
大家都知道 Kafka 是一个非常牛逼的消息队列框架,阿里的 RocketMQ 也是在 Kafka 的基础上进行改进的。对于初学者来说,一开始面对这么一个庞然大物会不知道怎么入手。那么这篇文章就带你先了解一下 Kafka 的技术架构,让你从全局的视野认识 Kafka。了解了 Kafka 的整体架构和消息流程之后,脑海里就会有一个大致的结构,这时候再去学习每个部分就容易得多了。
我们先来看一下 Kafka 的整体架构图:
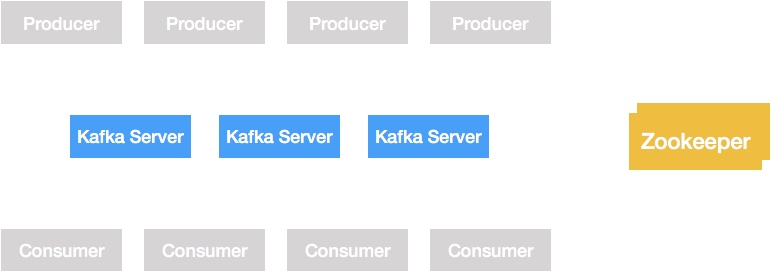
Kafka 的架构图可以分为四个部分:
- Producer Cluster:生产者集群。一般由许多个实际的业务项目组成,其不断地往 Kafka 集群中写入数据。
- Kafka Cluster:Kafka 服务器集群。这里就是 Kafka 作为重要的一部分,这里负责接收生产者写入的数据,并将其持久化到文件里,最终将消息提供给 Consumer Cluster。
- Zookeeper Cluster:Zookeeper 集群。Zookeeper 负责维护整个 Kafka 集群的 Topic 信息、Kafka Controller 等信息。
- Consumer Cluster:消费者集群。与 Producer Cluster 一样,其一般是由许多个实际的业务项目组成,不断地从 Kafka Cluster 中读取数据。
了解了 Kafka 的整体架构,那一个消息是怎么从生产者到 Kafka Server,又是如何从 Kafka Server 到消费者的呢?一般来说,一个消息的流转可以分为下面几个阶段:
- 服务器启动阶段
- 生产者发送消息阶段
- Kafka存储消息阶段
- 消费者拉取消息阶段
服务器启动阶段
首先,我们会启动 Zookeeper 服务器,作为集群管理服务器。接着,启动 Kafka Server。Kafka Server 会向 Zookeeper 服务器注册信息,接着启动线程池监听客户端的连接请求。最后,启动生产者和消费者,连接到 Zookeeper 服务器,从 Zookeeper 服务器获取到对应的 Kafka Server 信息[1]。
生产者发送消息阶段
当需要将消息存入消息队列中时,生产者根据配置的分片算法,选择分到哪一个 partition 中。在发送一条消息时,可以指定这条消息的 key,Producer 根据这个 key 和 Partition 机制来判断应该将这条消息发送到哪个 Parition。
Paritition 机制可以通过指定 Producer 的 paritition.class 这一参数来指定,该 class 必须实现 kafka.producer.Partitioner 接口。如果不实现 Partition 接口,那么会使用默认的分区算法,即根据根据 key 哈希后取余[2]。
随后生产者与该 Partition Leader 建立联系,之后将消息发送至该 partition leader。之后生产者会根据设置的 request.required.acks 参数不同,选择等待或或直接发送下一条消息。
- request.required.acks = 0 表示 Producer 不等待来自 Leader 的 ACK 确认,直接发送下一条消息。在这种情况下,如果 Leader 分片所在服务器发生宕机,那么这些已经发送的数据会丢失。
- request.required.acks = 1 表示 Producer 等待来自 Leader 的 ACK 确认,当收到确认后才发送下一条消息。在这种情况下,消息一定会被写入到 Leader 服务器,但并不保证 Follow 节点已经同步完成。所以如果在消息已经被写入 Leader 分片,但是还未同步到 Follower 节点,此时Leader 分片所在服务器宕机了,那么这条消息也就丢失了,无法被消费到。
- request.required.acks = -1 表示 Producer 等待来自 Leader 和所有 Follower 的 ACK 确认之后,才发送下一条消息。在这种情况下,除非 Leader 节点和所有 Follower 节点都宕机了,否则不会发生消息的丢失。
Kafka存储消息阶段
当 Kafka 接收到消息后,其并不直接将消息写入磁盘,而是先写入内存中。之后根据生产者设置参数的不同,选择是否回复 ack 给生产者。之后有一个线程会定期将内存中的数据刷入磁盘,这里有两个参数控制着这个过程:
# 数据达到多少条就将消息刷到磁盘
#log.flush.interval.messages=10000
# 多久将累积的消息刷到磁盘,任何一个达到指定值就触发写入
#log.flush.interval.ms=1000
如果我们设置 log.flush.interval.messages=1,那么每次来一条消息,就会刷一次磁盘。通过这种方式,就可以达到消息绝对不丢失的目的,这种情况我们称之为同步刷盘。反之,我们称之为异步刷盘。
于此同时,Kafka 服务器也会进行副本的复制,该 Partition 的 Follower 会从 Leader 节点拉取数据进行保存。然后将数据存储到 Partition 的 Follower 节点中。
消费者拉取消息阶段
在消费者启动时,其会连接到 zk 注册节点,之后根据所连接 topic 的 partition 个数和消费者个数,进行 partition 分配。一个 partition 最多只能被一个线程消费,但一个线程可以消费多个 partition。其分配算法如下:
1. 将目标 topic 下的所有 partirtion 排序,存于PT
2. 对某 consumer group 下所有 consumer 排序,存于 CG,第 i 个consumer 记为 Ci
3. N=size(PT)/size(CG),向上取整
4. 解除 Ci 对原来分配的 partition 的消费权(i从0开始)
5. 将第i*N到(i+1)*N-1个 partition 分配给 Ci
我们用例子简单描述下这个算法的内容:假设我们连接的 topic 有 8 个 partition,此时有 3 个消费线程。那么 partition 的分配过程大致是这样的:
- 8/3=2.667,向上取整就是3,也就是说每个consumer分配3个分区。
- 那么给第一个消费者分配p0/p1/p2三个分区。
- 给第二个消费者分配p3/p4/p5三个分区。
- 给第三个消费者分配p6/p7两个分区。
接着消费者连接对应分区的 Kafka Server,并从该分区服务器拉取数据。
总结
这篇文章简单介绍了 Kafka 框架的技术架构以及消息流转过程,并介绍了其中的某些细节。通过这篇文章,相信大家对 Kafka 框架应该有个大致的了解。
参考资料
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。