
《简单MySQL教程三》要点:
本文介绍了简单MySQL教程三,希望对您有用。如果有疑问,可以联系我们。
一、性能阐发
1、MySql Query Optimizer
1 )、Mysql中有专门负责优化SELECT语句的优化器模块,主要功能:通过计算分析系统中收集到的统计信息,为客户端哀求的Query提供他认为最优的执行计划(它认为最优的数据检索方式,但不见得是DBA认为是最优的,这部分最耗费时间)
2) 当客户端向MySQL 哀求一条Query,命令解析器模块完成哀求分类,区别出是 SELECT 并转发给MySQL Query Optimizer时,MySQL Query Optimizer 首先会对整条Query进行优化,处理掉一些常量表达式的预算,直接换算成常量值.并对 Query 中的查询条件进行简化和转换,如去掉一些无用或显而易见的条件、结构调整等.然后分析 Query 中的 Hint 信息(如果有),看显示Hint信息是否可以完全确定该Query 的执行计划.如果没有 Hint 或Hint 信息还不足以完全确定执行计划,则会读取所涉及对象的统计信息,根据 Query 进行写相应的计算分析,然后再得出最后的执行计划.
2、MySQL常见瓶颈
CPU:CPU在饱和的时候一般产生在数据装入内存或从磁盘上读取数据时候
IO:磁盘I/O瓶颈产生在装入数据远大于内存容量的时候
二、explain症结字
1、explain是什么
使用EXPLAIN关键字可以模拟优化器执行SQL语句,从而知道MySQL是如何处理你的SQL语句.分析你的查询语句或是表布局的性能瓶颈.
2、explain做什么
可以查看以下内容:
表的读取次序
数据读取操作的操作类型
哪些索引可以被使用
哪些索引被现实使用
表之间的引用
每张表有若干行被优化器查询
3、explain怎样用
执行Explain + sql语句可以查看一下内容

4、各字段解释
id
select查询的序列号,包括一组数字,表示查询中执行select子句或操作表的顺序,数字相同的从上到下依次执行,不同的数字大的优先执行.
select_type
查询的类型,主要用于区别普通查询,联合查询,子查询等繁杂查询.主要有以下6种
SIMPLE:简单的 select 查询,查询中不包括子查询或者UNION
PRIMARY:查询中若包括任何复杂的子部分,最外层查询则被标记为
SUBQUERY:在SELECT或WHERE列表中包括了子查询
DERIVED:在FROM列表中包括的子查询被标记为DERIVED(衍生)MySQL会递归执行这些子查询,把结果放在临时表里.
UNION:若第二个SELECT出现在UNION之后,则被标记为UNION;若UNION包括在FROM子句的子查询中,外层SELECT将被标记为:DERIVED
UNION RESULT:从UNION表获取成果的SELECT
table
显示这一行数据来自哪一张表
type
表示拜访类型,从最好到最坏依次为system const eq_ref ref fulltext ref_or_null index_merge unique_subquery index_subquery range index ALL
一般来说至少要到达range级别.

possible_keys
显示可能应用在这张表中的索引,一个或多个.查询涉及到的字段上若存在索引,则该索引将被列出,但不必定被查询实际使用
key
实际使用的索引.如果为NULL,则没有使用索引.查询中若使用了笼罩索引,则该索引和查询的select字段重叠
key_len
表现索引中使用的字节数,可通过该列计算查询中使用的索引的长度.在不损失精确性的情况下,长度越短越好
key_len显示的值为索引字段的最年夜可能长度,并非实际使用长度,即key_len是根据表定义计算而得,不是通过表内检索出的
ref
显示索引的哪一列被使用了,假如可能的话,是一个常数.哪些列或常量被用于查找索引列上的值
rows
根据表统计信息及索引选用情况,大致估算出找到所需的记录所必要读取的行数
Extra
包括以下内容:

5、举例阐发
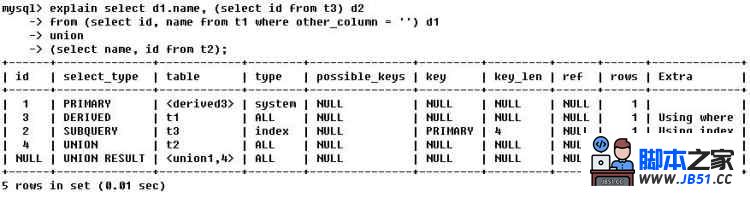
第一行(执行顺序4):id列为1,表示是union里的第一个select,select_type列的primary表 示该查询为外层查询,table列被标志为derived3,表示查询结果来自一个衍生表,其中derived3中3代表该查询衍生自第三个select查询,即id为3的select.【select d1.name......】
第二行(执行顺序2):id为3,是整个查询中第三个select的一部分.因查询包括在from中,所以为derived.【select id,name from t1 where other_column=''】
第三行(执行次序3):select列表中的子查询select_type为subquery,为整个查询中的第二个select.【select id from t3】
第四行(执行顺序1):select_type为union,阐明第四个select是union里的第二个select,最先执行【select name,id from t2】
第五行(执行顺序5):代表从union的临时表中读取行的阶段,table列的union1,4表现用第一个和第四个select的结果进行union操作.【两个结果union操作】
教程四会出怎样样优化索引和避免索引失效
《简单MySQL教程三》是否对您有启发,欢迎查看更多与《简单MySQL教程三》相关教程,学精学透。编程之家PHP学院为您提供精彩教程。
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。