
1. 作用
- 对数据备份,实现高可用 HA
- 通过读写分离,提高吞吐量,实现高性能
2. 原理

- Mysql的复制 是一个异步的复制过程
- 过程本质为 Slave 从 Master 端获取 Binary Log,然后再在自己身上完全顺序的执行日志中所记录的各种操作
- MySQL 复制的基本过程如下:
- Slave 上面的 IO 线程连接上 Master, 并请求从指定日志文件的指定位置之后的日志内容;
- Master 接收到来自 Slave 的 IO 线程的请求后, 通过负责复制的IO线程 根据请求信息读取日志信息,返回给 Slave 端的 IO 线程。
- Slave 的 IO 线程接收到信息后,将接收到的日志内容依次写入到 Slave 端的 Relay Log文件
- Slave 的 SQL 线程检测到 Relay Log 中新增加了内容后,会马上解析该文件中的内容,并在自身执行这些 原始SQL语句。
3. 常用架构
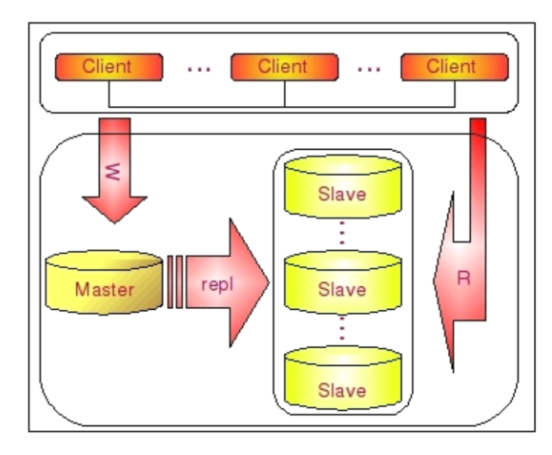
主从架构
- 性能
- 一主多从,读写分离,提高吞吐量
- 可用性
- 主库单点,一旦挂了,无法写入
- 从库高可用
主备架构
- 性能
- 单库读写,性能一般
- 可用性
- 高可用,一旦主库挂了,就启用备库
- 这种方案被阿里云、美团等企业广泛使用
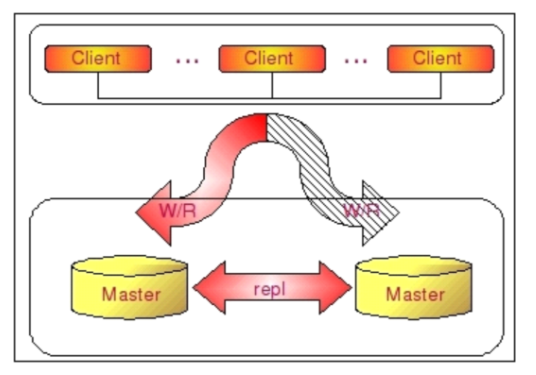
问题: 既然主备互为备份,为什么不采用双主方案,提供两台主进行负载均衡?
主备架构搭建除了配置双主同步,还需要搭配第三方故障转移/高可用方案,属于DBA和运维专业领域,这里不展开讲解,在后续的线上课程 python运维开发-03章LVS/04章Keepalived 中有具体讲解,
也可参考博客: MySQL + Keepalived 双主热备高可用操作记录 进行搭建
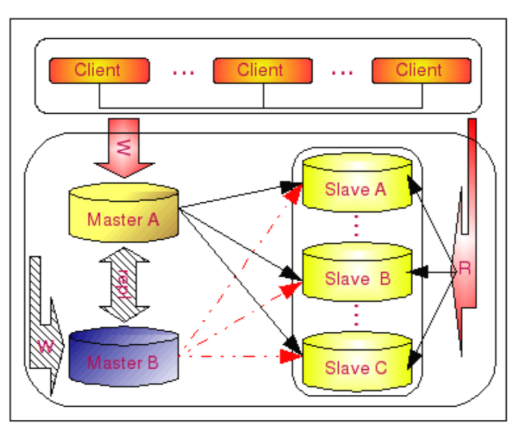
高可用复合架构
- 性能
- 读写分离,提高吞吐量
- 可用性
- 高可用,就启用备库
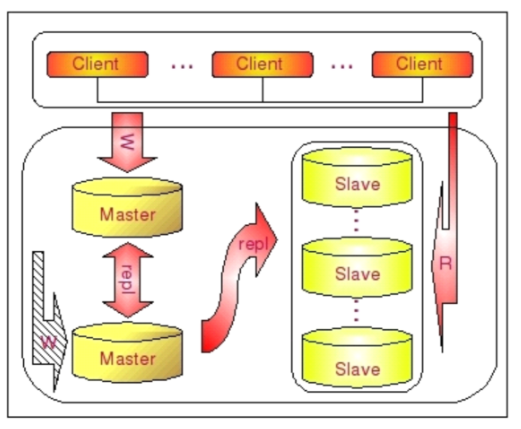
A库宕机的情况:
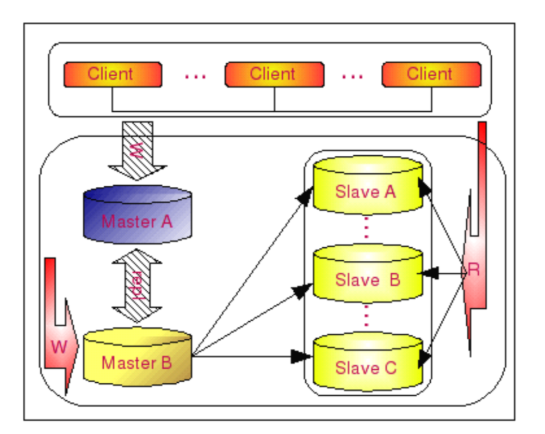
B库宕机的情况:
原文地址:https://www.cnblogs.com/tracydzf
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。