

嘉宾 | 徐蓓
出品 | CSDN云原生
2022年8月4日,中国信通院、腾讯云、FinOps产业标准工作组联合发起的《原动力x云原生正发声 降本增效大讲堂》系列直播活动第5讲上,腾讯云容器技术专家徐蓓分享了如何通过云原生管理Kubernetes GPU资源。本文整理自徐蓓的分享。

当前Kubernetes GPU使用方式
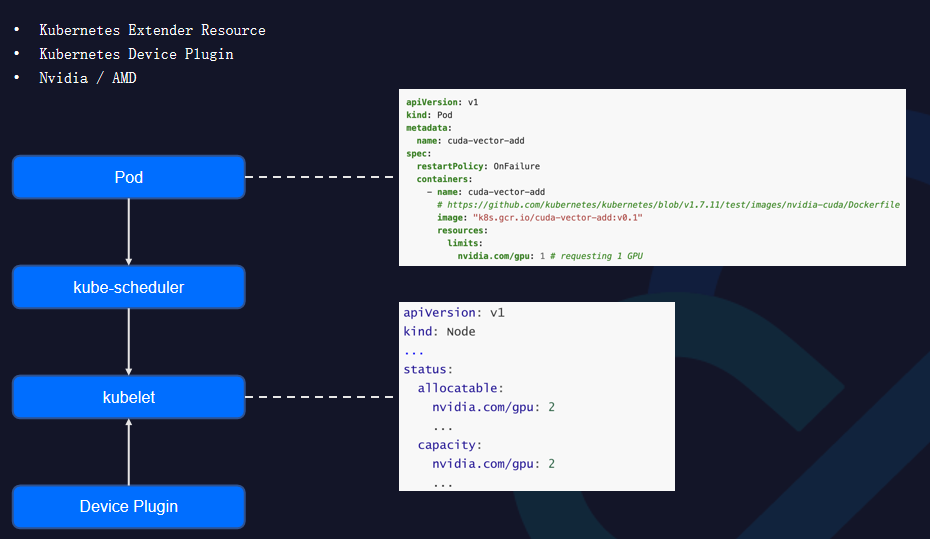
K8s社区主要通过Extender Resource和Device Plugin方式给为用户提供GPU物理资源支持。
每个GPU厂商都会实现自己的Device Plugin Agent,Agent在底层节点层会将物理卡扫描上报到集群。用户用拓展资源方式在Pod创建时指定需要物理卡的数量,Device Plugin在每个Kubelet节点上做启动,并且调用各个GPU厂商的设备工具,将设备卡资源扫描上报。这是K8s提供的通用方式,但通用方案在支持专用芯片方案上略显不足:
-
在GPU层面,用户在Pod里只能支持申请整卡的方式,不支持共享卡,这会导致单个物理卡资源层面浪费;
-
在集群层面,缺少GPU分配信息,用户很难看到GPU和容器的关联关系;
-
每个GPU的Provider都会实现各自的Device Plugin,在一个集群里面Device Plugin方案增多,从而会变得很复杂。
基于这些问题,我们提出了改进方案:
-
支持整卡分配与GPU共享,以降低客户层面复杂度;
-
用户在集群里面能以直观方式查看物理卡分配信息,增加GPU在K8s集群里的可见性;
-
支持统一Device Plugin,降低管理员复杂度。

通过云原生方式管理GPU资源

在此背景下,我们根据业务需求支持用户通过云原生方式管理GPU资源。此方案分为四个模块:
-
在前端资源层面有两个标准化资源定义GPU Core和GPU Memory;
-
在GPU CRD里能看见物理卡与容器所用资源的关系,用户可获取到集群GPU资源分配情况,增加了物理卡在集群的可见性;
-
自研GPU Extender Scheduler扩展调度器可以针对GPU资源做精细化调度,提升集群层面分配效率,感知单个物理卡资源。
-
Device Plugin Agent提供了一个通用化框架,支持任意基于Device Plugin的发现机制;在框架上实现了主流的GPU Provider支持,降低了用户管理成本。
统一GPU资源
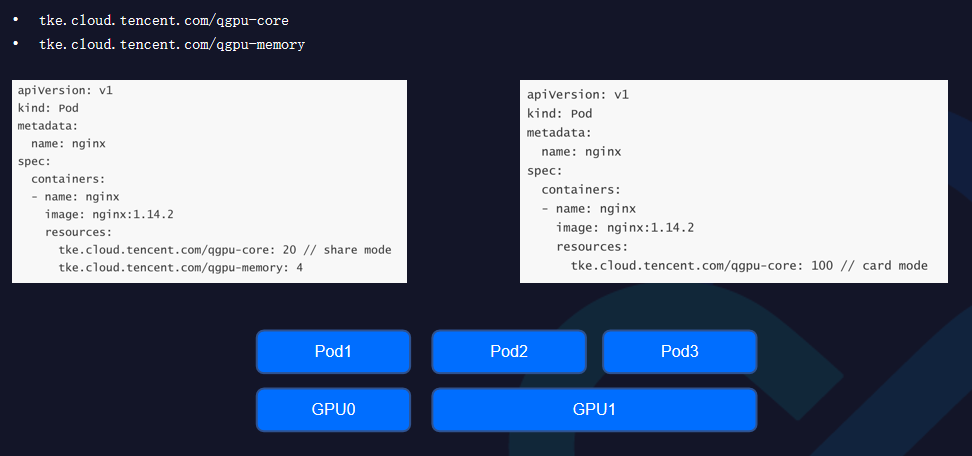
在资源层面,定义两个标准的GPU资源:
-
qgpu-core:将单卡算力分成一百份,每一份代表1%,用户可以做共享卡申请;
-
qgpu-memory:目前是GB为单位,用户可以在单卡内部申请部分显存。
使用层面来说,和原有整卡使用没有区别,只是资源由我们提供。方案也可以实现整卡的分配,如果算力小于一百就是共享卡模式,如果算力值是大于一百的整数倍,用户就可以做整卡的申请。
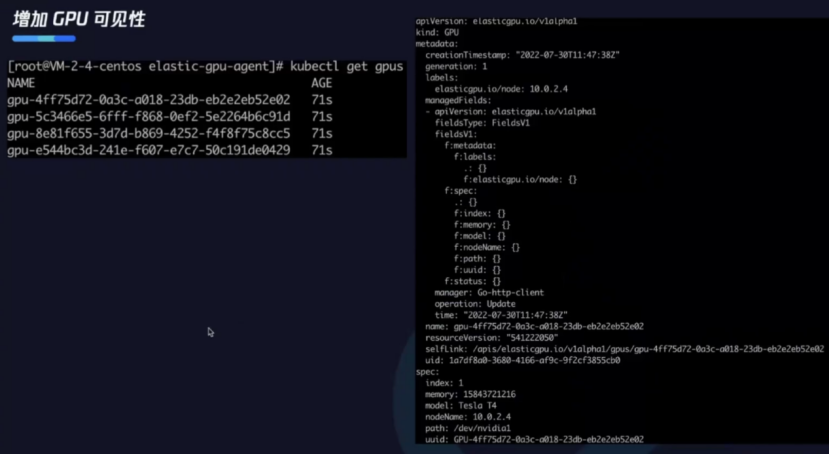
在K8s里有CRD实现,一个CRD对应单个节点层面的一个物理卡。
下图右侧是CRD里存在的信息,包括GPU物理卡本身所具有的资源。管理员也可根据我们提供的CRD查看集群层面GPU卡的分配情况,使集群层面GPU资源管理难易程度大大降低。
统一GPU框架

在底层的Unified GPU Device plugin Framework里,为用户层面提供了统一的入口,并且和主流Device Plugin做了融合,支持整卡分配以及和自己的GPU容器化方案做深度集成。最终可以通过一个Device Plugin在集群里面实现任意GPU技术,简化用户GPU使用及申请复杂度,GPU使用效率得到很大提升。

通过qGPU共享提升GPU使用率
通过GPU共享在底层提升资源利用率,我们用到了qGPU技术。qGPU技术本质是GPU容器化技术,它能够完成三大功能:
-
多容器共享GPU;
-
算力/显存强隔离;
-
在离线混合部署。
它有以下特点:
-
灵活性:精细配置GPU算力占比和显存大小;
-
强隔离:支持显存和算力的严格隔离;
-
在离线:支持业界唯一在离线混部能力,GPU利用率压榨到极致;
-
覆盖度:支持覆盖主流卡T4、V100及Ampere架构A10、A100等;
-
云原生:支持标准Kubernetes和NVIDIA Docker;
-
兼容性:业务不重编、CUDA库不替换、业务无感;
-
高性能:GPU设备底层虚拟化,高效收敛,吞吐接近0损耗。
qGPU技术框架
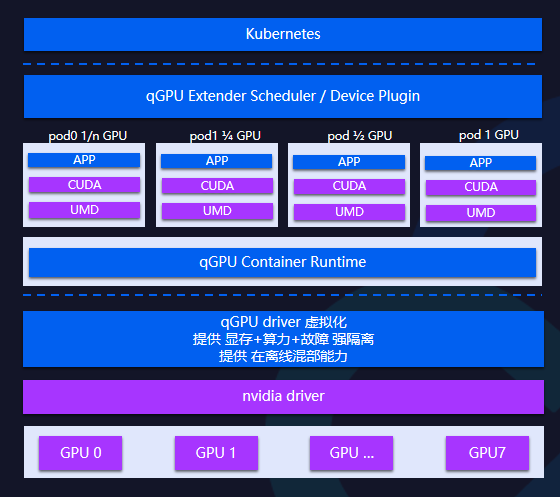
在K8s层面围绕qGPU做了K8s扩展调度器以及Device Plugin,在底层的qGPU Container Runtime里做qGPU设备创建、申请以及管控。在英伟达方案里,基于英伟达UMD和KMD之间做接口层面的拦截,由于是在内核层面做隔离,因此层级越低颗粒度越高。
在一个K8s集群里,可以使用不同GPU的资源。在调度层面中可以支持单个GPU物理卡级别,节点和GPU可以实现双层binpack/spread调度。在节点层面中可以根据整个GPU卡使用情况支持binpack/spread不同的调度策略,在调度器中可以感知到物理卡以满足用户调度需求。
qGPU算力隔离策略
在底层算力隔离层面,除了强隔离方式以外还支持:
-
Best Effort(争抢模式):默认值。各个Pod不限制算力,只要卡上有剩余算力就可使用,如果一共启动N个Pod,每个Pod负载都很重,则最终结果就是1/N的算力;
-
Fixed Share(固定配额):每个Pod有固定的算力配额,无法超过该配额,即使GPU还有空闲算力;
-
Burst Share(弹性配额):调度器保证每个Pod有保底的算力配额,但只要GPU还有空闲算力,就可被Pod使用。例如,当GPU有空闲算力时(没有分配给其他Pod),Pod可以使用超过它的配额的算力。注意,当它所占用的这部分空闲算力再次被分配出去时,Pod会退掉它的算力配额。
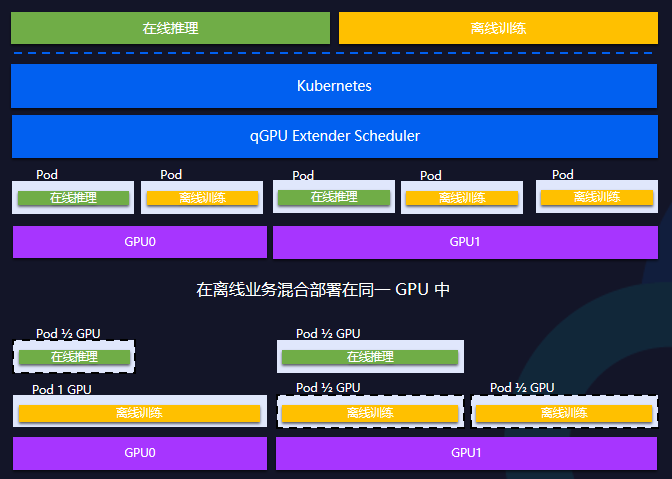
qGPU在离线混部
在qGPU层面支持高优和低优两种Pod定义,比如在线推理一般是高优Pod,低优任务一般是离线训练。但低优任务GPU利用率占有较高,可以使用闲置资源。
有了在离线混部技术之后,可以将在线推理设置成高优Pod,将离线训练设置成低优Pod,把高优推理打散分布,能保证在线业务有需求时把GPU底层资源100%抢占,这样在线推理业务总能使用GPU资源,并且支持离线使用空闲资源,利用率可从50%提升到100%。
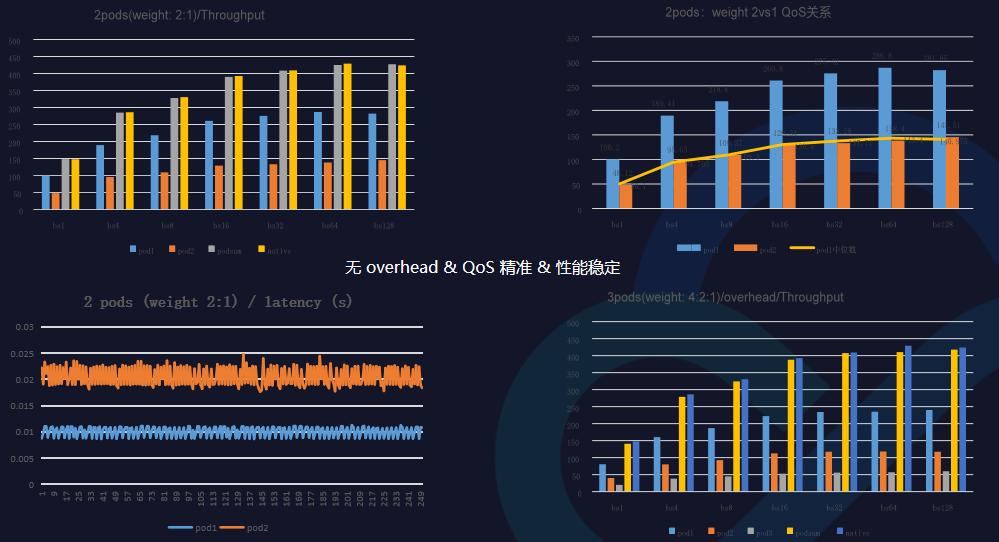
qGPU性能
要做共享就要先保证隔离,判断隔离的好坏在于:
-
吞吐不能因为有共享之后降低;
-
延迟不能因为有共享之后有很大抖动;
-
单个Pod只占用申请部分资源。
最终我们做到了强隔离以及通过GPU共享方式做到提高资源利用率,降低成本。
qGPU实际收益
-
已帮助上万GPU提升利用率;
-
提升在线推理70%利用率;
-
在离线混部提升100%;
-
平均增加100%部署密度。

总结
本次分享,介绍了如何使用云原生的方式管理GPU资源以及通过qGPU共享方式提高GPU使用率,降低了集群层面GPU资源的管理难易程度,使用效率得到提升。
【原动力×云原生正发声降本增效大讲堂】第一期聚焦在优秀实践方法论、资源与弹性、架构设计;第二期聚焦全场景在离线混部、K8s GPU资源效率提升、K8s资源拓扑感知调度主题,点击『此处』进入活动专题,带你体验云原生降本增效实践案例、了解如何解决企业用云痛点、掌握降本增效关键技能……
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。