
1. 样本量极少可以训练机器学习模型吗?
在训练样本极少的情况下(几百个、几十个甚至几个样本),现有的机器学习和深度学习模型普遍无法取得良好的样本外表现,用小样本训练的模型很容易陷入对小样本的过拟合以及对目标任务的欠拟合。但基于小样本的模型训练又在工业界有着广泛的需求(单用户人脸和声纹识别、药物研发、推荐冷启动、欺诈识别等样本规模小或数据收集成本高的场景),Few-Shot Learning(小样本学习)通过将有限的监督信息(小样本)与先验知识(无标记或弱标记样本、其他数据集和标签、其他模型等)结合,使得模型可以有效的学习小样本中的信息。
在介绍Few-Shot Learning的基本原理之前,首先需要知道用小样本训练模型究竟会导致什么问题。机器学习的目标就是尽可能降低模型结果与真实结果的误差,而这个误差可以进一步分解成两部分:
- approximation error:基于现有的特征和算法能训练的最优模型h*能达到的表现,跟理论上最优模型h^的表现的差距
- estimation error:实际训练的模型h_I的表现与基于现有的特征和算法能训练的最优模型h*能达到的表现的差距;
在小样本任务中,用小样本训练的模型很容易陷入对小样本的过拟合以及对目标任务的欠拟合,导致实际训练的模型h_I的表现与基于现有的特征和算法能训练的最优模型h*能达到的表现的差距无法通过训练和超参数调整有效的缩小,使模型的整体表现较差(基于足量样本训练的模型和基于小样本训练的模型分别见fig. 1的a和b)。
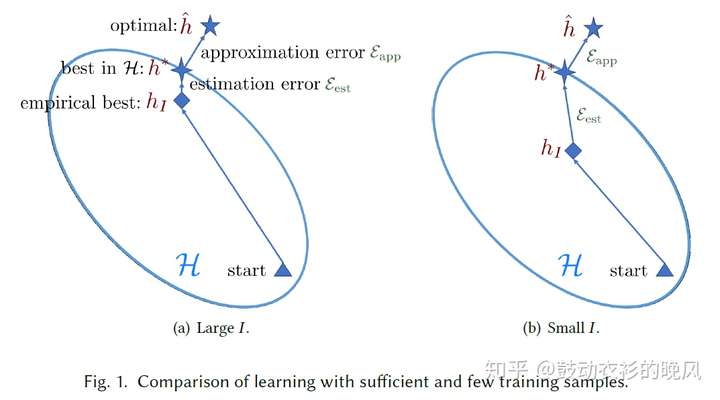
根据机器学习模型在小样本上难以学习的原因,Few-Shot Learning从三个角度解决问题,(1)通过增多训练数据提升h_I(Data)、(2)缩小模型需要搜索的空间(Model)、以及(3)优化搜索最优模型的过程(Algorithm)。
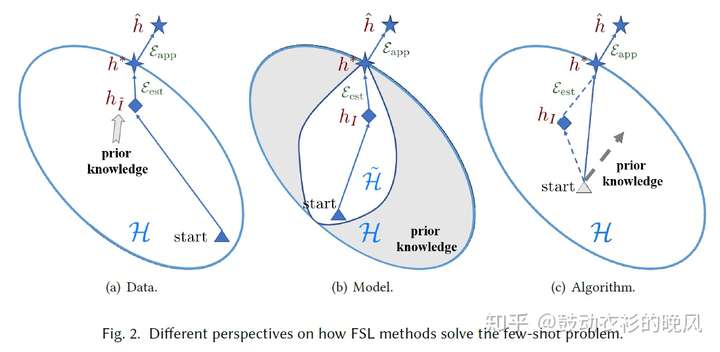
PS: 上面两张图均引自2020年香港科技大学和第四范式的paper“Generalizing from a Few Examples: A Survey on Few-Shot Learning”。
2. Few-Shot Learning概述
下面将逐个介绍第一部分提到的Few-Shot Learning的三大思路下的方法。
2.1 增多训练数据
通过prior knowledge增多训练数据 (Experience),方法主要分为3类:
(1)数据增强(Data Augmentation)类方法。较初级的数据增强方法是人工制定规则,包括对图片样本进行旋转、翻转、裁剪、增加噪音等操作,但此类方法不足以有效提升模型的泛化能力,规则的制定也依赖领域知识,通常难以做到在多个数据集之间通用;高阶的数据增强方法利用其他数据集的信息生成更多目标class的样本,通过模型(多为encoder-decoder结构)学习样本内和样本外的变化分布并生成新样本,基于样本外信息(有监督)的模型可以将图片映射为的不同的天气、景深、角度等,基于样本内变化(无监督)的模型则学习其他class的样本内部变化(如图片的不同视角)并应用于目标的小样本class上。数据增强类方法可与其他Few-Shot Learning方法同时使用,普遍用于计算机视觉场景,但部分高阶方法有应用于其他场景的潜力。关于数据增强类方法的更多介绍和reference见2020年清华和滴滴的paper"Learning from Very Few Samples: A Survey"。
(2)基于弱标记样本或无标记样本得到更多目标class样本,主要包括半监督学习和主动学习两类。半监督学习的典型例子是Positive-Unlabeled Learning,很多Two-step算法通过正样本和无标记样本训练分类器,直接扩大正样本规模、或利用分类器权重让无标记样本参与到正样本的学习中(详见Charles Elkan和Keith Noto 2008发表的"Learning Classifiers from Only Positive and Unlabeled Data");而主动学习选择对模型训练最“有用”的样本进行标注。半监督学习和主动学习适合有大量无标记数据、但样本标注成本较高的场景。
(3)基于目标Class的小样本数据训练GAN,直接生成目标class的更多样本。适用于仅有小样本、无标记样本很难收集的场景。
2.2 缩小模型需要搜索的空间
通过prior knowledge缩小模型需要搜索的空间(hypothesis space),多为meta-learning类方法。
(1)Multi-task learning:
用神经网络同时学习多个任务,使一部分隐藏层关注跨任务的通用信息、一部分隐藏层关注特定任务的信息。在学习过程中,一个任务的模型参数被其他任务约束,即任务之间会有类似正则化的效果。分为直接在不同任务间共享部分隐藏层的参数的parameter sharing类方法,和惩罚不同任务的参数差异的parameter typing类方法。此类方法的缺点也很明显,用于训练的多个任务(包括目标的小样本在内)若不够相似(理想状况下各个任务都属于一个多分类任务)则会影响最终学习效果,且同时训练多个任务的计算成本很高、速度很慢。详细介绍和reference见2020年香港科技大学和第四范式的paper“Generalizing from a Few Examples: A Survey on Few-Shot Learning”。
(2)Embedding learning:
将样本投影到更易区分不同class的低维空间,维度更低、特征表示更容易区分不同class意味着模型需要搜索的空间更小,即降维。用于投影的embedding function通常从prior knowledge中学习,也可以利用目标class的小样本的信息。Metric Learning和Meta-Learning中的Learn-to-Measure类算法均属于这一类别,通过学习embedding function (训练数据的f(x)和测试数据的g(x)),采用训练样本和测试样本的embedding的相似度作为测试样本属于相应训练样本的class的概率,相似度可以采用相似度指标(Euclidean、Cosine等)或可学习的相似度模型(神经网络)。此类算法的详细介绍见2020年香港科技大学和第四范式的paper“Generalizing from a Few Examples: A Survey on Few-Shot Learning”的4.2和4.3.1。
(3)Learning with external memory
记忆网络,常用于NLP场景和问答系统,从训练数据中学习key-value pair作为一个个记忆,与embedding learning相似需要学习一个embedding function f,但需要计算相似度的是样本的embedding f(x)和记忆库里的key,最相似的value作为该样本的embedding(或取多个最相似的value的加权平均),随后输入一个简单的分类器(e.g. softmax)。将query样本的embedding限制为记忆库里的value极大的缩小了模型需要搜索的空间(hypothesis space),但为了学习和存储记忆,此类方法通常需要较大的空间占用和计算成本。
(4)Generative Modeling
借助prior knowledge估计样本概率分布p(x|y)和p(y),以latent variable的形式参与到小样本任务的训练中,缩小模型需要搜索的空间(hypothesis space)。latent variable可以有三种表现形式,decomposable components(例如人脸识别场景中的鼻子、眼睛、嘴)、group-wise shared prior(小样本任务可能与其他任务相似,那么其他任务的概率分布就可以作为小样本任务的先验概率)、parameters of inference networks(基于大规模数据集训练推断网络并直接用于小样本任务,基于VAE和GAN的居多),详细reference见2020年香港科技大学和第四范式的paper“Generalizing from a Few Examples: A Survey on Few-Shot Learning”的4.4.3。
2.3 优化搜索最优模型的过程
通过prior knowledge优化在hypothesis space中搜索最优模型的过程(即模型训练过程)。包括refine existing parameters(迁移学习)、refine meta-learned parameters(Meta-Learning中的Learn to fine-tune和learn to parameterize均属于这个类别,借助meta-learner帮助base learner更快的收敛)、learn the optimizer(训练meta-learner指导梯度下降的方向和步长)。此类方法可以极大加快搜索最优模型的过程,但存在为了速度牺牲精度的成分、且受元学习领域常见的难题的影响较大(例如如何在不同粒度的任务间元学习 e.g. 动物物种和狗的种类,以及如何避免元学习时不同任务对参数的影响的相互中和)。
转载于:
https://zhuanlan.zhihu.com/p/290011942?utm_source=wechat_timeline
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。