
内核定时器
软件上的定时器最终要依靠硬件时钟来实现,简单的说,内核会在时钟中断发生后检测各个注册到内核的定时器是否到期,如果到期,就回调相应的注册函数,将其作为中断底半部来执行。实际上,时钟中断处理程序会触发TIMER_SOFTIRQ软中断,运行当前处理器上到期的所有定时器。
设备驱动程序如要获得时间信息以及需要定时服务,都可以使用内核定时器。
【文章福利】笔者推荐自己的Linux内核源码交流群:【869634926】整理了一些个人觉得比较好的Linux内核学习书籍、视频资料共享在群里面,有需要的可以自行添加哦!
jiffies
要说内核定时器,首先就得说说内核中关于时间的一个重要的概念:jiffies变量,作为内核时钟的基础,jiffies每隔一个固定的时间就会增加1,称为增加一个节拍,这个固定间隔由定时器中断来实现,每秒中产生多少个定时器中断,由在<linux/param.h>中定义的HZ宏来确定,如此,可以通过jiffies获取一段时间,比如jiffies/HZ表示自系统启动的秒数。下两秒就是(jiffies/HZ+2),内核中用jiffies来计时,秒转换成的jiffies:seconds*HZ,所以以jiffiy为单位,以当前时刻为基准计时2秒:(jiffies/HZ+2)*HZ=jiffies+2*HZ如果要获取当前时间,可以使用do_gettimeofday(),该函数填充一个struct timeval结构,有着接近微妙的分辨率。
//kernel/time/timekeeping.c
473 /**
474 * do_gettimeofday - Returns the time of day in a timeval
475 * @tv: pointer to the timeval to be set
476 *
477 * NOTE: Users should be converted to using getnstimeofday()
478 */
479 void do_gettimeofday(struct timeval *tv)
驱动程序为了让硬件有足够的时间完成一些任务,常常需要将特定的代码延后一段时间来执行,根据延时的长短,内核开发中使用长延时和短延时两个概念。长延时的定义为:延时时间>多个jiffies,实现长延时可以用查询jiffies的方法:
time_before(jiffies, new_jiffies);
time_after(new_jiffiesmjiffies);
短延时的定义为:延迟事件接近或短于一个jiffy,实现短延时可以调用
udelay();
mdelay();
这两个函数都是忙等待函数,大量消耗CPU时间,前者使用软件循环来延迟指定数目的微妙数,后者使用前者的嵌套来实现毫秒级的延时。
定时器
驱动可以注册一个内核定时器,来指定一个函数在未来某个时间来执行。定时器从注册到内核开始计时,达到指定的时间后会执行注册的函数。即超时值是一个jiffies值,当jiffies值大于timer->expires时,timer->function就会被执行。API如下
//定一个定时器
struct timer_list my_timer;
//初始化定时器
void init_timer(struct timer_list *timer);
mytimer.function = my_function;
mytimer.expires = jiffies +HZ;
//增加定时器
void add_timer(struct timer_list *timer);
//删除定时器
int del_tiemr(struct timer_list *timer);
实例
static struct timer_list tm;
struct timeval oldtv;
void callback(unsigned long arg)
{
struct timeval tv;
char *strp = (char*)arg;
do_gettimeofday(&tv);
printk("%s: %ld, %ld\n", __func__,
tv.tv_sec - oldtv.tv_sec,
tv.tv_usec- oldtv.tv_usec);
oldtv = tv;
tm.expires = jiffies+1*HZ;
add_timer(&tm);
}
static int __init demo_init(void)
{
init_timer(&tm);
do_gettimeofday(&oldtv);
tm.function= callback;
tm.data = (unsigned long)"hello world";
tm.expires = jiffies+1*HZ;
add_timer(&tm);
return 0;
}
延迟工作
除了使用内核定时器完成定时延迟工作,Linux内核还提供了一套封装好的"快捷方式"-delayed_work,和内核定时器类似,其本质也是利用工作队列和定时器实现,
//include/linux/workqueue.h
100 struct work_struct {
101 atomic_long_t data;
102 struct list_head entry;
103 work_func_t func;
104 #ifdef CONFIG_LOCKDEP
105 struct lockdep_map lockdep_map;
106 #endif
107 };
113 struct delayed_work {
114 struct work_struct work;
115 struct timer_list timer;
116
117 /* target workqueue and CPU ->timer uses to queue ->work */
118 struct workqueue_struct *wq;
119 int cpu;
120 };
struct work_struct
--103-->需要延迟执行的函数, typedef void (*work_func_t)(struct work_struct *work);
至此,我们可以使用一个delayed_work对象以及相应的调度API实现对指定任务的延时执行
//注册一个延迟执行
591 static inline bool schedule_delayed_work(struct delayed_work *dwork,unsigned long delay)
//注销一个延迟执行
2975 bool cancel_delayed_work(struct delayed_work *dwork)
和内核定时器一样,延迟执行只会在超时的时候执行一次,如果要实现循环延迟,只需要在注册的函数中再次注册一个延迟执行函数。
schedule_delayed_work(&work,msecs_to_jiffies(poll_interval));
DMA编程
DMA即Direct Memory Access,是一种允许外设直接存取内存数据而没有CPU参与的技术,当外设对于该块内存的读写完成之后,DMAC通过中断通知CPU,这种技术多用于对数据量和数据传输速度都有很高要求的外设控制,比如显示设备等。
DMA和Cache一致性
我们知道,为了提高系统运行效率,现代的CPU都采用多级缓存结构,其中就包括使用多级Cache技术来缓存内存中的数据来缓解CPU和内存速度差异问题。在这种前提下,显而易见,如果DMA内存的数据已经被Cache缓存了,而外设又修改了其中的数据,这就会造成Cache数据和内存数据不匹配的问题,即DMA与Cache的一致性问题。为了解决这个问题,最简单的办法就是禁掉对DMA内存的Cache功能,显然,这会导致性能的降低
虚拟地址 VS 物理地址 VS 总线地址
在有MMU的计算机中,CPU看到的是虚拟地址,发给MMU后转换成物理地址,虚拟地址再经过相应的电路转换成总线地址,就是外设看到的地址。所以,DMA外设看到的地址其实是总线地址。Linux内核提供了相应的API来实现三种地址间的转换:
//虚拟->物理
virt_to_phys()
//物理->虚拟
ioremap()
//虚拟->总线
virt_to_bus()
//总线->虚拟
bus_to_virt()
DMA地址掩码
DMA外设并不一定能在所有的内存地址上执行DMA操作,此时应该使用DMA地址掩码
int dma_set_mask(struct device *dev,u64 mask);
比如一个只能访问24位地址的DMA外设,就使用dma_set_mask(dev,0xffffff)
编程流程
下面是在内核程序中使用DMA内存的流程:
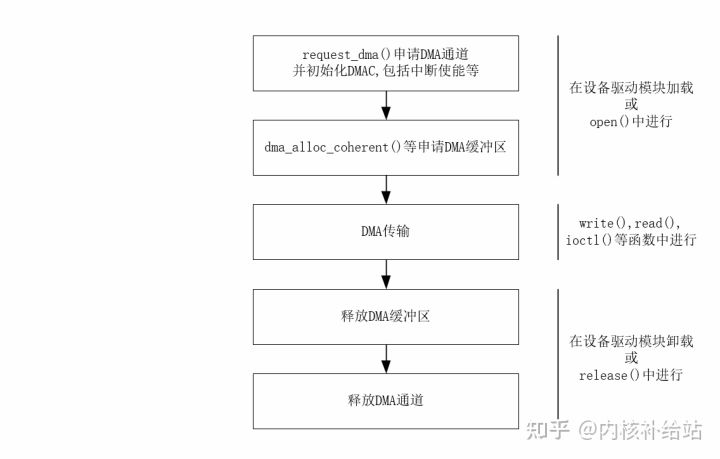
一致性DMA
如果在驱动中使用DMA缓冲区,可以使用内核提供的已经考虑到一致性的API:
/**
* request_dma - 申请DMA通道
* On certain platforms, we have to allocate an interrupt as well...
*/
int request_dma(unsigned int chan, const char *device_id);
/**
* dma_alloc_coherent - allocate consistent memory for DMA
* @dev: valid struct device pointer, or NULL for ISA and EISA-like devices
* @size: required memory size
* @handle: bus-specific DMA address *
* Allocate some memory for a device for performing DMA. This function
* allocates pages, and will return the CPU-viewed address, and sets @handle
* to be the device-viewed address.
*/
void * dma_alloc_coherent(struct device *dev, size_t size, dma_addr_t *dma_handle, gfp_t flag)
//申请PCI设备的DMA缓冲区
void *pci_alloc_consistent(struct pci_dev *hwdev, size_t size, dma_addr_t *dma_handle)
//释放DMA缓冲区
void dma_free_coherent(struct device *dev, size_t size, void *cpu_addr, dma_addr_t dma_handle )
//释放PCI设备的DMA缓冲区
void pci_free_consistent()
/**
* free_dma - 释放DMA通道
* On certain platforms, we have to free interrupt as well...
*/
void free_dma(unsigned int chan);
流式DMA
如果使用应用层的缓冲区建立的DMA申请而不是驱动中的缓冲区,可能仅仅使用kmalloc等函数进行申请,那么就需要使用流式DMA缓冲区,此外,还要解决Cache一致性的问题。
/**
* request_dma - 申请DMA通道
* On certain platforms, we have to allocate an interrupt as well...
*/
int request_dma(unsigned int chan, const char *device_id);
//映射流式DMA
dma_addr_t dma_map_single(struct device *dev,void *buf, size_t size, enum dma_datadirection direction);
//驱动获得DMA拥有权,通常驱动不该这么做
void dma_sync_single_for_cpu(struct device *dev,dma_addr_t dma_handle_t bus_addr,size_t size, enum dma_data_direction direction);
//将DMA拥有权还给设备
void dma_sync_single_for_device(struct device *dev,dma_addr_t dma_handle_t bus_addr,size_t size, enum dma_data_direction direction);
//去映射流式DMA
dma_addr_t dma_unmap_single(struct device *dev,void *buf, size_t size, enum dma_datadirection direction);
/**
* free_dma - 释放DMA通道
* On certain platforms, we have to free interrupt as well...
*/
void free_dma(unsigned int chan);
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。