_hat = (x-self.mu)/np.sqrt(self.sigma+1e-5)
self.res = self.gamma*self.x_hat+self.beta
return self.res
def backward(self,delta,lr=0.001):
dgamma = np.sum(self.x_hat*delta,axis=0)
dbeta = np.sum(delta,axis=0)
dxhat = delta*self.gamma
dsigma = np.sum(dxhat*(self.x-self.mu)*(-np.power(self.sigma+1e-5,-1.5))/2)
sigma_d_mu = -(np.sum(2*(self.x-self.mu)))/delta.shape[0]
dmu = np.sum(dxhat*(-1/np.sqrt(self.sigma+1e-5)))+dsigma*sigma_d_mu
res = 1/np.sqrt(self.sigma+1e-5)*dxhat+dmu/delta.shape[0]+dsigma*2*(self.x-self.mu)/delta.shape[0]
self.gamma -= lr*dgamma
self.beta -= lr*dbeta
return resclass Net:
def __init__(self):
self.conv1 = Conv2d(1,3,kernel_size=3,stride=1)
self.MaxPool1 = MaxPooling(kernel_size=2,stride=1)
self.flt = Flatten()
self.Linear1 = Linear(1875,30)
#self.bn = BatchNormalize()
self.sigmoid1 = Sigmoid()
self.Linear2 = Linear(30,30)
self.sigmoid2 = Sigmoid()
self.Linear3 = Linear(30,10)
self.sigmoid3 = Sigmoid()
self.softmax = Softmax()
self.loss_function = CrossEntropy(10)
def forward(self,x,y):
x = x.swapaxes(1,2)
x = x.swapaxes(2,3)
x = self.conv1.forward(x)
x = self.MaxPool1.forward(x)
x = self.flt.forward(x)
x = self.Linear1.forward(x)
#x = self.bn.forward(x)
x = self.sigmoid1.forward(x)
x = self.Linear2.forward(x)
x = self.sigmoid2.forward(x)
x = self.Linear3.forward(x)
x = self.sigmoid3.forward(x)
x = self.softmax.forward(x)
if y is not None:
self.loss,self.delta = self.loss_function.forward(x,y)
return x
def backward(self):
delta= self.delta
delta = self.softmax.backward(delta)
delta = self.Linear3.backward(delta,self.sigmoid3)
#print(delta)
delta = self.Linear2.backward(delta,self.sigmoid2)
#print(delta)
delta = self.Linear1.backward(delta,self.sigmoid1)
delta = self.flt.backward(delta)
delta = self.MaxPool1.backward(delta)
delta = self.conv1.backward(delta)
return deltan = Net()
viz = Visdom()
global_step=0
flag = True
losses = []
for epoch in range(1000):
if flag:
for bidx,(x,y) in enumerate(train_loader):
x = np.array(x)
y = np.array(y)
res = n.forward(x,y)
#print(res)
if global_step % 100 == 0:
viz.line([n.loss],[global_step],win="train_loss_torch",update="append",opts = dict(title="numpy训练的损失函数"))
losses.append(n.loss)
viz.line([n.loss],[global_step],win="train_loss_torch_one_step",update="append",opts = dict(title="numpy训练的损失函数-one-step"))
n.backward()
global_step+=1
if epoch % 10 == 0:
ttl = 0
corr = 0
for bidx,(x,y) in enumerate(test_loader):
x = np.array(x)
y = np.array(y)
res = n.forward(x,None)
corr += sum(np.equal(np.argmax(res,axis=1),y))
ttl += len(y)
print("epoch为",epoch,"测试集上准确率为",corr/ttl)结果:
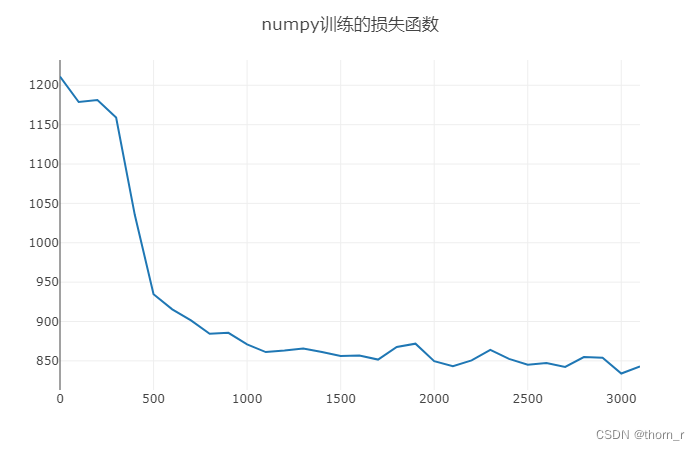

由于模型深度较小等原因 ,预测的结果还没有MLP来的要好(约90%);或许经过更长时间的训练能够达到更好的效果,然而由于卷积层没有使用im2col,代码没有优化以及使用python本身速度有限,使得训练速度变得十分缓慢,经过3天2夜才跑到25个epoch。但是作为小练手,能够成功运行起来并训练出模型,暂时也算是聊胜于无了。
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。