
一. k8s的网络模型
k8s的网络模型假定了所有的Pod都在一个可以直接连通的扁平的网络空间中,这在GCE(Google Compute Engine)里面是线程的网络模型,Kubernetes假定这个网络已经存在. 而在私有云里搭建Kubernetes集群,就不能假定这个网络已经存在了. 我们需要自己实现这个网络假设,将不同节点上的Docker容器之间的互相访问先打通,然后运行Kubernetes.
这段话是什么意思呢? 用大白话来翻译一下
k8s默认所有pod都在一个扁平化的网络中,也就是pod之间都是可以通过localhost相互访问的. 比如,我们现在办公都提倡扁平化管理,从工位的体现就是,领导和员工们都坐在一起,你也分不出来谁是领导,谁是员工. 相互之间,随时沟通,随时交流,无障碍.
而现实网络中,我们都是用的阿里云,在阿里云上搭建集群,集群之间就不是扁平化的. 需要设置实现. 所以,运行k8s,第一步,我们要设置网络之间可以相互连通,"直接到达". 这里的"直接到达"加了双引号,Pod认为我是直接到达的,其实底层,有一堆转换机制存在,比如Flannel的转换机制
如果,我们想要在自己的集群中构建k8s,首先要解决扁平化的网络空间,如果现在没有开原方案的话,这一点是比较难做到的. 原因是,我们需要将集群中的每一个Pod容器打通. 好在现在已经有很多公司加入k8s一起研究,比如后面我们将要学习的Flannel,他可以帮我们实现扁平的网络空间
二. 通讯类型
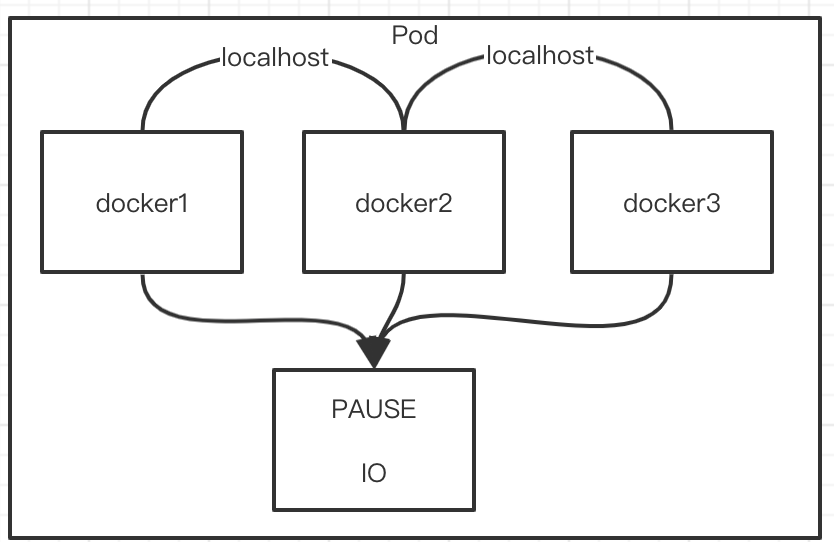
2.1. 同一个Pod内的多个容器之间: 通过IO访问
一个Pod里面有很多容器,容器和容器之间访问,他们走的是谁呢?
只要是同一个Pod,他们在容器内共享PAUSE,因此他们用 PAUSE容器网络栈,他们之间互相访问,走的是网络栈的IO,通过localhost的方式就可以直接访问.
2.2. Pod与Service之间的通讯: 各节点的Iptables规则
pod和service之间的通讯,通过各节点的iptables规则,进行转化. 在最新版本中,已经加入了LVS的机制,为他进行转发,转发效率更高,上限更高
2.3. 各Pod之间的通讯,使用的是Overlay Network
Overlay Network是全覆盖网络. 这是我们要重点研究的对象.
Overlay 网络到底是怎样实现的呢? 以及他们之间经历了哪些转换机制? 下面研究
三. 网络解决方案
1. Kubernetes + Flannel
google对k8s没有很强的定义,它允许我们通过CNI的接口去接入我们想要达到的网络方案. 其中Flannel是最常用的,在k8s里解决网络问题的方案,符合CNI接口. Flannel到底是什么呢?
Flannel是CoreOS团队针对Kubernetes设计的一个网络规划服务,简单来说,他的功能是让集群中的不同节点主机创建的Docker容器都具有全局唯一的虚拟机IP地址,而且他还能在这些IP地址之间建立一个覆盖网络(Overlay Network),通过这个覆盖网络,将数据包原封不动的传递到目标容器内.
划重点: 它的作用是---- 让集群中的不同节点主机创建的Docker容器都具有全局唯一的虚拟机IP地址, 而且他还能在这些IP地址之间建立一个覆盖网络(Overlay Network),将数据包原封不动的传递到目标容器内.
我们现在有三台物理机,每台物理机上安装docker容器. 这些容器相互之间如何访问呢?
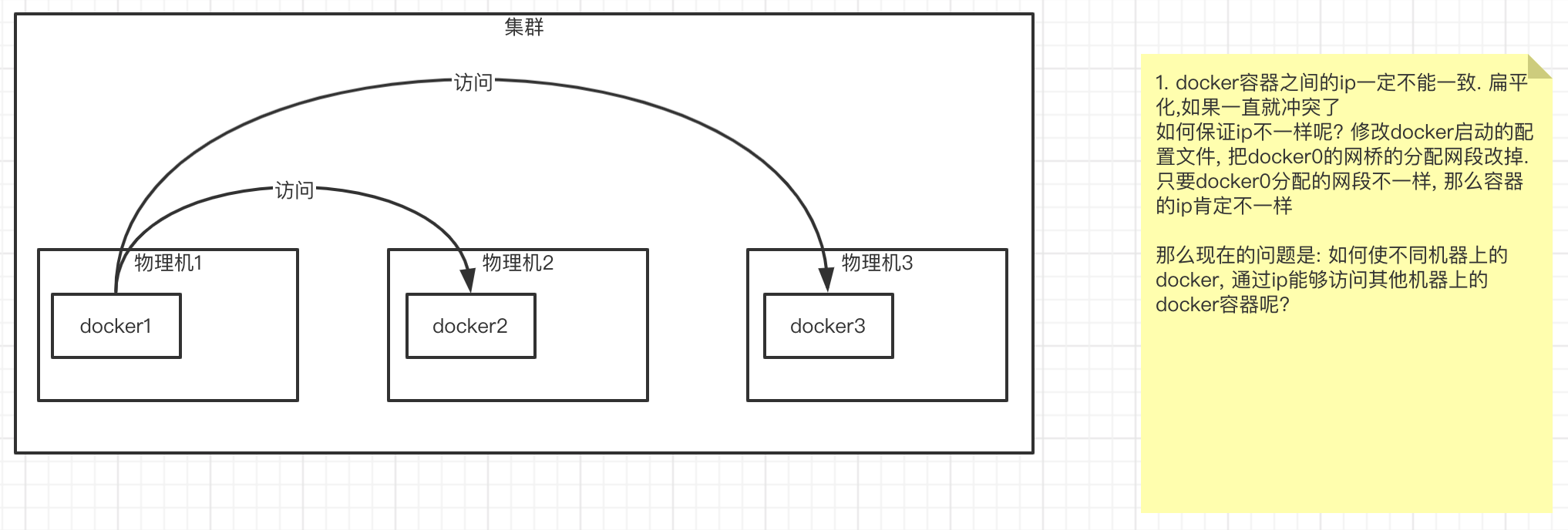
首先. 所有容器之间要扁平化管理,那么他们的ip地址一定不能重复,一旦重复,那就冲突了
如何保证ip地址不一样呢?
修改docker启动的配置文件,把docker0的网桥的分配网段改掉. 只要docker0分配的网段不一样,那么容器的ip肯定不一样
ip的问题解决了, 那么现在的问题是: 如何使不同机器上的docker,通过ip能够访问其他机器上的docker容器呢?
下面,我们看一下Flannel是如何解决的?
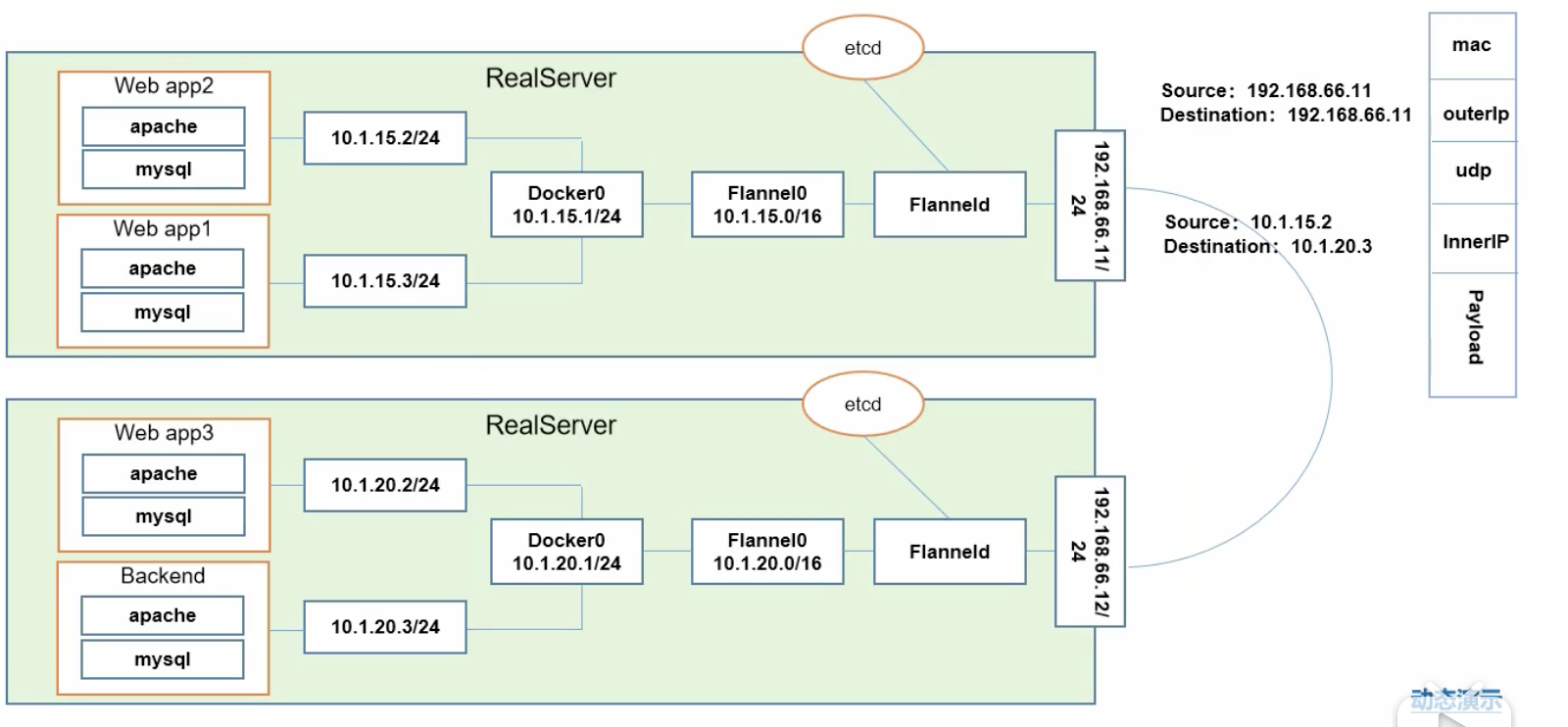
这里画了两台物理机. 一台的ip是192.168.66.11,另一台是192.168.66.12
这里运行了四个pod,分别是: web app2,web app1,web app3,Backend(前端组件),他们之间的关系如下:
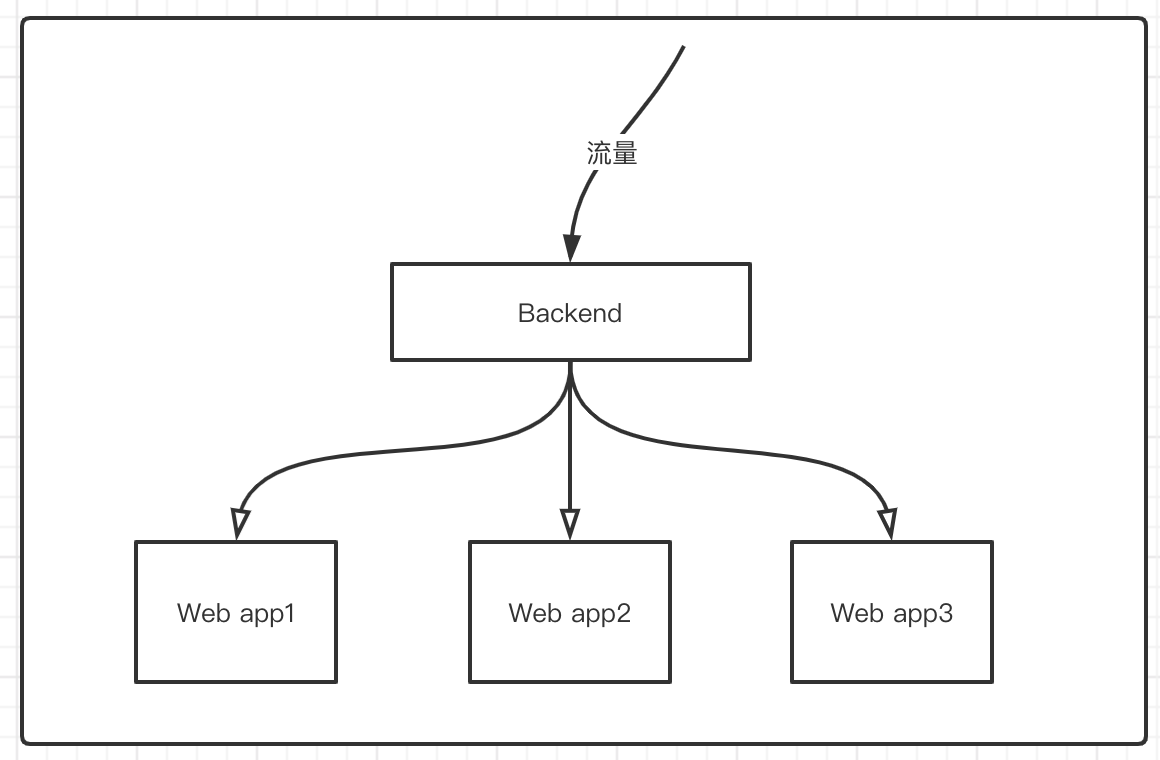
Backend是大前端,流量来了,都先进入Backend,然后通过网关分发到web app1,web app2,web app3
那么,如果Backend想要和Web app2 和Web app1通讯的时候,就需要跨主机了. 如果和Web app3通讯那就是同主机了.
他们是怎么通讯的呢?
首先. 在真实的服务器上,我们会安装一个Flanneld的守护进程,这个进程会监听一个端口. 这个端口就是用来后期转发数据包的服务端口. Flannel进程启动以后,会开启一个网桥,叫Flannel0,这个网桥专门收集Docker0转发出来的数据报文. 可以理解为他是一个钩子函数. 强行获取数据报文. Docker0会分配自己的ip到对应的pod上.
如果是同一个主机上的两个不同的pod相互访问,他走的是docker0的网桥. 大家是在同一个网桥下的两个子网而已. 所以,可以走docker0网桥进行转发

那么如何跨主机,还能通过对方的ip到达呢?
假设,现在web app2,想要把数据报发到backend. 他的源ip是10.1.15.2/24,目标ip要写10.1.20.3/24. 因为自己和目标不是同一个网段,所以,web app2发到docker0网关,docker0上会有对应的钩子函数,把数据报抓到Flannel0里,Flannel里面有一堆的路由表记录,写入到的主机,判断到底路由到哪台机器. 到了Flannel0以后,Flannel0是Flanneld开启的网桥,这个数据包会到Flanneld,然后Flanneld会对数据包进行封装,怎么封装呢? 看下图:

第一次封装: 源是192.168.66.11,目标是192.168.66.12
第二次封装: 下一层是udp的数据报文,也就是说flannel使用的是udp的数据报文去转发数据报的,因为更快,毕竟在同一个局域网内部.
再下一层,又封装了新的send信息. 源是:10.1.15.2,目标是10.1.20.3
封装到这一层以后,外面封装了一个数据包实体Payload. 然后被转发到192.168.66.12上来,原因是,你上面写了目标机器是谁. 并且目标端口,应该是192.168.66.12中flanneld的端口,所以这个数据包会被flanneld截获. 截获以后,flannel会进行拆封,拆封完了一个后,会转发到flannel0,flannel0会转发到docker0,docker0会找到10.1.20.3这个pod. 并且这是经过二次解封的,第一层封装的信息,他是看不见的. 他只能看到第二次封装的信息. 这样他看到了源是10.1.15.2,目标就是自己10.1.20.3,这样就实现了跨主机访问的网络.

其实这个过程,资源消耗是比价高的,因为要进行数据包的封装,然后还要进行数据包的解封. 这就是flanneld网络的通讯方案.
2. ETCD之Flannel提供说明:
1)存储管理Flannel可分配的IP地质资源端
也就意味这,flannel启动以后,回像ETCD里插入可以被分配的网段. 并且把那个网段分配到哪台机器了,他要记录上. 防止已分配的网段,再被flannel利用,分配给其他node节点.
2) 监控ETCD中每个pod的实际地址,并在内存中建立维护pod节点路由表
为什么需要维护pod节点路由表? 我们在封装的时候,最上层,我们要知道对方主机的信息. 我怎么知道你这个pod网段对应的物理主机是102.168.66.12呢? 就是因为这里维护了etcd中每个pod的实际地址信息.
ETCD在k8s集群中的角色是非常非常重要的. 如果要高可用的话,ETCD一定是首先需要高可用的组件. 好在ETCD的官方已经给我们解决好了集群化,并且非常优秀的集群化.
3. 总结 -- 不同情况下的网络通讯方式
1) 同一个pod内部通讯:
同一个pod共享同一个网络命名空间,共享同一个linux协议栈,通过localhost就可以访问
2) 不同pod之间通讯
a. 在同一台主机上: 有docker0网桥直接转发请求至pod2,不需要经过flannel
b. 不在同一台主机上: pod的地址是与docker0在同一个网段的. 但docker0网段与宿主机网卡是两个完全不同的IP网段,并且不同node之间的通信只能通过宿主机的物理网卡进行. 将Pod的ip和所在node的ip关联起来,通过这个关联让pod之间相互访问
这里说的比较简单,实际过程如上面,比这个要复杂的多
3) pod到Service的网络
目前,基于性能考虑,全部为iptables维护和转发,这个是比较老的啦,最新版的,我们已经改为lvs模式,也就是通过lvs转发和维护. 这样性能会更高
4) Pod到外网
也就是pod想上网怎么办?
pod向外网发送请求,查找路由表,转发数据包到宿主机网卡,宿主机网卡完成路由选择后,iptables执行Masquerade,把源IP更改为宿主网卡的ip,然后向外网服务器发请求.
也就是说,pod容器想上网,直接通过我们的SNat转换,动态转换去完成上网行为
5) 外网访问pod
外网访问pod,就需要借助到Service了
四. 组件通讯示意图
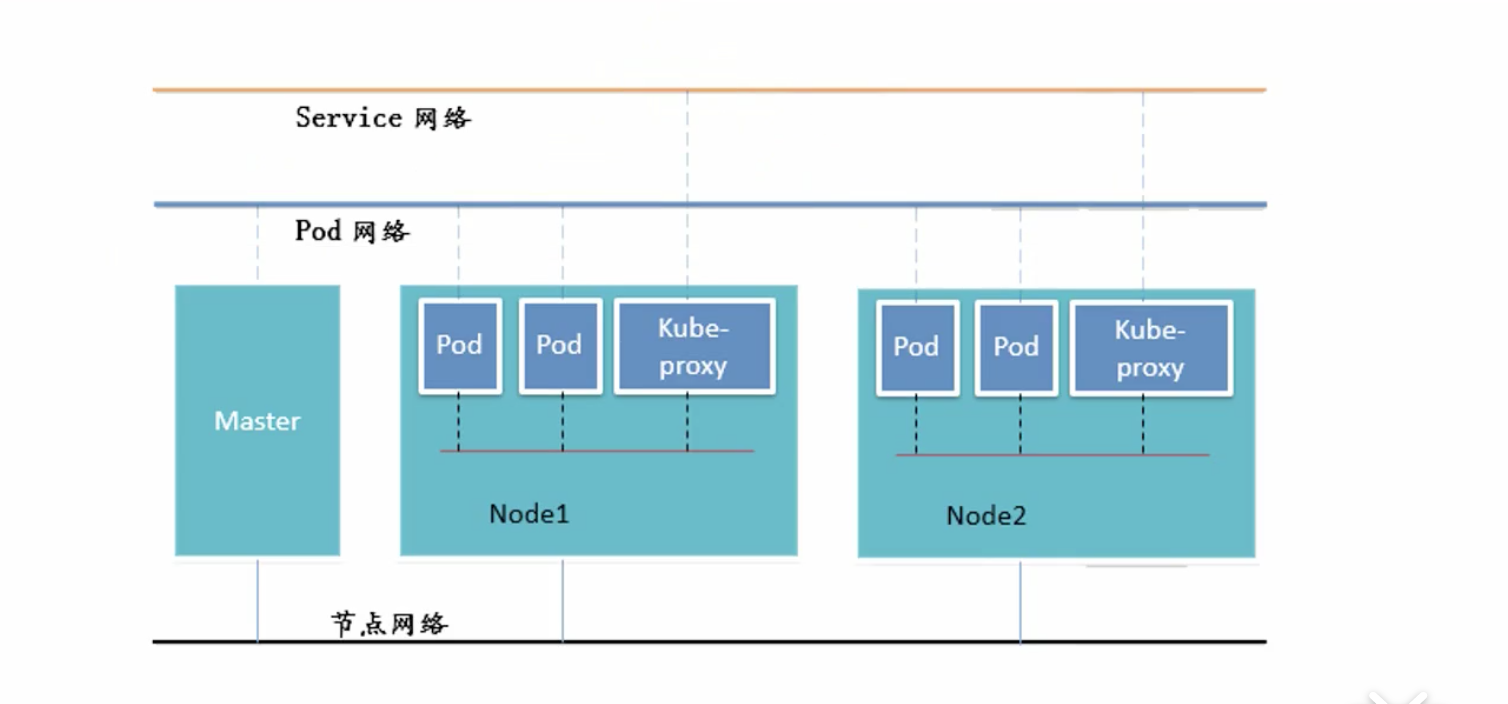
在k8s里有三层网络.
1. 节点网络
2. pod网络
3. service网络
需要注意的是: 真实的物理的网络只有1个, 就是节点网络. 也就是构建服务器的时候1张网卡就可以实现.
pod网络是一个虚拟网络,service网络也是虚拟网络. 我们可以把他们理解为一个内部网络
如果想要访问service,要在Service网络中去访问,Service在通过后端的iptables或lvs转换去和pod通讯
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。