
Node.js学习课程的安排

Node.js最大的特点就是:非阻塞IO和事件驱动、模块化驱动
Node的基础概念
1)node命令的基本用法
(1)进入REPL环境:
node,进入REPL环境 .exit 在REPL环境,可以测试Node的一些代码和模块
进入window的Powershell环境:cmd 执行:powershell 通过命令行执行代码:node -e 'console.log('1');' //这里的-e相当于eval(),node -e 的作用就是执行js代码
(2)执行脚本字符串:node -e 'console.log(hello world)'
(3)运行脚本文件:node index.js node path/index.js node/path/index
(4)查看帮助:node -help
(5)使用严格模式:node --use_strict
2)REPL(Read/Eval/Print/Loop)环境

3)全局对象
(1)global-----类似客户端Js运行环境中的window对象
(2)process---获取当前node进程信息,一般用于获取环境变量之类的信息
process.exit()-----终止当前node的进程
process.argv.slice(2)-------获取输入参数,一般前两个参数无用,所以直接获取后面的参数
process.argv = ['node执行程序所在路径','当前脚本所在路径',arguments1,arguments2,....]process.env------获取当前系统的环境变量
process.stdin------输入 process.stdin.setEncoding('utf8');
输入有两个坑:(1)输入的数据为一个对象(二进制数组) (2)输入的字符最后一定是enter,所以要通过trim()去掉前后空白字符
// 一旦有数据流入,enter就会触发箭头函数
process.stdin.on('data',(input) => {
// 由于这里是输入流(二进制数组),所以为对象
// input---typeof(input) = 'obect'
// 输入的字符最后肯定是一个回车符
// 需要将回车符去掉,否则会永远不符合条件
input = input.trim();
process.stdout.write(input);
})
process.stdout-----输出 process.stdout.write('hello')
清空控制台:process.stdout.getWindowSize() process.stdout.write('\033[2]') process.stdout.write('\033[of')
process.stdout.getWindowSize() / / [160,30]---控制台的宽和高
那清空控制台的方法:就是在控制台输出30行的空行
//清空控制台的方法
var len = process.stdout.getWindowSize();
for(var i=0;i<len;i++){
process.stdout.write('\n');
}(3)console---node中内置的console模块,提供操作控制台的输入输出功能,常见使用方式与客户端类似
// console.tome(flag)----计时开始处,flag---标志位
// console.timeEnd(flag)----计时结束处,flag和上面相同
//启动计时器
console.time('main');
for(var i =0;i<100000;i++){
}
//结束计时器
console.timeEnd('main');
4)全局变量
5)全局函数
6)异步操作之回调函数
进程:打开任务管理器,可以在进程栏下面看到的名字就是正在运行的进程,每一种软件在打开过后,在内存当中的一种形态或者说是一个单元,可以是或是一个进程。
比如,在文件下面有一个.exe的文件它只是一个可执行文件不是进程,当双击它,在内存当中给他开辟一个空间就可以说是一个进程,进程与进程之间相互隔离
node调试
1)最方便最简单的调试方式:console.log()
2)node原生的调试:https://nodejs.org/api/debugger.html
3)第三方模块提供的调试工具
---npm install node-inspector -g
---npm install devtool -g
4)开发工具的调试:vs code webstorm
node编程中的一些约定俗成的习惯
回调函数的设计
1)callback作为函数参数的最后一个参数出现(让回调函数可选)
function fool(name,age,callbak){}
2)callback的第一个参数默认是错误信息,第二个参数才是真正回调的数据(便于外界获取调用的错误情况)
fool('jiang',1,fucntion(err,data){
if(err){
throw err;
}
console.log(data);
})强调错误优先
1)之后的操作都是异步操作,无法通过try catch捕获异常
2)错误优先的回调函数,第一个参数为上一步的错误信息
模块化结构
Node实现CommonJS规范,所以可以使用模块化的方式组织代码结构
模块化代码结构
1)Node采用的模块化结构,是按照CommonJS规范
2)模块与文件是一一对应的关系,即加载一个模块,实际上就是加载对应的一个模块文件
模块的分类
1)文件模块-----自己写的功能模块
2)核心模块-----Node平台自带的一套基本的功能吗,模块,也有人称为NoDEpingtai de API
3)第三方模块----社区或第三方个人开发好的功能模块,可以直接拿来使用
模块化开发的流程
1)创建模块
2)导出成员
3)载入模块
4)使用模块
模块内全局环境(伪)-----每个模块的内部都是私有空间
在之后的文件操作中必须使用绝对路径
1)__dirname:
用于获取当前文件所在目录的完整路径(路径就是不包含文件名的路径);
在REPL环境无效;
2)__filename:
获取当前文件的完整路径(路径就是包含文件名的完整路径);
在REPL环境功能失效
// 在e:\vue-exercise\node\module1\module1.js定义如下内容
console.log(__dirname); //输出当前文件的上级目录
console.log(__filename);//输出文件的完孩子能路径
//在e:\vue-exercise\node\index.js中引进module1.js
const module1 = require('./module1/module1');
输出的结果是:
e:\vue-exercise\node\module1
e:\vue-exercise\node\module1\module1.js3)module----模块对象,导出成员
//e:\node\index.js
console.log(module);
module对象的简介

module的定义

4)exports-----映射到module.exports的别名
5)require()-----载入模块
----require.cache
----require.extensions
----require.main
----require.resolve()
在Node中引入模块的时候,书写路径要小心:
1)require('fs');//表示引进的是系统自带的模块。保存在根目录下的node_modules文件夹下
路径中没有“./”,则先从系统模块中找,然后在到node_modules中找
2)require('./index.html'); //以这种方式引进的文件表示是开发者自己开发的文件
如果想把自己写的模块引入的路径方式和系统一样,则把自己写的模块放到项目的根目录下的node_modules文件夹下
自己实现一个基础功能的$require
// 自己写一个require函数
//id是一个相对路径
function $require(id){
// 1、先找到文件,文件不存在则提示
// 2、读取文件内容,内容是js代码
const fs = require('fs');
const path = require('path');
// 要加载的js文件完整路径
const filename = path.join(__dirname,id);
// 加载文件的上级目录
const dirname = path.dirname(filename);
// 加载的Js文件的内容(js代码)
// readFileSync()是一个同步函数,不会放进事件队列,会阻塞后面代码的执行
let code = fs.readFileSync(filename);
// 3、执行代码,所要执行的代码需要营造一个私有空间
let module = {id:filename,exports:{}};
let exposrts = module.exports;
// 立即执行函数,创造私有空间
code = `
(function($require,module,exports,__dirname,__filename){
${code}
})($require,dirname,filename)`;
// 执行
eval(code);
// 4、返回值
return module.exports;
}
// 验证自己写的require函数
let m = $require('./index.js');require简介

module的加载机制
1)id:路径的情况就是直接以相对路径的方式找文件
require('./index.js')2)require加载文件时可以省略扩展名:
如下面的例子,在e:\node\day下面有文件module1.js module.json module1.node output.js 和文件夹module1
在文件夹module1下有文件index.js package.json default.js,如下图所示
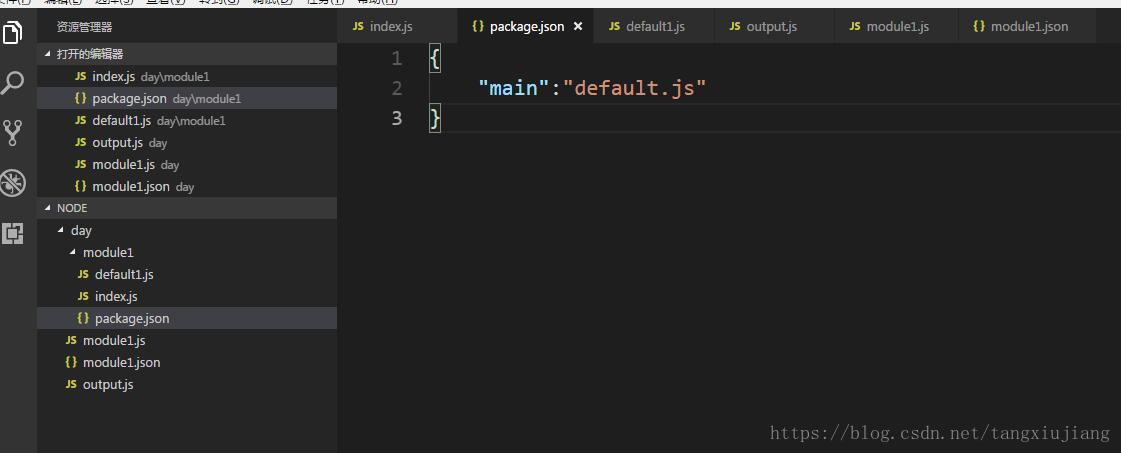
在output.js文件的内容如下:
var module1 = require('./module1');
console.log(module1);加载的顺序是:(越详细越先加载)
(1)如果在module1下还有同名文件夹module1,并且在文件夹module1下有package.json,里面的main属性指向的js文件,如default1.js刚好在该文件夹下定义,那就执行default1.js文件里面的内容,否则执行第二步
(2)会在output.js的同一目录下是否有module1.js文件,如果有的话,就执行module1.js文件,否则执行第三步
(3)会在output.js的同一目录下是否有module1.json文件,如果有的话,就执行module1.json文件,否则执行第四步
(4)会在output.js的同一目录下是否有module1.node文件,如果有的话,就执行module1.node文件,否则执行第五步
(5)会在output.js的同一目录下是否有module1文件夹,如果有的话会检查该文件夹下是否有index.js文件,如果有的话就执行该文件
3)通过./ ../开头:则按照相对路径从当前文件所在文件夹开始寻找模块
4)通过/开头:则以系统根目录开始寻找模块
5)如果参数字符串不以“./”或“/”开头,则表示加载的是一个默认提供的核心模块(位于Node安装目录下)
require('fs')6)从当前目录向上搜索node_modules目录中的文件(就近原则)(模块包定义在node_modules文件夹下,可以不用点斜线通过require('fs')形式引进去)
//各级node_modules文件夹中搜素my_module.js文件
require('my_module')7)模块名重复,系统模块的优先级最高
通过npm将自己写的模块发布到npmjs.org官网上,从而让别人可以下载你写的模块
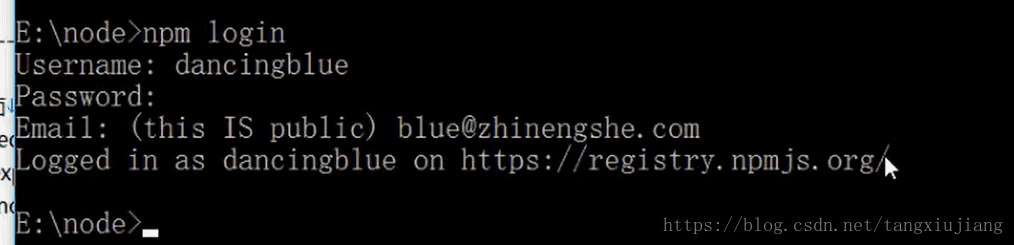
1)在这个链接上注册一个npm账号:https://www.npmjs.com/signup
2)在cmd中登录npm账号,如下图所示:
在cmd下cd到一个文件夹路径下,通过一下步骤实现发布包的功能
1)npm init //初始化下一个文件夹 ,然后再文件夹下会多出一个 package.json文件
2)和package.json同级下有个index.js文件,在里面书写你要发布的Module的内容
3)npm publish 发布你的模块
4)npm update 更新你的模块
5)npm --force unpublish 删除你的模块(一次只能删除一个版本)
模块的缓存----提高应用程序的下载速度
如何删除缓存?缓存的实现机制
1)第一次加载某个模块的时候,Node会缓存该模块,以后再加载该模块,直接从缓存取出该模块的module.exports属性(不回再次执行该模块)
2)如果需要多次执行模块中的代码,一把可以让模块暴露行为(函数)
3)模块的缓存可以通过require.cache拿到,删除
// 删除缓存中某个属性
Object.keys(require.cache).forEach((key) =>{
delete require.cache[key];
})
缓存的实现----用静态变量实现
主要代码如下:
// 缓存的是module对象,返回的是module.exports中的值
// 定义一个静态变量
$require.cache = $require.cache || {};
// 如果有缓存,直接输出module对象中的exports属性的值
if( $require.cache[filename] ){
// 有缓存
return $require.cache[filename].exports;
}
// 没有缓存,则记录一下缓存
$require.cache = module;完整如下
// 自己写一个require函数
//id是一个相对路径
function $require(id){
// 1、先找到文件,文件不存在则提示
// 2、读取文件内容,内容是js代码
const fs = require('fs');
const path = require('path');
// 要加载的js文件完整路径
const filename = path.join(__dirname,id);
// 加载文件的上级目录
const dirname = path.dirname(filename);
// 加载的Js文件的内容(js代码)
// readFileSync()是一个同步函数,不会放进事件队列,会阻塞后面代码的执行
let code = fs.readFileSync(filename);
// 缓存的是module对象,返回的是module.exports中的值
// 定义一个静态变量
$require.cache = $require.cache || {};
// 如果有缓存,直接输出module对象中的exports属性的值
if( $require.cache[filename] ){
// 有缓存
return $require.cache[filename].exports;
}
// 3、执行代码,所要执行的代码需要营造一个私有空间
let module = {id:filename,filename)`;
// 执行
eval(code);
// 没有缓存,则记录一下缓存
$require.cache = module;
// 4、返回值
return module.exports;
}
// 验证自己写的require函数
let m = $require('./index.js');
常用内置模块清单
1)path:处理文件路径
2)fs:操作文件系统
3)child_process:新建子进程
4)util:提供一系列实用小工具
5)http:提供HTTP服务功能
6)querystring:解析URL中的查询字符串
7)crypto:提供加密和解密功能
MD5加密:输入任意长度的字符串,输出32位的16进制字符
特点:由于MD5加密是一个不可逆的过程,不能由加密的字符得到原文内容
包的概念--npm---node package manage
1)由于Node是一套轻内核的平台,虽然提供了一系列的内置模块,但不足以满足开发者的需求,于是出现包的概念
2)与核心模块类似,就是将一些预先定义好的功能模块
NPM有两层概念:
1)node的开放性模块登记和管理系统,或者生态圈(社区)
2)Node默认的模块管理器,是一个命令行下的软件,用来安装和管理node模块(统一下载路径,自动下载依赖)
将npm更新到最新版本:npm install npm -g
//将Npm安装的包都安装到这个目录 里面,同时还要设置环境变量
设置路径:npm config set prefix 路径(c:\develop\nvm\npm)(就是nvm文件夹下的npm)
获取路径:npm config get prefix
包的加载机制
1)id:包名的情况:require('http')----先在系统核心(优先级最高)的模块中找;然后在在当前项目中的node_modules中找
npm常用的命令
npm config----配置
npm init ------ 初始化
npm install ---- 安装依赖
npm uninstall ----卸载包
npm info 包的id-----打印包的一些信息
npm list----打印出当前项目的所有依赖项
npm outdated----看一下哪些包没有更新
npm update----包的更新
npm run---运行在package中定义的一些脚本
npm cache----操作 缓存
文件操作系统 ---- fs
在文件操作过程中,必须使用物理路径(绝对路径)
fs-extra(第三方):https://www.npmjs.com/package/fs-extra
fs.mkdir(‘c:\vue\nodejs’):创建文件夹nodejs,需要注意里面书写的路径c:\vue一定要已经存在了,否则报错
路径模块---path
1)path.join([p1][,p2]...) => 连接多个路径
2)path.dirname(p) => 获取文件夹路径
3)path.filename(p) => 获取文件的完整路径
4)path.basename(p,ext) => (例如.txt) 获取文件名(不包含扩展名)
5)path.extname(p) => 获取文件的扩展名(包含点)
6)path.format(obj)和path.parse(p) => 获取路径中所有的信息,
将一个路径字符串转化为一个对象(包括文件目录,文件名,扩展名)
7)path.relative(from,to) => 获取to相对于from的相对路径
8)path.delimiter => 路径的分隔符(windows下是; linux是:)
获取环境变量下的所有路径:process.env.PATH.split(path.delimiter)
9)path.sep => 获取当前操作系统中默认用的路径成员分隔符 windows:\ linux:/
10)path.isAbsolute(path)---判断路径是否是绝对路径
11)path.normalize(p) -- 常规化一个路径
12)path.resolve([from...],to)----效果跟join差不多
与join不同:path.resolve(__dirname,'c:/dev','./','./code')----c:/dev/code
13)path.win32 => 指的是windows,允许在任意操作系统上使用windows的方式操作路劲
14)path.posix => 指的是linux, 允许在任意操作系统上使用linux的方式操作路径
同步或异步的区别
1)同步调用会阻塞代码的执行,异步不会
2)异步调用,会将读取到的任务下达到任务队列中,知道任务执行完成才会回调
3)异常处理方面:同步必须使用try catch,异步可以通过回调函数的第一个采纳数
// 异步
fs.readFile(path,'utf8',(err,data)=>{
if(err){
throw err;
}
})
// 同步
try{
fs.readFileSync(path,'utf8')
}catch(err){
throw err
}
Buffer(缓冲区)
读取文件的时候没有指定编码,默认读取的是一个Buffer(缓冲区)
定义
1)缓冲区就是内存中操作数据的容器,只是数据容器而已
2)通过缓冲区很方便的操作二进制数据,而且在大文件操作时必须有缓冲区
为什么需要缓冲区
1)js比较擅长处理字符串
2)在node中操作数据、网路通信是没有办法完全以字符串的方式操作的
3)所有在Node中引入一个二进制的缓冲区的实现:buffer
iconv-lite插件用于在Node中读取文件处理各种特别字符
readline模块----一行行的读取文件内容
序列化数据:JSON.stringify()
反序列化数据:JSON.parse()
读文件是不存在错误的
写文件发生的错误:1)意外错误 2)文件权限问题 3)文件夹找不到
流的定义
1)流是程序输入或输出的一个连续的字节序列
2)文件流、网络流
3)设备的输入和输出都是用流来处理的
文件流的定义
1)文件流就是以面向对象的概念对文件数据的抽象
2)文件流定义了一些对文件数据的操作方式
node.js中常用到的模块
1)加密----Crypto
2)事件-----Event
3)网络操作----Net
4)操作系统信息-----OS
5)处理文件路径----Path
6)流操作----Stream
7)定时器----Timers
8)压缩---ALIB
原文地址:https://blog.csdn.net/tangxiujiang
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。