
本节重点有两个:
1. Pod
2. 网络通讯
一. Pod
1.1 Pod的类型
1. 自主式Pod
自主式Pod是不被控制器管理的Pod. 这种Pod死亡以后,不会被重新启动. 这个Pod死了以后,副本数就达不到期望值了,也不会有人去创建一个新的Pod为达到副本数的期望值.
在传统情况下,我们运行一个容器,每一个容器都是独立存在的,每个容器都有自己的ip地址,每个容器都有自己的挂载卷. 但在k8s移植的时候,就不太容易了. 我们把一个没有在容器里运行的环境转移到或迁移到k8s的环境里,就比较难迁移.比如:LAMP,那么A和php之间有联系,我们把A和php分开了,他俩个是不同的地址,还要去配置反向代理,比较费劲.
说的是什么意思呢? 有些组件应该在一起,并且能互相见面,也就是通过localhost能访问到. 但是,使用标准的容器,你没办法这样做,除非你把两个进程封装在一个容器内部. K8S给我们建立了一个Pod,Pod是怎样实现的呢?
首先,要定义一个Pod,他会先启动第一个容器,这个容器需要注意,只要运行的Pod,这个容器就会被启动. 这个容器叫pause
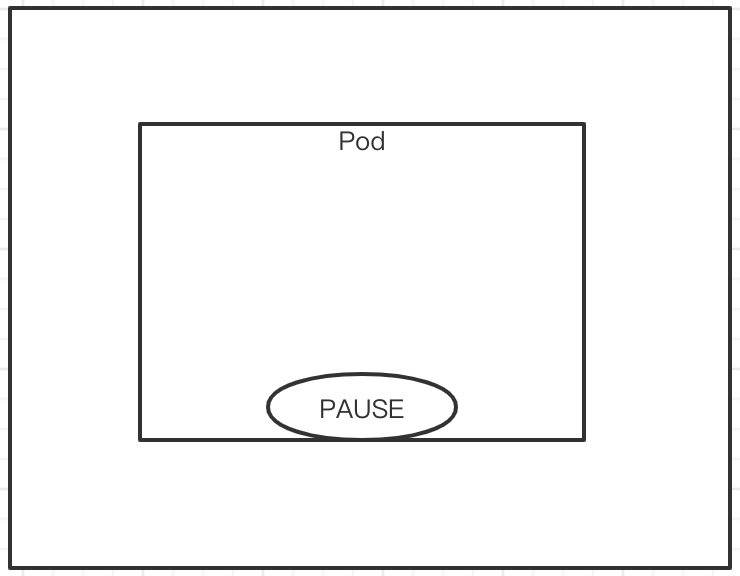
然后,在Pod里定义了两个容器,也可以是一个容器,然后这两个Pod会共用PAUSE的网络栈和存储卷.

也就是说,这两个容器没有自己独立的ip地址和存储卷,或者说,他们有的是PAUSE或者pod的ip地址. 这两个容器他们尾根隔离,但是进程不隔离. 也就是说,如果容器1运行的是php,容器2运行的是nginx,nginx想要反向代理访问php,只需要要写localhost:9000即可. 不需要写IP地址+端口映射. 原因是这两个容器共享的是PAUSE的网络栈.
这样就说明了,在同一个Pod里,容器之间的端口不能冲突.
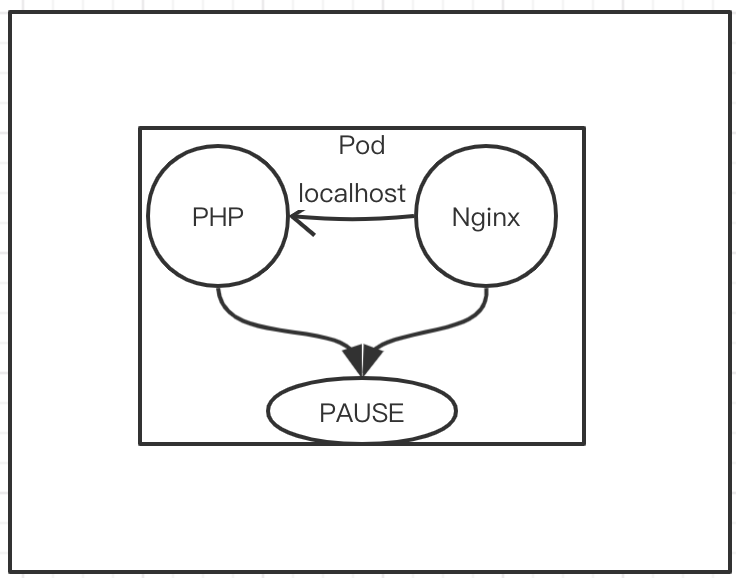
下面一个要说明的是: 共享存储. 这里两个容器除了共享网络,同时也共享存储卷.

2. 控制器管理的Pod
说控制器管理的Pod,先来看看控制器有哪些:
-
ReplicationController & ReplicaSet & Deployment : 这三种控制器为什么放在一块呢? 因为他们有很多相似的地方
- ReplicationController: 简称rc. 原来确保容器英语的副本数始终保持在用户定义的副本数,即如果有容器异常退出,会自动创建新的Pod来代替;而如果异常多出来的容器也会自动回收. 在新版本的k8s中,建议使用ReplicaSet来取代ReplicationController.
-
- ReplicaSet: 简称rs. 跟ReplicationController没有本质上的区别,只是名字不同,并且ReplicaSet支持集合式的selector.
我们在创建Pod的时候,可以给他打标签. 比如: app = http,version = v1版本等等. 我们会打一堆的标签. 当我们想删除容器的时候,我们可以这样说: 当app=http,version = v1的时候,执行什么操作. rs支持这种集合方案,但是rc不支持. 所以在大型项目中,rs比rc会更简单,更有效率. 所以,在新版本中,官方抛弃rc,全部转用rs.
-
- Deployment: 虽然replicaSet可以独立使用,但一般还是建议使用Deployment来自动管理ReplicaSet,这样就无需担心跟其他机制的不兼容问题(比如ReplicaSet不支持 rolling-update滚动更新,但Deployment支持)
滚动更新还是很有意义的,尤其是在生成环境中
比如我们现在有两个容器,我们要将现在容器的版本从v1版本升级到v2版本. 这时候,怎么办呢? 我们可以进行一个滚动更新.
首先,先生成一个新的pod.然删除一个旧的pod,如下如所示. 先生成一个v2版本的pod,然后删除一个v1版本的pod . 然后在创建一个新的v2版本,再把老的v1版本删除.
最后就会出现一个最新版本的状态了.这就是滚动更新.

那么,Deployment是如何管理rs并滚动更新的呢?
Deployment定义出来以后,他会定义一个rs,也就是说rs不是我们自己定义的,是Deployment自动生成的. RS会创建多个pod. 如下图

当需要更新版本的时候.
首先. Deployment会先创建出一个RS
`
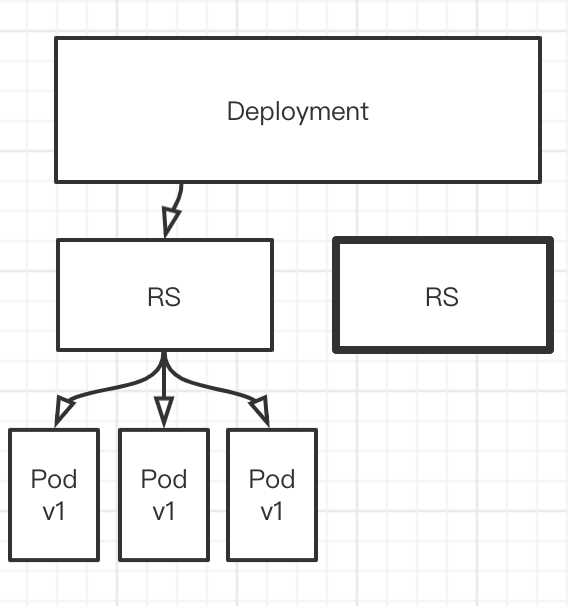
然后在创建一个新的 Pod,将其升级到v2版本. 然后下掉一个v1版本的Pod
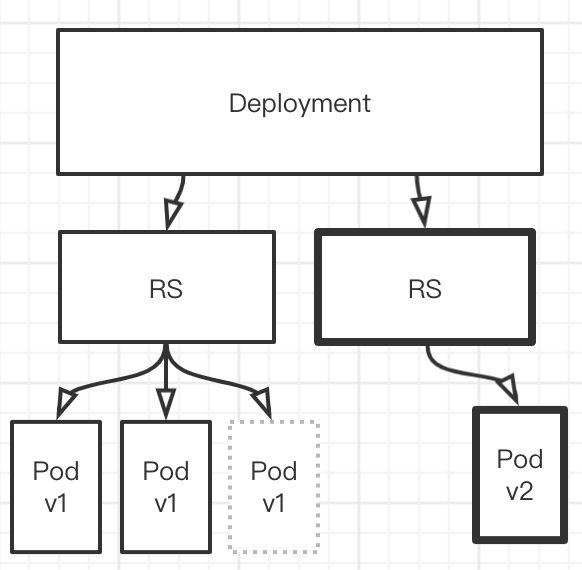
然后在创建一个Pod,将其版本升级到v2,在下掉一个v1版本的Pod
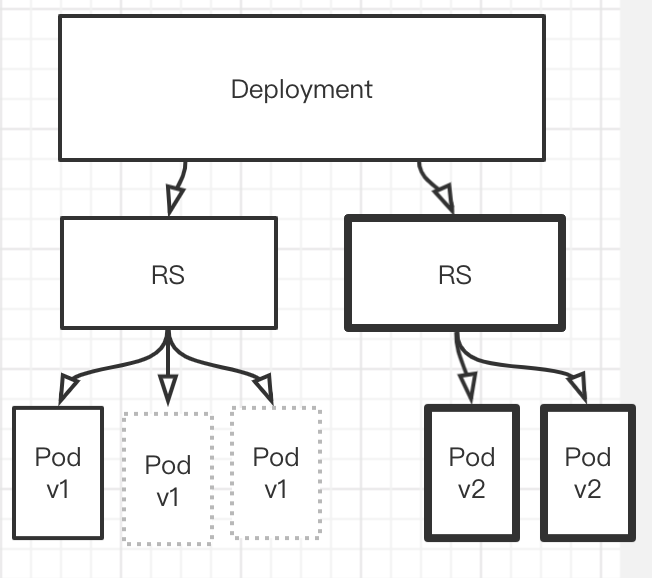
直至全部下完.
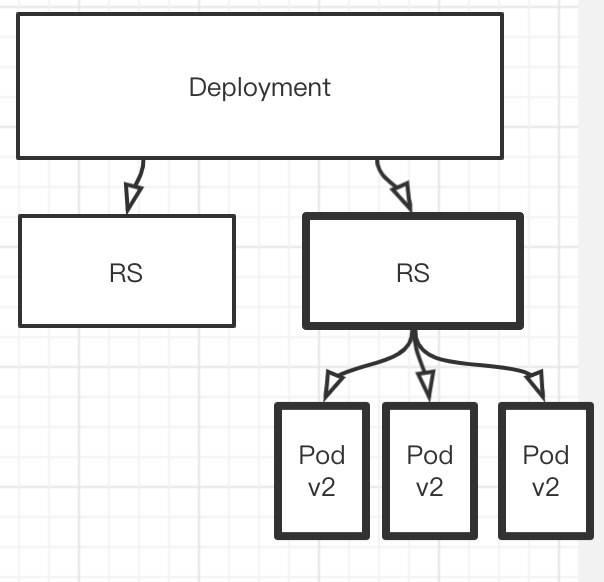
这就是Deployment`管理的滚动rolling-update滚动升级
如果升级的过程中,发现新版本有一些小bug,我们还可以回滚. 如何回滚,执行undo即可. 回滚的逻辑和版本升级的原理一样. 恢复一个v1,下掉一个v2. 直至全部恢复.
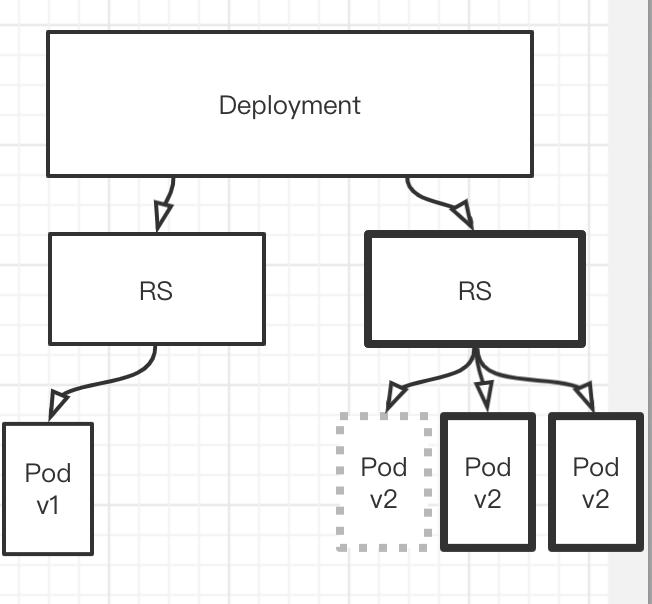
为什么RS能够恢复呢? 因为,下掉的RS没有被删掉. 只是停用了. 当回滚的时候,老旧的RS就会被启动.
-
HPA(HorizontalPodAutoScale) : Horizontal Pod AutoScaling 仅适用于Deployment和ReplicaSet,在V1版本中仅支持根据Pod的CPU利用率扩缩容,在vlalpha版本中,支持根据内存和用户自定义的metric扩缩容.
我运行了一个RS,RS下管理两个Pod,
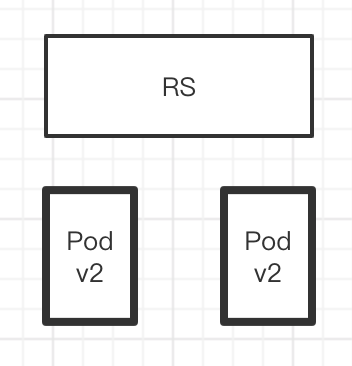
然后,在定义一个HPA,HPA也是一个对象,他是基于RS创建的,那HPA怎么定义的呢? 当CPU>80%的时候,开始扩容,扩容的最大值是10个,最小值是2个
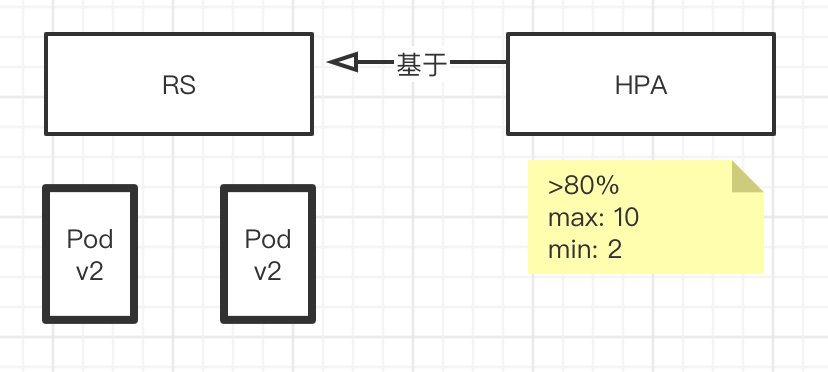
也就是说HPA会去监控RS下Pod的资源利用率. 如果资源利用率>80%,那么开始扩展Pod,然后判断是否依然超过80%,如果是 继续扩展. 直到扩展到资源利用率低于80%,或者最大数达到10个.

一旦资源利用率变低以后,开始缩容. 他会先减掉一个pod. 看看是否达到80%,还没达到继续减. 但最少的pod数是两个. 也即是减到只剩2个pod,不能再减了.
这样就达到了一个水平扩展的目的. 这也是HPA帮我们实现的.
-
statefulSet: 主要解决的是有状态服务的问题.
服务的分类: 1. 无状态服务: 踢出去过段时间放回来,依然能正常工作. 比如LVS调度器,APACHE(http服务) 为什么apache是无状态服务呢? 因为apache中的数据可以通过共享服务来完成. 对于组件本身他不需要数据,也没有数据的更新. 所以,apache被定义到无状态服务里面. docker: 对于docker来说,他更适合运行的是无状态服务.
2. 有状态服务: 踢出集群后过段时间再放回来,不能正常工作了,这样的服务就是有状态服务. 比如: 数据库DBMS,因为有很大一部分数据缺失了. Kubernetes的一个难点就是必须要攻克有状态服务. 那么,有状态服务,有些数据需要持久化,需要保存起来,这时,我们就会引入存储的概念.
主要解决的是有状态服务的问题. docker主要面对的是无状态服务,无状态服务的含义时,没有对应的存储需要实时的保留. 或者是把他摘出来,经过一段时间以后,放回去依然能够工作. 典型的无状态服务有哪些呢? 比如: apache服务,LVS服务(负载均衡调度器) . 典型的有状态服务有哪些呢?mysql,mongodb,他们需要实时的对数据进行更新和存储. 把他抽离出集群,再放回来就没办法工作了. statefulSet就是为了解决有状态服务而诞生的.
对应的Deployment 和 ReplicaSet是无状态服务
应用场景包括:
-
稳定的持久化存储. 即Pod重新调度后还是能访问到相同的持久化数据. 基于PVC来实现.
- 就是说Pod死亡以后,我们在调度会来,创建一个Pod取代他的时候,他的存储依然是之前的存储,并不会变,并且里面的数据也不会丢失.
- 稳定的网络标识: 即Pod重新调度后其PodName和HostName是不变的(之前叫什么,现在还叫什么). 基于Headless Service(即没有Cluster IP 的Service)来实现
-
有序部署. 有序扩展. 即Pod是有顺序的,再部署或扩展的时候,要依据定义的顺序一次进行(即从0到n-1,在下一个pod运行之前,所有之前的Pod必须都是Running和Ready的标志),基于init Containars实现
- 有序部署会分为扩展和回收阶段. 只有当前一个Pod处于running和ready的状态,第二个才可以被创建. 为什么需要这样部署呢? 原因是,我们构建一个集群化,比如及群里有nginx,apache,mysql. 我们的启动顺序是先启mysql,再启apache,再启nginx,因为他们之间是有依赖关系的. nginx依赖apache,apache依赖mysql. 这就是有序部署. 回收也是一样的是有序的,不同的是,他是逆序回收. 从n-1开始,一直到0.
- 有序收缩, 有序删除(即从n-1到0)
-
DaemonSet: 确保全部(或一些)Node上运行一个Pod的副本. 当有Pod加入集群时,也会为他们增加一个Pod,当有Pod从集群移除时,Pod也会被回收,删除DeamonSet会删除对应的所有的Pod.
使用DaemonSet的典型用法:
- 运行集群存储daemon,例如在每个Node上运行glusterd,ceph.
- 在每个节点上运行日志收集daemon,例如fluentd,logstash.
- 在每个节点上运行监控daemon, 例如Prometheus,Node Exporter.
-
Job,CronJob
-
Job是负责批处理的任务. 仅执行一次的任务,它保证批处理任务的一个或多个Pod成功结束
- 比如: 我想备份数据库,备份代码可以放在Pod里,我们将其放到定时器里去,到时间就可以把脚本运行,执行出来.
-
CronJob管理基于时间的Pob, 即
- 在给定的时间点只运行一次
- 周期性的再交给时间点运行
-
Job是负责批处理的任务. 仅执行一次的任务,它保证批处理任务的一个或多个Pod成功结束
3. 服务发现

客户端想要访问一组pod,如果这些pod是无相干的话,是不能通过Service代理的. pod需要具有相关性,比如同一个rs / rc deployment创建的,或者拥有同一组标签. 都可以被service收集到. 即: service去搜集Pod是通过标签去选择到的. 这一点很重要. 选择到以后,service会有自己的ip+port,客户端就可以访问service的ip+端口. 客户端就可以访问service的ip + 端口. 间接访问pod. 并且这里有一个RR的算法存在.
假设我们现在有一个简单的集群环境:

有一个myqsl,三台apache-fpm,三台缓存服务器SQUID,有一个负载均衡器LVS. 我们来分析一下,如果把它放到k8s中如何部署.
1. mysql需要运行在一个Pod中,
2. apache-fpm,有三个,其实他们都是类似,所以我们可以把它放到Deployment控制器中创建,Deployment会指定apache-fpm的副本数有3个副本

3. SQUID,缓存服务器也有三个,我们也可以把它放到Deployment控制器中创建.

4. LVS,可以考集群本身的功能,进行负载调度.
现在这种结构,我们发现,如果缓存服务器SQUID想要访问apapche-fpm,写反向代理的话,需要写三台服务器. 并且,我们说过,pod如果退出重新创建以后,pod的ip地址会变换. 除非采用的是statefulSet,但是在apache-fpm中没有意义,因为他是一个无状态服务 . 那怎么办呢? 我么可以在前面 加一个service,这个service就是Service-php-fpm的. 他会绑定我们的标签.
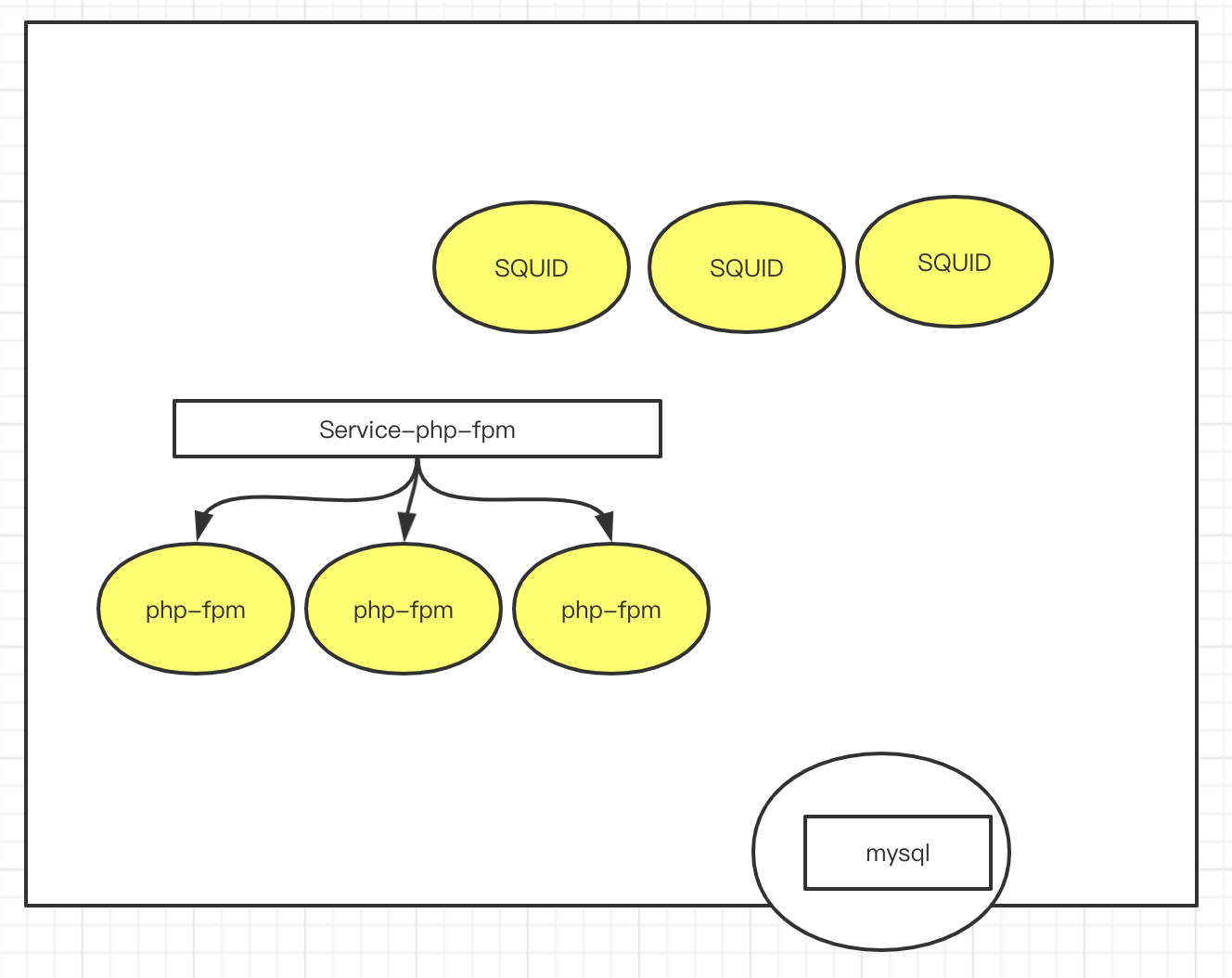
SQUID去进行反向代理设定的时候,不需要写php-fpm的三个ip地址了,而且,pod死亡以后,控制器会把他维持到三个副本,回在自动创建一个, 新创建的ip地址和原来的是不一样的. SQUID如果在里面填写的是目标ip,就有问题. 所以,SQUID里面写的是server-php-fpm的地址. 这样SQUID只要执行到Service-php-fpm上面即可.

mysql也是一个pod,我们要求mysql这个pod如果死了,重启,他的ip地址和主机名是不能变的,因此我们把它放到statefulSet中.
Kubernetes内部是一个扁平化的网络,相互之间可以通过localhost请求访问,所以,关联关系如下:
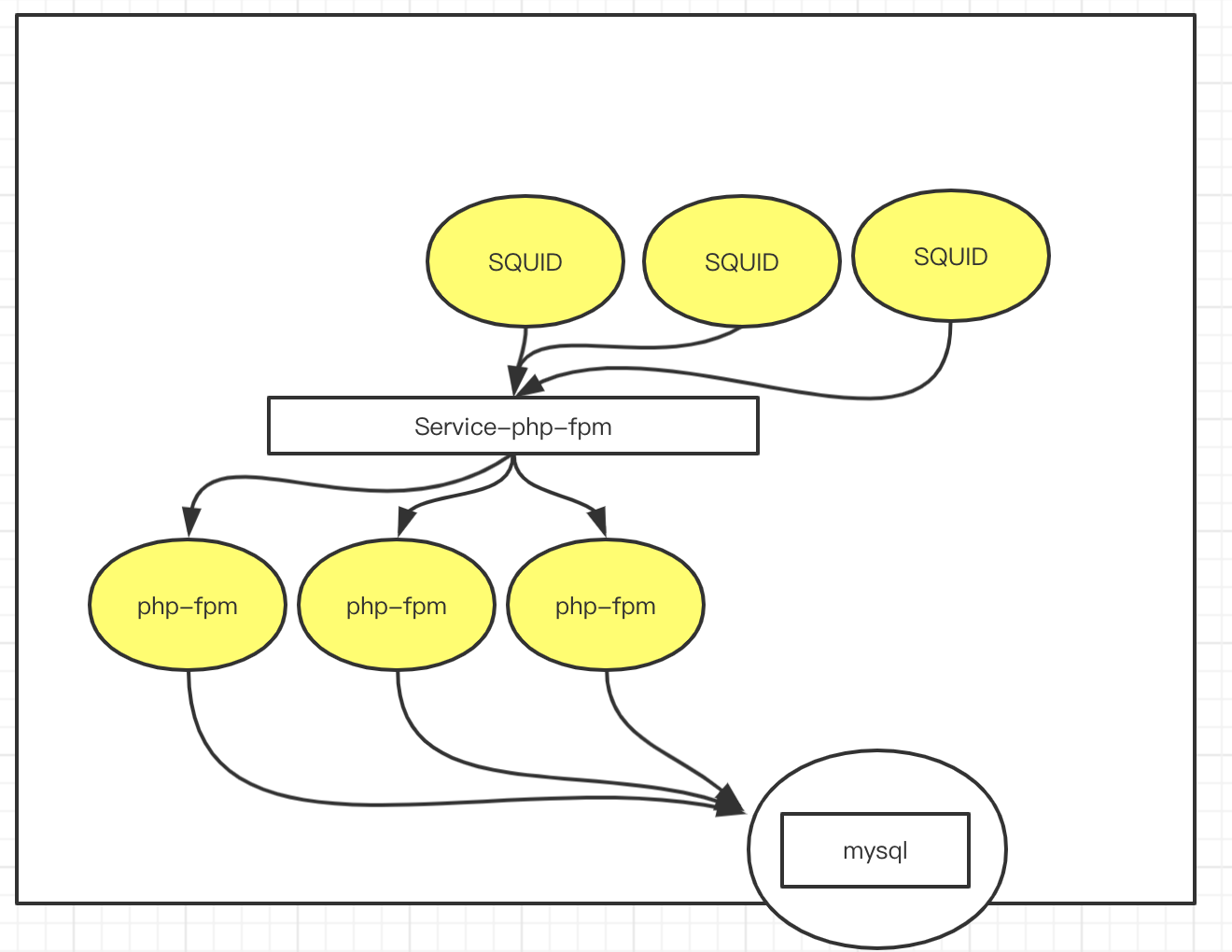
SQUID需要被外网访问,因此,我们在SQUID上也可以创建一个Service-SQUID

这样,我们就可以把这个架构完整的部署在k8s集群中了.
二. 网络通讯
1.
as
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。