
一、为什么要正则化
学习算法,包括线性回归和逻辑回归,它们能够有效地解决许多问题,但是当将它们应用到某些特定的机器学习应用时,会遇到过拟合(over-fitting)的问题,可能会导致它们效果很差。正则化(regularization)技术,可以改善或者减少过度拟合问题,进而增强泛化能力。泛化误差(generalization error)= 测试误差(test error),其实就是使用训练数据训练的模型在测试集上的表现(或说性能 performance)好不好。
如果我们有非常多的特征,我们通过学习得到的假设可能能够非常好地适应训练集(代价函数可能几乎为0),但是可能会不能推广到新的数据。
下图是一个回归问题的例子:

第一个模型是一个线性模型,欠拟合,不能很好地适应我们的训练集;第三个模型是一个四次方的模型,过于强调拟合原始数据,而丢失了算法的本质:预测新数据。我们可以看出,若给出一个新的值使之预测,它将表现的很差,是过拟合,虽然能非常好地适应我们的训练集但在新输入变量进行预测时可能会效果不好;而中间的模型似乎最合适。
分类问题中也存在这样的问题:
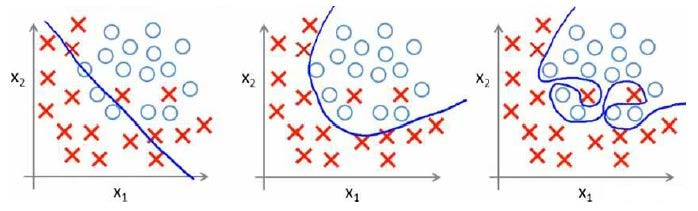
就以多项式理解,$x$的次数越高,拟合的越好,但相应的预测的能力就可能变差。
如果我们发现了过拟合问题,可以进行以下处理:
1、丢弃一些不能帮助我们正确预测的特征。可以是手工选择保留哪些特征,或者使用一些模型选择的算法来帮忙(例如PCA)。
2、正则化。 保留所有的特征,但是减少参数的大小(magnitude)。
二、正则化的定义
正则化的英文 Regularizaiton-Regular-Regularize,直译应该是"规则化",本质其实很简单,就是给模型加一些规则限制,约束要优化参数,目的是防止过拟合。其中最常见的规则限制就是添加先验约束,常用的有L1范数和L2范数,其中L1相当于添加Laplace先验,L相当于添加Gaussian先验。
三、L1正则和L2正则
在介绍L1范数、L2范数之前,我们先介绍以下LP范数。
3.1 范数
范数简单可以理解为用来表征向量空间中的距离,而距离的定义很抽象,只要满足非负、自反、三角不等式就可以称之为距离。
LP范数不是一个范数,而是一组范数,其定义如下:
$\left \| x \right \|_{p}=(\sum_{i}^{n}x_{i}^{p})^{\frac{1}{p}}$
$\left \| x \right \|_{p}=(\sum_{i}^{n}x_{i}^{p})^{\frac{1}{p}}$
$p$的范围是[1,∞)[1,∞)。$p$在(0,1)(0,1)范围内定义的并不是范数,因为违反了三角不等式。
根据$p$的变化,范数也有着不同的变化,借用一个经典的有关P范数的变化图如下:

上图表示了$p$从0到正无穷变化时,单位球(unit ball)的变化情况。在P范数下定义的单位球都是凸集,但是当0< 版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。