IP
角色
操作系统
版本
172.16.10.21
Proxysql
Redhat6.7
1.4.9
172.16.10.32
Master
Redhat6.7
5.7.20
172.16.10.34
Slave1
Redhat6.7
5.7.20
172.16.10.36
Salve2
Redhat6.7
5.7.20
172.16.10.30
VIP
</td>
<td valign="top" width="167">
</td>
</tr>
从库开启read_only=1,主库read_only=0
ProxySQL安装源码包:
yum -y install perl-DBD-MYSQL perl-DBI perl-Time-Hires perl-IO-Socket-ssl
或者简单粗暴的 :yum -y install perl*
proxySQL软件包下载地址:
https://www.percona.com/downloads/proxysql/
安装proxysql
rpm -ivh proxysql-1.4.9-1.1.el6.x86_64.rpm
配置文件路径为:/etc/proxysql.cnf
启动proxysql
service proxysql start

netstat -anlp |grep proxysql

6032是管理端口,6033是对外服务的端口号
用户名和密码默认都是admin
使用帮助如下:

查看proxysql 安装库情况:
mysql -uadmin -padmin -h127.0.0.1 -P6032
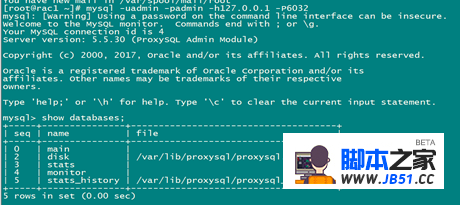
2.2. Proxysql库说明
Proxysql 版本1.4.9-percona-1.1实例:
Main:内存配置数据库,即memory,表里存放后端db实例,用户验证,路由规则等信息。Main库中有如下信息:
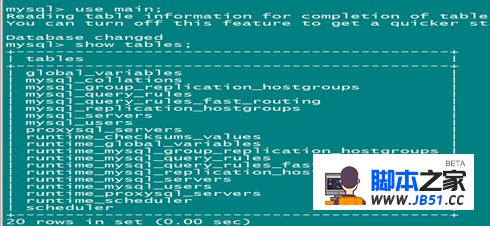
mysql_servers --后端可以连接mysql服务器的列表
mysql_users --配置后端数据库的账号和监控的账号
mysql_query_rules --指定query路由到后端不同服务器的规则列表
disk库:持续化磁盘的配置。
Stats库:统计信息的汇总。
Monitor库:一些监控的收集信息,包括数据库的健康状态。
2.3. 配置proxysql监控
顶层为runtime,中间层为memory,底层也就是持久层disk和config file。
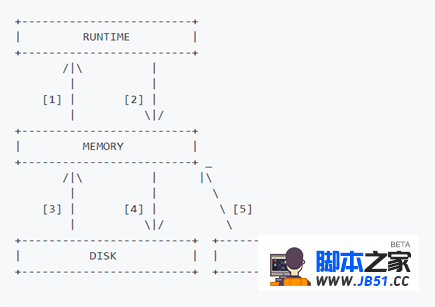
Runtime:代表Proxysql当前生效的正在使用的配置,无法直接修改这里的配置,必须要从下一层load进来。
Memory:memory层上面连接runtime层,下面连接持久化层。在这层可以正常操作Proxysql配置,随便修改,不会影响生产环境。修改一个配置一般都是现在memory层完成,确认正常后在加载到runtime和持久化到磁盘。
Disk和config file:持久化配置信息,重启后内存的配置信息会丢失,所以需要将配置信息保留在磁盘中。重启时,可以从磁盘快速加载回来。
1为写组,2为读组。
insert into mysql_servers(hostgroup_id,hostname,port) values(10,'172.16.10.32',3307);
insert into mysql_servers(hostgroup_id,'172.16.10.34','172.16.10.36',3307);
select * from mysql_servers;

配置监控账户:
create user 'mon'@'172.16.10.%' IDENTIFIED BY 'mon';
GRANT all privileges ON *.* TO 'mon'@'172.16.10.%' with grant option;
对外访问账户:
create user 'wr'@'172.16.10.%' IDENTIFIED BY 'wr';
GRANT all privileges ON *.* TO ON *.* TO 'wr'@'172.16.10.%' with grant option;
配置Proxysql监控:
set mysql-monitor_username='mon';
set mysql-monitor_password='mon';
load mysql servers to runtime;
save mysql servers to disk;

之后验证监控信息:
select * from monitor.mysql_server_connect_log limit 6;
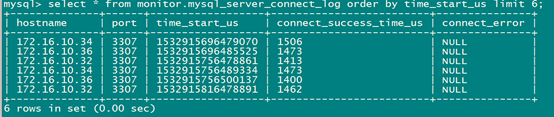
select * from monitor.mysql_server_ping_log order by time_start_us limit 6;

监控信息提示正常。
2.4. 配置Proxysql主从分区信息
配置主从分区需要用到mysql_replication_hostgroups
show create table mysql_replication_hostgroups\G;

writer_hostgroup 写入组的编号
reader_hostgroup 读取组的编号
实验使用10作为写入组,20作为读取组。
insert into mysql_replication_hostgroups values(10,20,'proxy');
load mysql servers to runtime;
save mysql servers to disk;
select * from mysql_replication_hostgroups;
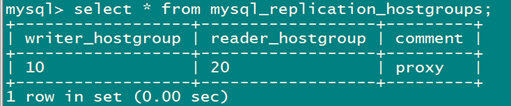
Proxysql 会根据server的read_only的取值将服务进行分组,read_only=0的server,master被分到编号为10的组,read_only=1的server,slave则被分到编号为20的读组。
select * from mysql_servers;

Mysql_users表中的 transaction_persistent字段默认为0,建议在创建完用户之后设置为1,避免发生脏读幻读等现象:
insert into mysql_users(username,password,default_hostgroup) values('wr','wr',10);
update mysql_users set transaction_persistent=1 where username='wr';
load mysql users to runtime;
save mysql users to disk;
测试登陆(端口6033):
mysql -uwr -pwr -h 172.16.10.34 -P3307 -e "show slave status\G"

2.5. 配置读写分离策略
配置读写分离使用的表mysql_query_rules:
match_pattern:字段就是代表设置的规则。
destination_hostgroup:字段代表默认指定的分组。
apply代表真正执行应用规则。
insert into mysql_query_rules(active,match_pattern,destination_hostgroup,apply) values(1,'^SELECT.*FOR UPDATE$',10,1);
insert into mysql_query_rules(active,'^SELECT',1);
LOAD MYSQL QUERY RULES TO RUNTIME;
SAVE MYSQL QUERY RULES TO DISK;
2.6. 测试读写分离
通过wr所创建的账户连接Proxysql登陆数据库。
mysql -uwr -pwr -h172.16.10.21 -P6033

通过管理端口登陆查看:
mysql -uadmin -padmin -h127.0.0.1 -P6032
select * from stats_mysql_query_digest;
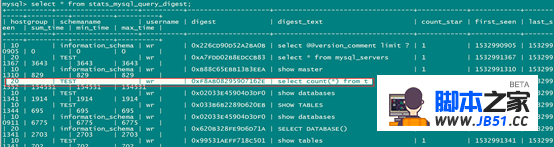
可以得知,select count(*) from t; 这条语句自动编号到20的读组上,即slave上。
测试update。


测试update语句在10的写组上。
2.7. 读写分离权重调整
读写分离设置成功后,可以调节权重,如slave2(172.16.10.36)多进行读操作。
update mysql_servers set weight=10 where hostname='172.16.10.36';
load mysql servers to runtime;
load mysql variables to runtime;
load mysql users to runtime;
save mysql servers to disk;
save mysql variables to disk;
save mysql users to disk;

select * from mysql_servers;

2.8. MHA failover测试
测试前:
Master 172.16.10.32为master,组数为10,写组。
Failover后:

新的master为172.16.10.34(原slave1)
select * from runtime_mysql_servers;
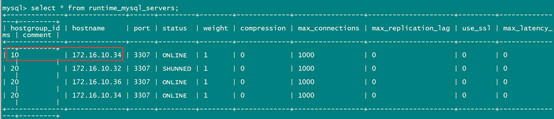
新的master为写组(10),原为20读组。
进行读写分离测试:
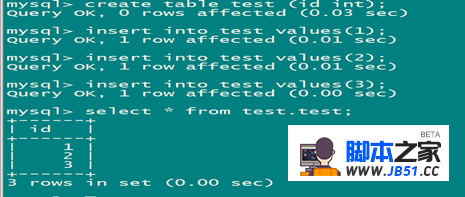
发现读写分离仍然成功(回切后也成功)。

版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。
相关推荐
在正式开始之前,我们先来看下 MySQL 服务器的配置和版本号信息,如下图所示: “兵马未动粮草先行”,看完了相关的配置之后,我们先来创建一张测试表和一些测试数据。 -- 如果存在 person 表先删除 DROP TABLE IF EXISTS person; -- 创建 person 表,其中
> [合辑地址:MySQL全面瓦解](https://www.cnblogs.com/wzh2010/category/1859594.html "合辑地址:MySQL全面瓦解") # 1 为什么需要数据库备份 - 灾难恢复:当发生数据灾难的时候,需要对损坏的数据进行恢复和
物理服务机的CPU、内存、存储设备、连接数等资源有限,某个时段大量连接同时执行操作,会导致数据库在处理上遇到性能瓶颈。为了解决这个问题,行业先驱门充分发扬了分而治之的思想,对大库表进行分割,
然后实施更好的控制和管理,同时使用多台机器的CPU、内存、存储,提供更好的性能。而分治有两种实现方式:垂直拆
1 回顾 上一节我们详细讲解了如何对数据库进行分区操作,包括了 垂直拆分(Scale Up 纵向扩展)和 水平拆分(Scale Out 横向扩展) ,同时简要整理了水平分区的几种策略,现在来回顾一下。 2 水平分区的5种策略 2.1 Hash(哈希) 这种策略是通过对表的一个或多个列的Ha
navicat查看某个表的所有字段的详细信息 navicat设计表只能一次查看一个字段的备注信息,那怎么才能做到一次性查询表的信息呢?SELECT COLUMN_NAME,COLUMN_COMMENT,COLUMN_TYPE,COLUMN_KEY FROM information_schema.CO
文章浏览阅读4.3k次。转载请把头部出处链接和尾部二维码一起转载,本文出自逆流的鱼yuiop:http://blog.csdn.net/hejjunlin/article/details/52768613前言:数据库每天的数据不断增多,自动删除机制总体风险太大,想保留更多历史性的数据供查询,于是从小的hbase换到大的hbase上,势在必行。今天记录下这次数据仓库迁移。看下Agenda:彻底卸载MySQL安装MySQL_linux服务器进行数据迁移
文章浏览阅读488次。恢复步骤概要备份frm、ibd文件如果mysql版本发生变化,安装回原本的mysql版本创建和原本库名一致新库,字符集都要保持一样通过frm获取到原先的表结构,通过的得到的表结构创建一个和原先结构一样的空表。使用“ALTER TABLE DISCARD TABLESPACE;”命令卸载掉表空间将原先的ibd拷贝到mysql的仓库下添加用户权限 “chown . .ibd”,如果是操作和mysql的使用权限一致可以跳过通过“ALTER TABLE IMPORT TABLESPACE;”命令恢_alter table discard tablespace
文章浏览阅读225次。当MySQL单表记录数过大时,增删改查性能都会急剧下降,可以参考以下步骤来优化:单表优化除非单表数据未来会一直不断上涨,否则不要一开始就考虑拆分,拆分会带来逻辑、部署、运维的各种复杂度,一般以整型值为主的表在千万级以下,字符串为主的表在五百万以下是没有太大问题的。而事实上很多时候MySQL单表的性能依然有不少优化空间,甚至能正常支撑千万级以上的数据量:字段尽量使用TINYINT、SMALLINT、MEDIUM_INT作为整数类型而非INT,如果非负则加上UNSIGNEDVARCHAR的长度只分配_开发项目 浏览记录表 过大怎么办
文章浏览阅读1.5k次。Mysql创建、删除用户MySql中添加用户,新建数据库,用户授权,删除用户,修改密码(注意每行后边都跟个;表示一个命令语句结束):1.新建用户登录MYSQL:@>mysql -u root -p@>密码创建用户:mysql> insert into mysql.user(Host,User,Password) values("localhost_删除mysql用户组
MySQL是一种开源的关系型数据库管理系统,被广泛应用于各类应用程序的开发中。对于MySQL中的字段,我们需要进行数据类型以及默认值的设置,这对于数据的存储和使用至关重要。其中,有一个非常重要的概念就是MySQL字段默认字符串。 CREATE TABLE `my_...
MySQL是一个流行的开源关系型数据库管理系统,广泛应用于Web应用程序开发、数据存储和管理。在使用MySQL时,正确设置字符集非常重要,以确保数据的正确性和可靠性。 在MySQL中,字符集表示为一系列字符和字母的集合。MySQL支持多种字符集,包括ASCII、UTF...
MySQL存储函数 n以内偶数 MySQL存储函数能够帮助用户简化操作,提高效率,常常被用于计算和处理数据。下面我们就来了解一下如何使用MySQL存储函数计算n以内的偶数。 定义存储函数 首先,我们需要定义一个MySQL存储函数,以计算n以内的偶数。下...
MySQL是一个流行的关系型数据库管理系统,基于客户机-服务器模式,可在各种操作系统上运行。 MySQL支持多种字符集,不同的字符集包括不同的字符,如字母、数字、符号等,并提供不同的排序规则,以满足不同语言环境的需求。 //查看MySQL支持的字符集与校对规...
在MySQL数据库中,我们有时需要对特定的字符串进行截取并进行分组统计。这种操作对于数据分析和报表制作有着重要的应用。下面我们将讲解一些基本的字符串截取和分组统计的方法。 首先,我们可以使用substring函数对字段中的字符串进行截取。假设我们有一张表stude...
MySQL提供了多种字符串的查找函数。下面我们就一一介绍。 1. LIKE函数 SELECT * FROM mytable WHERE mycolumn LIKE 'apple%'; 其中"apple%"表示以apple开头的字符串,%表示任意多个字符...
MySQL 是一种关系型数据库管理系统,广泛应用于各种不同规模和类型的应用程序中。在 MySQL 中,处理字符串数据是很常见的任务。有时候,我们需要在字符串的开头添加一定数量的 0 ,以达到一定的位数。比如,我们可能需要将一个数字转换为 4 位或 5 位的字符串,不足的...
MySQL是一种流行的关系型数据库管理系统,支持多种数据类型。以下是MySQL所支持的数据类型: 1. 数值型数据类型: - TINYINT 保存-128到127范围内的整数 - SMALLINT 保存-32768到32767范围内的整数 - MEDIU...
MySQL中存储Emoji表情字段类型 在现代互联网生态中,表情符号已经成为人们展示情感和思想的重要方式之一,因此将表情符号存储到数据库中是一个经常出现的问题。MySQL作为最流行的开源关系型数据库管理系统之一,也需要能够存储和管理这些表情符号的字段类型。 UT...
MySQL是一种关系型数据库管理系统。在MySQL数据库中,有多种不同的数据类型。而其中,最常见的数据类型之一就是字符串类型。在MySQL中,字符串类型的数据通常会被存储为TEXT或VARCHAR类型。 首先,让我们来看一下VARCHAR类型。VARCHAR是My...
MySQL字符串取整知识详解 MySQL是一种开源的关系型数据库管理系统,广泛应用于各个领域。在使用MySQL过程当中,我们经常需要对数据进行取整操作。本文将介绍如何使用MySQL字符串取整来处理数据取整问题。 什么是MySQL字符串取整? MySQL...

