
摘要:
在MLP分类器的分析过程中,可以分为数据预处理和网络训练以及可视化部分,其中数据预处理部分会针对数据是否进行标准化处理进行单独分类,主要是用于分析数据标准化对于MLP网络训练的重要性。
一、数据准备与探索:
本文使用一个垃圾邮件数据集介绍如何使用Pytorch建立MLP分类模型,该数据集可以从我上传的CSDN免费资料中下载,网址为:spambase.csv垃圾邮件数据集-深度学习文档类资源-CSDN下载实验数据集:垃圾邮件数据集(http://archive.ics.uci.edu/ml/datase更多下载资源、学习资料请访问CSDN下载频道.https://download.csdn.net/download/weixin_52067875/86406181
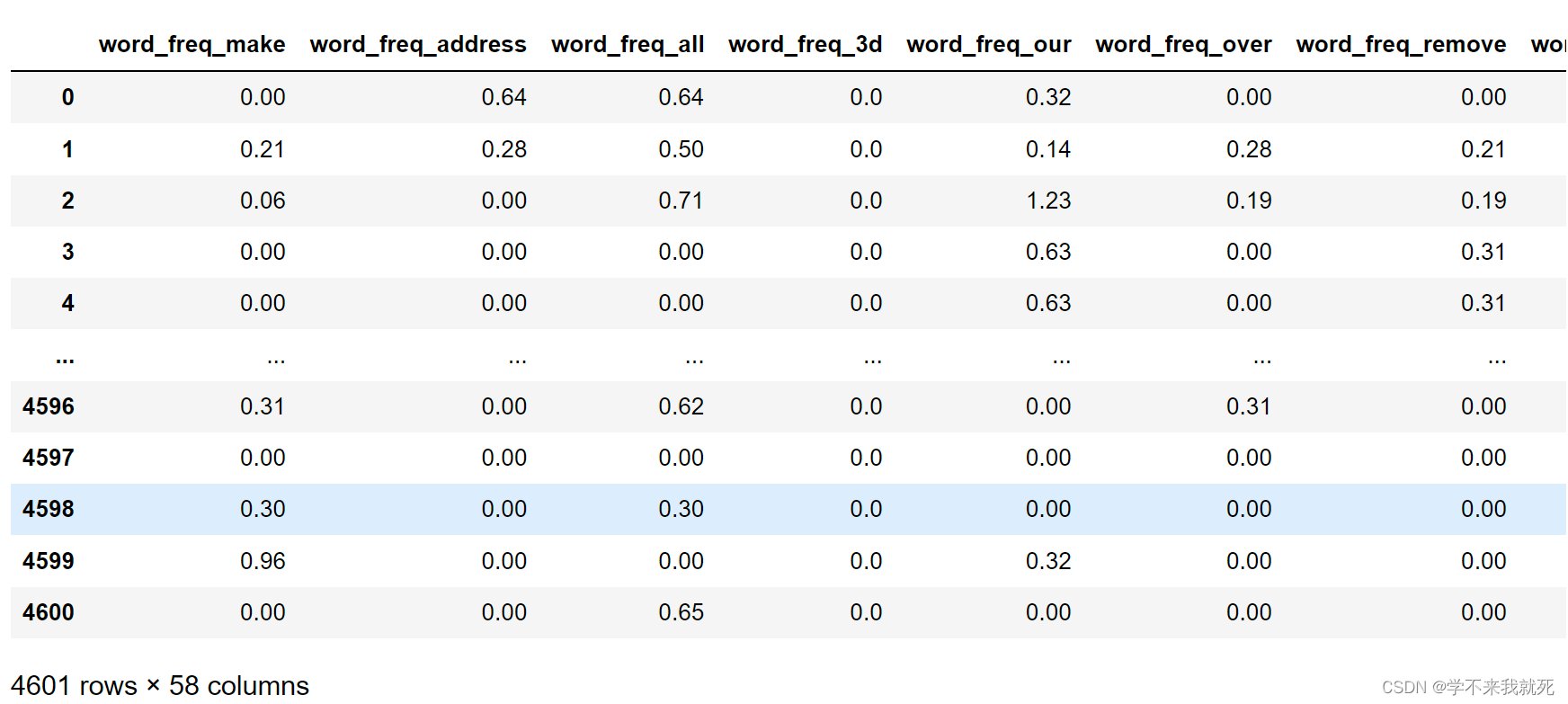
在该数据集中,包含57个邮件内容的统计特征,其中有48个特征是关键词出现的频率*100的取值,6个特征为关键字符出现的频率*100的取值,1个变量表示大写字母不间断的平均长度,1个变量表示邮件中大写字母的数量,数据集中最后一个变量是待预测目标变量(0、1),表示电子邮件被认为是垃圾邮件(1)或不是(0)。
首先,我们将垃圾邮件数据集下载保存为spambase.csv,接着导入需要使用的模块与库:
import numpy as np
import pandas as pd
from sklearn.preprocessing import StandardScaler,MinMaxScaler
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score,confusion_matrix,classification_report
from sklearn.manifold import TSNE
import torch
import torch.nn as nn
from torch.optim import SGD,Adam
import torch.utils.data as Data
import matplotlib.pyplot as plt
import seaborn as sns
import hiddenlayer as hl
from torchviz import make_dot接下来我们使用pandas包将数据集读出,代码如下:
spam = pd.read_csv("data/chap5/spambase.csv")
spam结果为:
我们统计一下两种类型邮件的样本数,使用pd.value_counts()函数进行计算,代码为:
#计算垃圾邮件和非垃圾邮件的数量
pd.value_counts(spam['is_spam'])结果为:
0 2788
1 1813
Name: is_spam, dtype: int64我们可以发现数据集中有1813个垃圾邮件样本,2788个非垃圾邮件样本。我们将数据集切分为训练集和测试集,其中使用75%的数据作为训练集,25%的数据作为测试集,对于数据集的切分我们可以使用train_test_split()函数,代码如下:
#将数据集切分为训练集和测试集
X = spam.iloc[:,0:57].values
y = spam['is_spam'].values
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.25,random_state=123)在切分数据后,我们对数据进行标准化处理,此处我们进行最大值——最小值最小化(MinMaxScaler()函数),由此我们可以将数据集的每个特征取值范围转化到0~1之间,代码如下:
#切分数据后 对数据进行标准化处理(最大值——最小值标准化,将每个特征取值范围转化到0~1)
#对前57列特征进行标准化处理
scales = MinMaxScaler(feature_range=(0,1))
X_train_s = scales.fit_transform(X_train)
X_test_s = scales.fit_transform(X_test)在得到标准化数据后,我们将训练数据集的每个特征变量使用箱线图进行显示,对比不同类别的邮件在每个特征变量上的数据分布情况:
#得到标准化数据后使用箱线图将训练集的每个特征变量进行显示
colname = spam.columns.values[:-1]#:-1表示除了最后一个取全部
print(len(colname))
plt.figure(figsize=(20,14))
for i in range(len(colname)):
plt.subplot(7,9,i+1)
sns.boxplot(x=y_train,y=X_train_s[:,i])#[:,i]表示取第i列的所有行
plt.title(colname[i])
plt.subplots_adjust(hspace=0.5)
plt.show()结果为:
57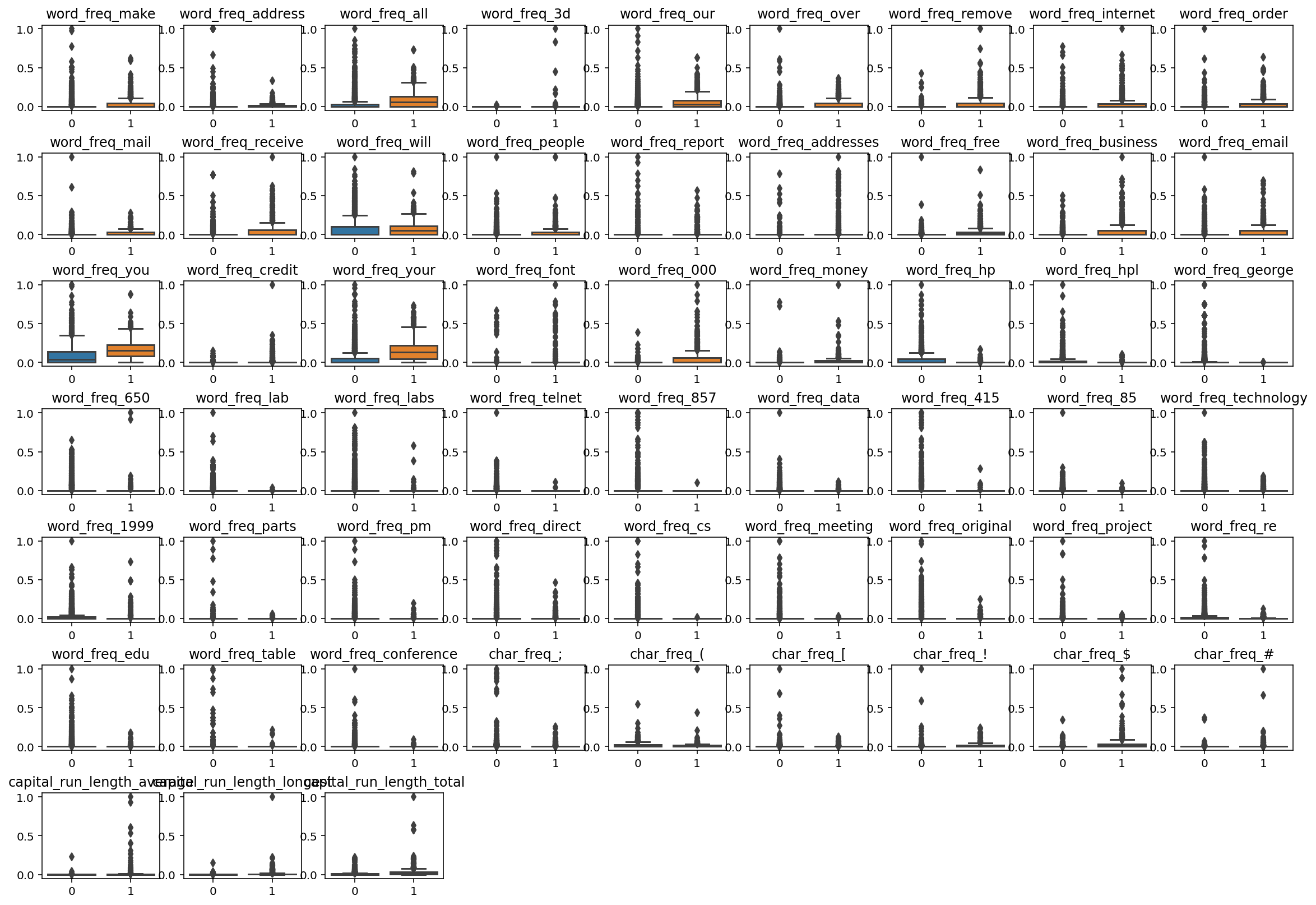
从箱线图我们可以看出,有些特征在两种类型的邮件分布上有较大差异,如word_freq_all、word_freq_our等。
二、搭建网络并可视化:
经过了数据准备、探索和可视化分析后,我们需要搭建需要的全连接神经网络分类器。代码如下:
#全连接网络
class MLPclassifica(nn.Module):
def __init__(self):
super(MLPclassifica,self).__init__()
self.hidden1 = nn.Sequential(
nn.Linear(in_features=57,
out_features=30,#30
bias=True),
nn.ReLU())
self.hidden2 = nn.Sequential(
nn.Linear(in_features=30,#30
out_features=10,
bias=True),
nn.ReLU())
self.classifica = nn.Sequential(
nn.Linear(in_features=10,
out_features=2,
bias=True),
nn.Sigmoid())
#定义网络的前向传播途径
def forward(self,x):
fc1 = self.hidden1(x)
fc2 = self.hidden2(fc1)
output = self.classifica(fc2)
#输出为两个隐藏层和输出层
return fc1,fc2,output在上面的程序中定义了一个MLPclassifica函数类,网络结构中含有hidden1和hidden2两个隐藏层,分别包含30、10个神经元以及一个分类层classifica(使用Sigmoid激活函数)。由于数据有57个特征,所以第一个隐藏层的输入特征为57,又因为该数据为二分类问题,所以分类层有2个神经元。在定义完网络结构后,需要定义网络的正向传播过程,分别输出网络的两个隐藏层fc1、fc2、以及分类层的输出output。
针对定义好的MLPclassifica函数类,使用mlpc=MLPclassifica()得到全连接网络mlpc,并利用torchviz库中的make_dot函数,对网络结构进行可视化处理,代码如下:
mlpc = MLPclassifica()
print(mlpc)
#利用torchviz库将网络结构可视化
x = torch.randn(1,57).requires_grad_(True)
y = mlpc(x)
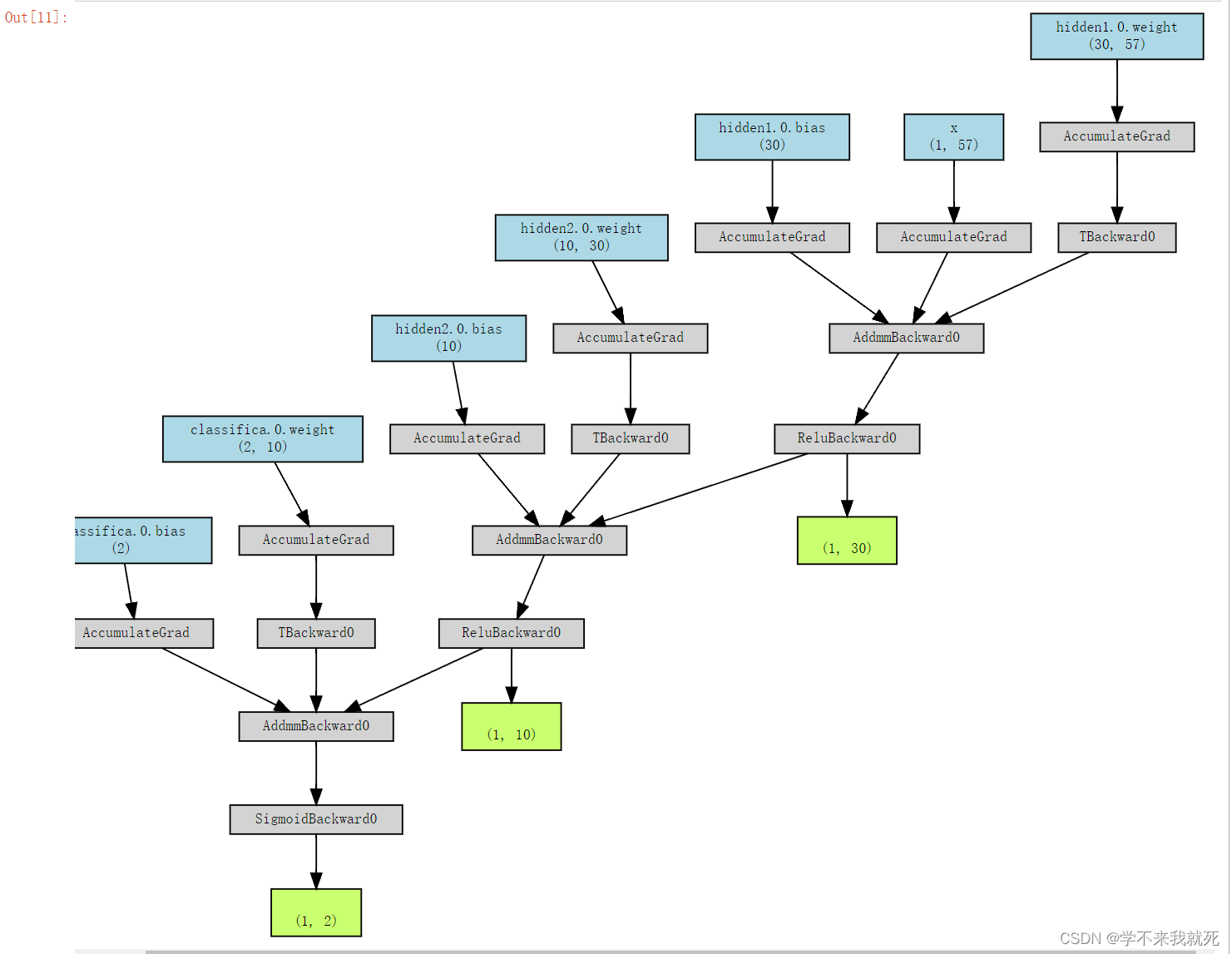
Mymlpvis = make_dot(y,params=dict(list(mlpc.named_parameters())+[('x',x)]))Mymlpvis结果为:
MLPclassifica(
(hidden1): Sequential(
(0): Linear(in_features=57, out_features=30, bias=True)
(1): ReLU()
)
(hidden2): Sequential(
(0): Linear(in_features=30, out_features=10, bias=True)
(1): ReLU()
)
(classifica): Sequential(
(0): Linear(in_features=10, out_features=2, bias=True)
(1): Sigmoid()
)
)
得到的网络结构传播过程的可视化结构如图所示:
三、使用未预处理的数据训练模型:
在网络搭建完毕后,我们首先使用未经过预处理的训练数据训练模型,然后利用未标准化的测试数据验证模型的泛化能力,分析网络在未标准化的数据集中能否很好的拟合数据
首先,我们将未标准化的数据转化为张量,并且将张量定义为数据加载器。值得注意的是,为了使模型能够正常的开始训练,我们需要将训练数据集X转化为32位浮点型张量,将数据集Y转化为64位整型张量。代码如下;
#将数据转化成张量
X_train_nots = torch.from_numpy(X_train.astype(np.float32))
y_train_t = torch.from_numpy(y_train.astype(np.int64))
X_test_nots = torch.from_numpy(X_test.astype(np.float32))
y_test_t = torch.from_numpy(y_test.astype(np.int64))
#将训练集转化为张量后,视同tensordataset将X和Y整理到一起
train_data_nots = Data.TensorDataset(X_train_nots,y_train_t)
#定义数据加载器
train_nots_loader = Data.DataLoader(
dataset=train_data_nots,
batch_size=64,
shuffle=True,
num_workers=2)数据准备完毕后,我们需要使用训练集对mlpc进行训练和测试,在优化模型时,我们使用Adam优化函数,损失函数使用交叉熵损失函数。为了观察网络在训练过程中损失的变化情况以及在测试集上预测精度的变化,我们用HiddenLayer库将相应数据的变化进行可视化。代码如下:
#使用训练集对全连接神经网络进行训练和测试
#定义优化器
optimizer = torch.optim.Adam(mlpc.parameters(),lr=0.01)
loss_func = nn.CrossEntropyLoss()#交叉熵损失函数
#记录训练过程的指标
history1 = hl.History()
#使用canvas进行可视化
canvas1 = hl.Canvas()
print_step = 25#25次迭代后输出损失
#对模型进行迭代处理 所有数据训练30轮
for epoch in range(30):
#对训练数据的加载器进行迭代计算
for step,(b_x,b_y) in enumerate(train_nots_loader):
#计算每个batch的损失
_,_,output = mlpc(b_x)#MLP在训练batch的输出
train_loss = loss_func(output,b_y)#二分类交叉熵损失
optimizer.zero_grad()
train_loss.backward()
optimizer.step()#使用梯度优化
#计算迭代次数
niter = epoch*len(train_nots_loader)+step+1
#计算没经过print_step次迭代后的输出(25)
if niter % print_step == 0:
_,_,output = mlpc(X_test_nots)
_,pre_lab = torch.max(output,1)
test_acc = accuracy_score(y_test_t,pre_lab)
#为history添加epoch,损失和精度
history1.log(niter,train_loss = train_loss,test_acc = test_acc)
#使用两个图像可视化损失函数和精度
with canvas1:
canvas1.draw_plot(history1["train_loss"])
canvas1.draw_plot(history1["test_acc"])
print("training:epoch:{},loss is:{}".format(epoch,train_loss))上面的程序我们对训练数据集进行了30个epoch的训练,在网络训练过程中,每间隔25次迭代我们就·对测试集进行一次预测,并使用canvas1、draw_plot()函数将损失函数大小、预测精度实时地可视化出来,得到的模型训练过程如下:

从图片中可以看出,损失函数与精度始终没有收敛,说明使用未经预处理的数据集训练的模型训练效果较差,收敛程度很低。
因此,我们需要使用经过预处理的数据集训练模型。
四、使用预处理后的数据训练模型:
在第三节中,我们使用未经过预处理的数据集训练模型,但是模型并没有收敛,其原因就出现在模型使用的数据没有经过标准化预处理。下面我们使用标准化数据集重新对上面的MLP神经网络进行训练,从而观察使用标准化预处理的数据集会对模型的拟合能力产生什么影响。
首先,我们对标准化后的数据进行预处理,并转化为张量、定义数据加载器,代码如下:
#将数据转化成张量
X_train_t = torch.from_numpy(X_train_s.astype(np.float32))
y_train_t = torch.from_numpy(y_train.astype(np.int64))
X_test_t = torch.from_numpy(X_test_s.astype(np.float32))
y_test_t = torch.from_numpy(y_test.astype(np.int64))
#将训练集转化为张量后,视同tensordataset将X和Y整理到一起
train_data = Data.TensorDataset(X_train_t,y_train_t)
#定义数据加载器
train_loader = Data.DataLoader(
dataset=train_data,
batch_size=64,
shuffle=True,
num_workers=2)在训练数据和测试数据准备好后,我们对全连接神经网络分类器进行训练,代码与第三节相似:
#使用训练集对全连接神经网络进行训练和测试
#定义优化器
optimizer = torch.optim.Adam(mlpc.parameters(),lr=0.01)
loss_func = nn.CrossEntropyLoss()#交叉熵损失函数
#记录训练过程的指标
history1 = hl.History()
#使用canvas进行可视化
canvas1 = hl.Canvas()
print_step = 25#25次迭代后输出损失
#对模型进行迭代处理 所有数据训练30轮
for epoch in range(30):
#对训练数据的加载器进行迭代计算
for step,(b_x,b_y) in enumerate(train_loader):
#计算每个batch的损失
_,_,output = mlpc(b_x)#MLP在训练batch的输出
train_loss = loss_func(output,b_y)#二分类交叉熵损失
optimizer.zero_grad()
train_loss.backward()
optimizer.step()#使用梯度优化
#计算迭代次数
niter = epoch*len(train_loader)+step+1
#计算没经过print_step次迭代后的输出(25)
if niter % print_step == 0:
_,_,output = mlpc(X_test_t)
_,pre_lab = torch.max(output,1)
test_acc = accuracy_score(y_test_t,pre_lab)
#为history添加epoch,损失和精度
history1.log(niter,train_loss = train_loss,test_acc = test_acc)
#使用两个图像可视化损失函数和精度
with canvas1:
canvas1.draw_plot(history1["train_loss"])
canvas1.draw_plot(history1["test_acc"])
print("training:epoch:{},loss is:{}".format(epoch,train_loss))在上面的程序中,我们使用了标准化处理后的数据集对网络进行训练,并且在网络训练过程中,每间隔25次迭代我们就·对测试集进行一次预测,并使用canvas1、draw_plot()函数将损失函数大小、预测精度实时地可视化出来,得到的模型训练过程如下:
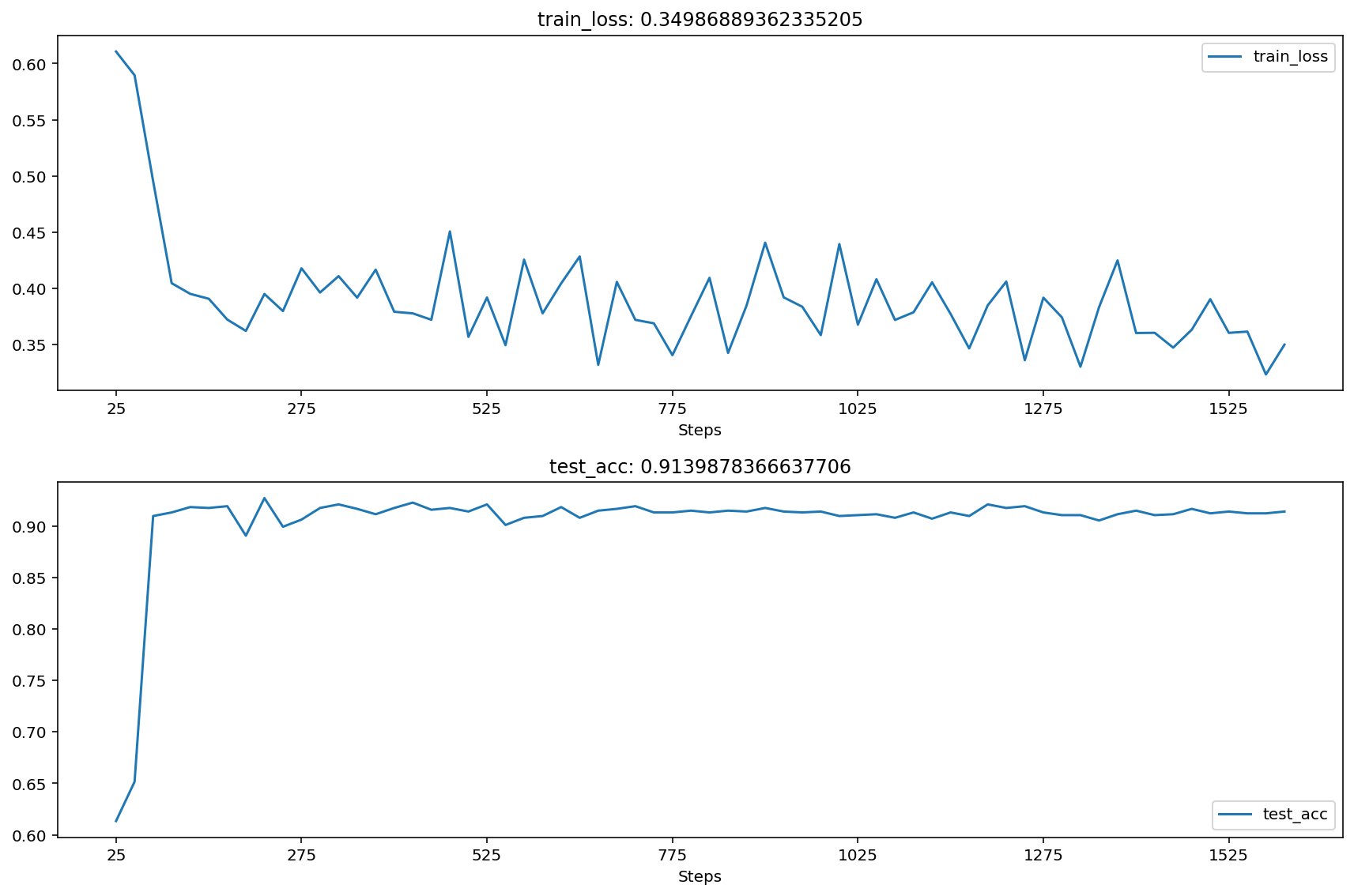
从图片可以看出,损失函数最终收敛到一个比较平稳的数值区间,并且在测试集上的精度也逐渐收敛,由此我们可以证实:数据标准化预处理对MLP网络非常重要。
在得到收敛的模型后,我们可以在测试集上计算模型的垃圾邮件最终识别精度,代码如下;
#计算模型在测试集的最终精度
_,_,output = mlpc(X_test_t)
_,pre_lab = torch.max(output,1)
test_acc = accuracy_score(y_test_t,pre_lab)
print("准确率为:",test_acc)结果为:
准确率为: 0.9139878366637706
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。