
OpenPTK OpenPTK 架构OpenPTK 用例扩展 OpenPTK结束语 介绍

无论用户信息是否储存在目录服务中或 XML 文件中,OpenPTK 都允许开发人员为用户置备提供统一的 API。 通过使用
OpenPTK,开发人员将不必深入到每个用户信息存储库,而是集中利用API
定义完善的集合以便与已知几种用户存储库的用户置备框架进行交互。此后,如果所要求的用户存储不被 OpenPTK
支持,开发人员可以实现所要求的接口集合以便为框架提供与新用户存储库通信的通道。 除了利用像修改密码、重置密码和密码恢复此类密码管理功能之外,通过使用
OpenPTK,开发人员可以在用户存储库上执行 CRUD 操作。OpenPTK 的当前版本支持作为用户信息存储库的 LDAP (SPML)、 JDBC 和
Sun Identity Manager。
OpenPTK 为框架用户提供一些前端设备,以便轻松访问引导与用户存储库交互的框架功能。当前所提供的前端包括 JSR-168 portlet、JAX-RPS
Web 服务端点和 JSP 标记库,除此之外还包括为框架直接交互的 API。
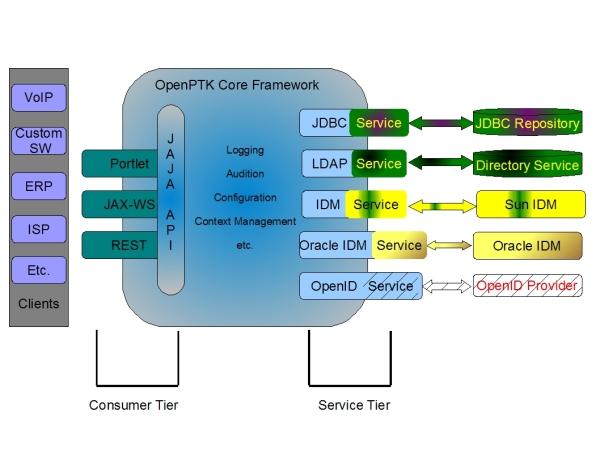
OpenPTK 架构
正如前面所述, OpenPTK 具备完善的架构,且具有易于扩展和易于定制的基类和接口;从开发人员的角度来看,OpenPTK
项目的目标是统一用户置备并使用用户信息存储库处理各种交互机制。以下是来自 OpenPTK 的三个顺序层:
- OpenPTK 使用层
- OpenPTK 服务层
- OpenPTK 核心框架
位于使用层的各个组件的目的是减轻针对不同应用程序和客户机对框架功能的访问。位于该层的各个组件不会实现特定接口或遵循由框架定义的一些规则;相
反,在不涉及所提供的 Java API 的情况下, 设计并实现它们旨在减少需要与 OpenPTK 核心框架交互的不同应用程序的开发。
OpenPTK 标记库、OpenPTK web 服务端点以及 OpenPTK JSR 168 portlet
等当前组件可以实现减轻需要用户置备的应用程序开发。除了带有直接访问 OpenPTK API 的 Java 应用程序, web 应用程序、门户系统以及基于
web 服务的应用程序(需要具有对于终端用户或系统管理员可用的用户置备)可以从当前使用层组件中获益。上述每个组件完全支持所述用户置备功能,并内部使用
OpenPTK Java API 执行这些任务。作为框架与使用方发生交互点的 OpenPTK Java API 位于
org.openptk.provision.* 包内。
OpenPTK 服务层包含与不同类型用户存储库(像 JDBC 或 LDAP
)发生通信的各个组件。该层通常是开发人员关注的焦点,目的是增添对用户信息存储库新类型的支持。您可以简单地通过开发一种新 服务
为用户信息存储库的其他类型( 像包含用户信息的 XML 层)添加支持,并且当需要时 OpenPTK 将接管与新服务的通信。OpenPTK
使用描述所有可用服务的配置文件以及向服务提供所需配置参数的其他详细信息。通常,每种 服务 具有两部分;第一部分负责执行 CRUD
操作。这部分必须扩展抽象类 org.openptk.provision.spi.Service 并实现
org.openptk.provision.spi.ServiceIF。提供这些类要求您编写向存储库插入、删除和编辑 用户的方法。
有时使用方必须通过用户存储库找到一个用户或一组用户,因此框架必须具备查询后端的标准方式,由于所有后端没有相同的查询机制,所以需要一个 转 换器
将框架标准查询转换为特定于后端的查询。OpenPTK 提供了接口和抽象类,当被实现时允许框架以统一的方式查询所有用户存储库。查询转换器应扩展
org.openptk.provision.spi.QueryConverter 抽象类,且必须实现
org.openptk.provision.spi.QueryConverterIF 接口,以便当用户或服务需要执行查询时允许框架加载该接口。
OpenPTK 核心框架的责任是桥接使用方和服务层。为了执行该项任务,核心框架需要使用它应该使用的适当 上下文 配置。针对用户置备而使用 OpenPTK
的第一步是加载配置文件。配置文件包含对 服务、上下文、对 象、 记录程序等的描述。 上下文 是我们用来互连各个特定 服务、对
象、记录程序的元素,且对用户存储库的访问将遍历我们选择的 上下文。
图 1 简要地演示了 OpenPTK 架构。
OpenPTK 用例
作为 IT 系统的使能器和加速器,置备用于:
- VoIP 服务提供方
- ERP 系统提供方
- 互联网服务提供方
- 定制应用程序开发
- 遗留应用程序集成
使用置备子系统可以减少开发人员需要花费在用户管理方面的精力。通常我们在企业间已经拥有几个身份存储库,并且用户置备的良好实现使得开发人员掌握
身份管理的中心点,从而减少编程错误或用户错误的风险。拥有了用户身份管理的中心点,您可以在单点中针对用户管理应用所有规则,而不是在企业范围系统的几
个部分中应用所有规则。
扩展 OpenPTK
正如您已经看到的情况,可以通过在服务层中添加新服务扩展 OpenPTK 以便支持新的用户存储库。在查看扩展的 OpenPTK
前,我们应了解如何使用它。以下示例代码 显示如何创建新的用户。配置文件名称是 openptk.xml ,我们用于与用户存储库交互的上下文被称作
sample-xml-store-context。
示例代码片断将用户信息存储到存储库,而无需了解是那个存储库或其具备的结构种类。存储库由我们使用的上下文决定,因此更改我们使用的上下文可以更改我们
所交互的存储库。
try {
Configuration conf = new Configuration("openptk.xml");
SubjectIF subject = conf.getContextSubject("sample-xml-store-context");
Input input = new Input();
Output output = null;
input.addAttribute("userid", "Jack@ctu.com");
input.addAttribute("firstname", "Jack");
input.addAttribute("lastname", "Bauer");
input.addAttribute("password", "mypassword");
output = subject.doCreate(input);
} catch (ProvisionException ex) {
System.out.println("Operation failed" + ex.getMessage());
}
输入 和 输出
是使用方通常用来向服务发送所需数据或从服务获取结果的两个类。但是框架核心将添加更多信息以便允许服务有效执行所请求的操作。正如您能看到的,在我们执
行任何操作前,我们将添加包含前面提及的所有关于配置信息的配置文件。配置文件的默认名称为 openptk.xml ;在我们调用 配 置
的无带参数构造器时加载框架。在第二行中我们试图使用称作 sample-xml-store-context 的 上下文。sample-xml-
store-context 的说明如下:
<Context id="sample-xml-store-context">
<Subject id="Person"/>
<Service id="xml-store">
<Properties>
<Property name="filepath" value="/opt/openptk-sample/storage.xml"/>
</Properties>
</Service>
<Query type="EQ" name="userid" value="10459845"/>
</Context>
该上下文 在 上下文 内部被定义,其中包含几个 上下文 标记。正如您能看到的,上下文 使用在 xml-store ID 下定义的 上下
文。当框架初始化服务时,上下文 挑选所定义的属性。每个 上下文 可以根据需要初始化许多属性。例如,JDBC 服务可以具有
jdbcurl、username、password、driver-class等
属性。最后当我们使用查询无参数构造器时可以决定使用的默认查询类型。其他两个属性定义用于查询的对象属性和在候选实体中该属性的值。上述代码片断显示如 何向
上下文 分配 上下文,而 上下文 本身的定义如下所示:
<Service id="xml-store"
classname="org.openptk.provision.spi.XmlStore"
description="A sample Service for managing XML identity storage" sort="userid">
<Properties>
<Property name="filepath" value="/opt/openptk-sample/storage.xml"/>
</Properties>
<Operations>
<Operation type="create"/>
<Operation type="read"/>
<Operation type="update"/>
<Operation type="delete"/>
<Operation type="search"/>
</Operations>
<Attributes>
<Attribute id="userid" servicename="userid"/>
<Attribute id="firstname" servicename="givenName"/>
<Attribute id="lastname" servicename="lastname" required="true"/>
<Attribute id="password" servicename="password" required="true"/>
</Attributes>
</Service>
该定义可以包括具有默认值的所需属性、实现和支持服务的操作、在 Subject 属性之间的映射以及具有必要约束的等效 Context
属性。Context
属性名称的每个属性值将存储在身份信息存储库中的名称下。通过使用映射机制,我们可以将我们在使用层内使用的属性名称与从后端用于存储属性值的真实属性名 称分开。
所定义的 上下文 使用具有惟一 ID 称作 Person 的 对象。 我们在 Subject
标记中定义的内容反映每个对象应具有的属性,这些属性应是如何处理的 ( 强制性的、可选的、可能具有的约束性、类型等等 )、这些属性如何被传递到 CRUD
操作以及它们如何被转换等等。下列示例代码显示了 对 象 是如何被定义的。出于简单,该 对象 只约束一个属性。
<Subject id="Person" key="userid" password="password" classname="org.openptk.provision.api.Person">
<Attributes>
<Attribute id="fullname">
<Transformations>
<Transform type="toService" useexisting="true"
classname="org.openptk.provision.transform.ConcatStrings">
<Operations>
<Operation type="create"/>
<Operation type="update"/>
</Operations>
<Arguments>
<Argument name="arg1" arg="attribute" value="firstname"/>
<Argument name="arg2" arg="literal" value=" "/>
<Argument name="arg3" arg="attribute" value="lastname"/>
</Arguments>
</Transform>
<Transform type="toFramework" useexisting="true"
classname="org.openptk.provision.transform.ConcatStrings">
<Operations>
<Operation type="read"/>
<Operation type="search"/>
</Operations>
<Arguments>
<Argument name="arg1" arg="attribute" value="firstname"/>
<Argument name="arg2" arg="literal" value=" "/>
<Argument name="arg3" arg="attribute" value="lastname"/>
</Arguments>
</Transform>
</Transformations>
</Attribute>
</Attributes>
</Subject>
首先,我们已经拥有一个 对象,它带有称作 userid 的惟一标识符属性、password 属性和 classname。key
属性是一个可以与定义 fullname 的相同方式定义的属性。classname 属性指向在扩展
org.openptk.provision.api.Subject 和实现 org.openptk.provision.api.SubjectIF
完全合格类的名称。应用该选项来使用自定义对象类使我们对执行对象的 CRUD 操作更好地控制。fullname 属性由 firstname 空格字符和
lastname 组成。转换定义可以帮助我们在向 上 下文
发送属性前,或者在从服务提取该属性时向框架传递属性前通过对属性执行自定义转换获得当前属性。在 OpenPTK 中已经存在几种默认的转换,例如
org.openptk.provision.transform.ConcatString。OpenPTK 转换类应扩展
org.openptk.provision.transform.Transformation 并实现
org.openptk.provision.transform.TransformationIF。在
org.openptk.provision.transform.TransformationIF.transform(...)
方法内部,由于参数可以通过参数名称与值之间的映射进行访问,因此每种转换都可以获得任意数量的参数。
现在应该查看一下 org.openptk.provision.spi.Service 抽象类和
org.openptk.provision.spi.ServiceIF 接口,它们是每个 上下文 类的直接父类。
您在阅读本文过程中可能会问“我们为什么针对 OpenPTK 的所有所述部分扩展抽象类 且
实现接口?”原因是在接口中存在几种方法,且所有这些方法通常在不同的扩展之间具有相同的实现方法。因此 OpenPTK
开发人员决定将那些不同的方法放入到抽象类中,并决定他们是否更改那些通常相同的功能。在每项服务中应被实现的重要方法如下所示:
- void doCreate(RequestIF req, ResponseIF res)
- void doRead(RequestIF req, ResponseIF res)
- void doUpdate(RequestIF req, ResponseIF res)
- void doDelete(RequestIF req, ResponseIF res)
- void doSearch(RequestIF req, ResponseIF res)
- void doPasswordChange(RequestIF req, ResponseIF res)
- void doPasswordReset(RequestIF req, ResponseIF res)
- void startup()
- void shutdown()
除 启动 功能外,方法名称说明了每种方法的预期功能,其中,我们应初始化我们在服务期内使用的资源,例如数据库连接等。类似地, 停止
功能在类符合垃圾收集条件前将执行清除操作。
在下列示例代码中,我们假设拥有与下列 XML 文档类似的示例用户存储库。
<persons>
<person>
<userid>Jack@ctu.com</userid>
<name>Jack</name>
<lastname>Bauer</lastname>
<password>sample_pass</password>
</person>
</persons>
下列 doRead 和 doCreate 的示例实现显示了如何使用 RequestIF 和 ResponseIF 参数。
@Override
public void doRead(RequestIF request, ResponseIF response) throws ServiceException {
try {
String keyFw = this.getContext().getDefinition().getKey();
String keySrvc = this.getSrvcName(keyFw);
String xpathString;
String keyValue = request.getSubject().getUniqueId();
List<Component> attributes = new LinkedList<Component>();
String[] attributeNames =
{"userid", "givenname", "lastname", "password"}; //attribute IDs used by repository
String UNIQIE_ID = "userid";
Component compnt;
if (keyValue != null && keyValue.length() > 0) {
if (keySrvc != null && keySrvc.length() > 0) {
xpathString = "//person[@" + keySrvc + "=" + "'" + keyValue + "']";
response.setUniqueId(keyValue);
} else {
response.setStatus("Unique Id attribute name is not set");
return;
}
} else {
response.setStatus("UniqueId value is not set");
return;
}
this.getProperty("filepath");
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
DocumentBuilder db = dbf.newDocumentBuilder();
/*
We have access to all properties that we defined in openptk.xml
These attributes let us have access to configuration parameters that
Service need to operate correctly.
*/
XPath xpath = XPathFactory.newInstance().newXPath();
Document persons = db.parse(this.getProperty("filepath"));
Node person = (Node) xpath.evaluate(xpathString, persons, XPathConstants.NODE);
/*
Now we have the person with all of its attributes.
we can send the attributes back by using the response object.
however we can check the request object to see which attributes are
requested and then only send back the attributes that are requested.
*/
for (int i = 0; i < attributeNames.length; i++) {
String attributeName = attributeNames[i];
String attrXPath = "/" + attributeName+"/text()";
compnt = new Component();
String nodeValue = (String) xpath.evaluate(attrXPath, person, XPathConstants.STRING);
if (UNIQIE_ID.equals(this.getSrvcName(attributeName))){//we are dealing with uniqueID
compnt.setUniqueId(attributeName);
} else {
/*other attributes, we need to send back attributes with thier attributes id as
* defined in openptk.xml configuration file, it is what getFwName do.
*/
BasicAttr attr = new BasicAttr(this.getFwName(attributeName), nodeValue);
compnt.setAttribute(this.getFwName(attributeName), attr);
}
attributes.add(compnt);//adding component to the list of attributes
}
response.setResults(attributes);
response.setStatus("Search Complete");
return;
} catch (Exception ex) {
//Handle the exceptions...
}
}
doCreate() 是在存储库中创建用户的方法,可能类似于:
@Override public void doCreate(RequestIF request, ResponseIF response) throws ServiceException
{
Properties attribValues= new Properties();
Map<String, AttrIF> attributes=request.getSubject().getAttributes();
Iterator<AttrIF> attNames=attributes.values().iterator();
while(attNames.hasNext()){
AttrIF attrib = attNames.next();
if(attrib!=null){
attribValues.put(attrib.getServiceName(), attrib.getValue());
}
}
/*As you saw we get service name of each attribute in order to make sure that attribute
*will be saved with the service dependent name.
Here we have a list of all attributes and their values,
just form the required structure and insert it into the storage
*/
response.setState(ResponseIF.STATE_SUCCESS);
response.setStatus("Create operation complete");
/*
We can send back some attributes to the framework when we finish the
creating the subject, for example we may return back a sequence number
indicating our user auto generated ID.
*/
Component copnt = new Component();
BasicAttr attr = new BasicAttr("sequenceID","database_returned_ID");
copnt.setAttribute("sequenceID",attr);
List<Component> resultList = new ArrayList<Component>(1);
resultList.add(copnt);
response.setResults(resultList);
return;
}
最后,我们需要实现某一查询机制使框架在身份存储库的顶端执行典型查询。正如前面所述,通常只有一种实现的方法;该方法应以满足我们在配置文件中定
义的查询类型的方式实现。目前存在 10 多种查询方式,分为简单查询和复杂查询两类。在第一种情况下,简单查询操作数可以是任何一种 Boolean
操作符;例如:like、begin with、end with、equal、not equal
等等。复杂的查询是两个简单查询的结合或通过 and 或 or 操作数实现的复杂查询。equal 查询类型的示例实现如下所示:
@Override public Object convert() throws QueryException
{
StringBuffer buf = new StringBuffer();
String name = null;
int type = 0;
type = query.getType();
if (type == Query.TYPE_AND || type == Query.TYPE_OR) {
// COMPLEX QUERY, We wave them for sake of simplicity
}
else{ // Simple query
name = query.getServiceName();//Do we have a default query?
if (name == null || name.length() < 1) {
name = query.getName();
}
switch (type) {
case Query.TYPE_EQUALS: {
buf.append("//person[@" + name + "='" + query.getValue() + "']");
break;
}
/*
Generally the way to implement other query types is similar to
Query.TYPE_EQUALS with some changes regarding the logic of
selecting nodes.
*/
case Query.TYPE_BEGINSWITH:
case Query.TYPE_CONTAINS:
case Query.TYPE_ENDSWITH:
case Query.TYPE_GREATER:
case Query.TYPE_GREATER_EQ:
case Query.TYPE_LESS:
case Query.TYPE_LESS_EQ:
case Query.TYPE_NOTEQUALS:
case Query.TYPE_SOUNDSLIKE:
}
}
return buf.toString();
}
结束语
如您所见,针对 OpenPTK 的新服务实现在日常项目中就像编写非常普通的代码段一样轻松。OpenPTK
具备设计良好的架构,从而支持在框架中添加任何种类的扩展。
如上所述,OpenPTK 使用层具有一些像置备 portlet 和 JAX-RPC web 服务这样的组件,它们构建在 OpenPTK 的使用方 Java
API 顶端。您必须具备与来自应用程序的 OpenPTK 核心进行通信的其他方法;例如,您可以在 OpenPTK Java API 顶端开发 REST
端点,以便使 REST 友好应用程序执行用户置备操作。第 一个示例 演示了如何从 REST 端点访问 OpenPTK 代码以便执行任何用户置备。
OpenPTK OpenPTK 架构OpenPTK 用例扩展 OpenPTK结束语 官网
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。