
k8s中的service
service存在的意义
防止Pod失联(服务发现)
定义一组Pod的访问策略(负载均衡)
对于kubernetes整个集群来说,Pod的地址也可变的,也就是说如果一个Pod因为某些原因退出了,而由于其设置了副本数replicas大于1,那么该Pod就会在集群的任意节点重新启动,这个重新启动的Pod的IP地址与原IP地址不同,这对于业务来说,就不能根据Pod的IP作为业务调度。kubernetes就引入了Service的概念,它为Pod提供一个入口,主要通过Labels标签来选择后端Pod,这时候不论后端Pod的IP地址如何变更,只要Pod的Labels标签没变,那么 业务通过service调度就不会存在问题。
当声明Service的时候,会自动生成一个cluster IP,这个IP是虚拟IP。我们就可以通过这个IP来访问后端的Pod,当然,如果集群配置了DNS服务,比如现在的CoreDNS,那么也可以通过Service的名字来访问,它会通过DNS自动解析Service的IP地址。
Pod与Service的关系
通过label-selector相关联
通过Service实现Pod的负载均衡( TCP/UDP 4层)
Port
service中主要涉及到了三种port:
port
这里的port表示service暴露在clusterIP上的端口,clusterIP:Port 是提供给集群内部访问kubernetes服务的入口。
targetPort
targetPort是pod上的端口,从port和nodePort上到来的数据最终经过kube-proxy流入到后端pod的targetPort上进入容器。
nodePort
就是Node的基本port。选择该值,这个servce就可以通过NodeIP:NodePort访问这个Service服务,NodePort会路由到Cluster IP服务,这个Cluster IP会通过请求自动创建。
总的来说,port和nodePort都是service的端口,前者暴露给集群内客户访问服务,后者暴露给集群外客户访问服务。从这两个端口到来的数据都需要经过反向代理kube-proxy流入后端pod的targetPod,从而到达pod上的容器内。
IP
service会涉及到几种ip
Node IP
Node节点的IP地址,即物理网卡的IP地址。
可以是物理机的IP(也可能是虚拟机IP),每个Service都会在Node节点上开通一个端口,外部可以通过NodeIP:NodePort即可访问Service里的Pod,和我们访问服务器部署的项目一样,IP:端口/项目名。
在k8s中查看
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
192.168.56.202 Ready <none> 71d v1.19.4
192.168.56.203 Ready <none> 71d v1.19.4
当然有的node是起了别名,就需要进去node中查看
$ kubectl describe node nodeName

Pod IP
Pod IP是每个Pod的IP地址,他是Docker Engine根据docker网桥的IP地址段进行分配的,通常是一个虚拟的二层网络。
1、同Service下的pod可以直接根据PodIP相互通信;
2、不同Service下的pod在集群间pod通信要借助于 cluster ip;
3、pod和集群外通信,要借助于node ip。
在kubernetes查询Pod IP
查看已有的pod
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
go-app-5d584885d7-2gf2b 1/1 Running 8 13d
go-app-5d584885d7-jnm8g 1/1 Running 8 13d
nginx-ds-695685c55-hcx82 1/1 Running 8 13d
nginx-ds-695685c55-pvtv9 1/1 Running 8 13d
nginx-ds-695685c55-rp5bb 1/1 Running 8 13d
查看某个pod的ip
$ kubectl describe pod go-app-5d584885d7-2gf2b

Cluster IP
Service的IP地址,此为虚拟IP地址。外部网络无法ping通,只有kubernetes集群内部访问使用。
Cluster IP是一个虚拟的IP
1、Cluster IP仅仅作用于Kubernetes Service这个对象,并由Kubernetes管理和分配P地址;
2、Cluster IP无法被ping,他没有一个“实体网络对象”来响应;
3、Cluster IP只能结合Service Port组成一个具体的通信端口,单独的Cluster IP不具备通信的基础,并且他们属于Kubernetes集群这样一个封闭的空间;
4、在不同Service下的pod节点在集群间相互访问可以通过Cluster IP。
查看 service的ip
$ kubectl describe svc go-app-svc
Name: go-app-svc
Namespace: default
Labels: <none>
Annotations: <none>
Selector: app=go-app
Type: NodePort
IP: 10.0.0.16
Port: <unset> 8000/TCP
TargetPort: 8000/TCP
NodePort: <unset> 45366/TCP
Endpoints: 172.17.10.4:8000,172.17.10.5:8000
Session Affinity: None
External Traffic Policy: Cluster
Events: <none>
ip如上是10.0.0.16
三种IP网络间的通信
service地址和pod地址在不同网段,service地址为虚拟地址,不配在pod上或主机上,外部访问时,先到Node节点网络,再转到service网络,最后代理给pod网络。
Kubernetes在其所有节点上开放一个端口给外部访问(所有节点上都使用相同的端口号), 并将传入的连接转发给作为Service服务对象的pod。这样我们的pod就可以被外部请求访问到。

Service几种类型
- ClusterIP:分配一个内部集群IP地址,只能在集群内部访问(同Namespace内的Pod),默认ServiceType。ClusterIP 模式的 Service 为你提供的,就是一个 Pod 的稳定的 IP 地址,即 VIP。
- NodePort:就是Node的基本port。选择该值,这个servce就可以通过
NodeIP:NodePort访问这个Service服务,NodePort会路由到Cluster IP服务,这个Cluster IP会通过请求自动创建; - LoadBalancer:使用云提供商的负载均衡器,可以向外部暴露服务,选择该值,外部的负载均衡器可以路由到NodePort服务和Cluster IP服务;
- ExternalName:通过返回 CNAME 和它的值,可以将服务映射到 externalName 字段的内容,没有任何类型代理被创建,可以用于访问集群内其他没有Labels的Pod,也可以访问其他NameSpace里的Service。
ClusterIP
Kubernetes以Pod作为应用部署的最小单位。kubernetes会根据Pod的声明对其进行调度,包括创建、销毁、迁移、水平伸缩等,因此Pod 的IP地址不是固定的,不方便直接采用Pod IP对服务进行访问。
为解决该问题,Kubernetes提供了Service资源,Service对提供同一个服务的多个Pod进行聚合。一个Service提供一个虚拟的Cluster IP,后端对应一个或者多个提供服务的Pod。在集群中访问该Service时,采用Cluster IP即可,Kube-proxy负责将发送到Cluster IP的请求转发到后端的Pod上。
Kube-proxy是一个运行在每个节点上的go应用程序,支持三种工作模式:
userspace
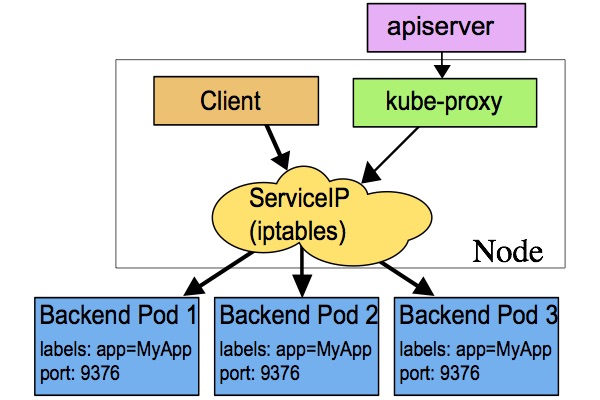
该模式下kube-proxy会为每一个Service创建一个监听端口。发向Cluster IP的请求被Iptables规则重定向到Kube-proxy监听的端口上,Kube-proxy根据LB算法选择一个提供服务的Pod并和其建立链接,以将请求转发到Pod上。
该模式下,Kube-proxy充当了一个四层Load balancer的角色。由于kube-proxy运行在userspace中,在进行转发处理时会增加两次内核和用户空间之间的数据拷贝,效率较另外两种模式低一些;好处是当后端的Pod不可用时,kube-proxy可以重试其他Pod。

iptables
为了避免增加内核和用户空间的数据拷贝操作,提高转发效率,Kube-proxy提供了iptables模式。在该模式下,Kube-proxy为service后端的每个Pod创建对应的iptables规则,直接将发向Cluster IP的请求重定向到一个Pod IP。
该模式下Kube-proxy不承担四层代理的角色,只负责创建iptables规则。该模式的优点是较userspace模式效率更高,但不能提供灵活的LB策略,当后端Pod不可用时也无法进行重试。
ipvs
该模式和iptables类似,kube-proxy监控Pod的变化并创建相应的ipvs rules。ipvs也是在kernel模式下通过netfilter实现的,但采用了hash table来存储规则,因此在规则较多的情况下,Ipvs相对iptables转发效率更高。除此以外,ipvs支持更多的LB算法。如果要设置kube-proxy为ipvs模式,必须在操作系统中安装IPVS内核模块。

NodePort
暴露端口到Node节点,可以通过Node节点访问容器。
如果设置 type 的值为 "NodePort",Kubernetes master 将从给定的配置范围内(默认:30000-32767)分配端口,每个 Node 将从该端口(每个 Node 上的同一端口)代理到 Service。
需要注意的是,Service 将能够通过
LoadBalancer
NodePort提供了一种从外部网络访问Kubernetes集群内部Service的方法,但该方法存在下面一些限制,导致这种方式主要适用于程序开发,不适合用于产品部署。
- Kubernetes cluster host的IP必须是一个well-known IP,即客户端必须知道该IP。但Cluster中的host是被作为资源池看待的,可以增加删除,每个host的IP一般也是动态分配的,因此并不能认为host IP对客户端而言是well-known IP。
- 客户端访问某一个固定的host IP的方式存在单点故障。假如一台host宕机了,kubernetes cluster会把应用 reload到另一节点上,但客户端就无法通过该host的nodeport访问应用了。
- 通过一个主机节点作为网络入口,在网络流量较大时存在性能瓶颈。
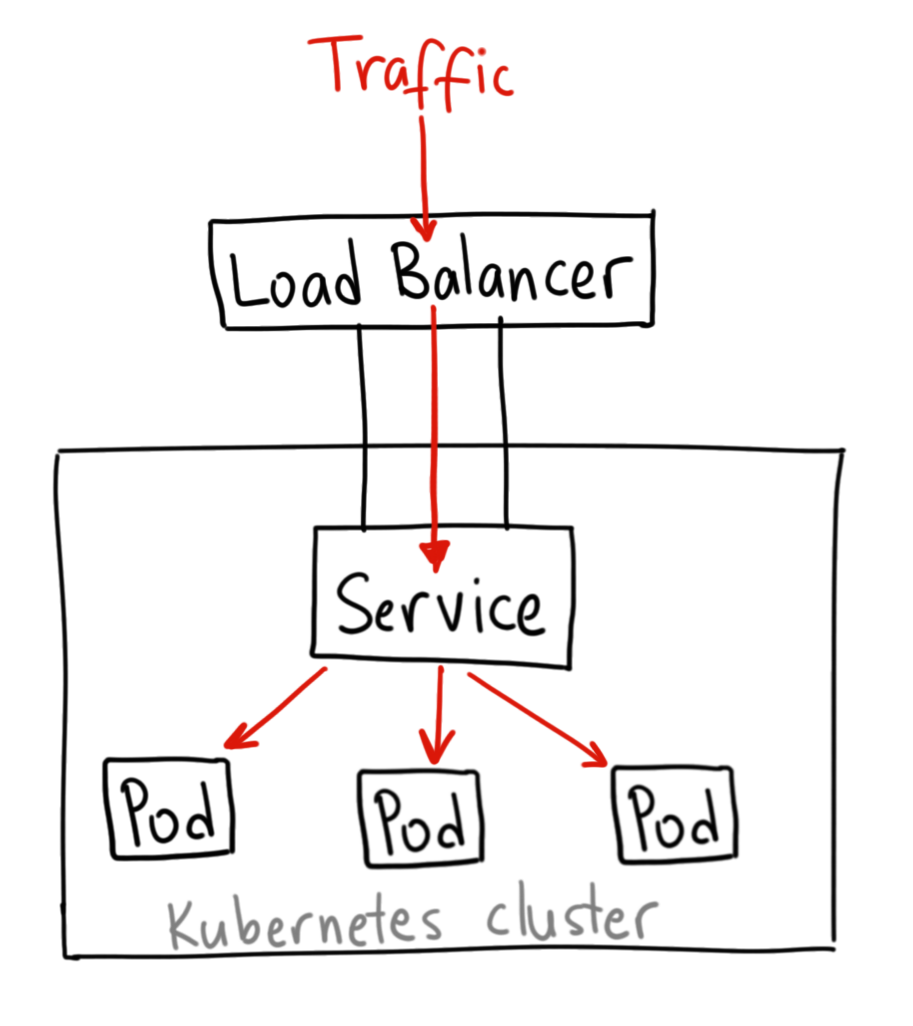
LoadBalancer解决了这些问题,通过将Service定义为LoadBalancer类型,Kubernetes在主机节点的NodePort前提供了一个四层的负载均衡器。该四层负载均衡器负责将外部网络流量分发到后面的多个节点的NodePort端口上。
- 在多台服务器之间有效地分配客户端请求或网络负载
- 通过仅向在线服务器发送请求来确保高可用性和可靠性
- 提供根据需求指示添加或减少服务器的灵活性
备注:LoadBalancer类型需要云服务提供商的支持,Service中的定义只是在Kubernetes配置文件中提出了一个要求,即为该Service创建Load Balancer,至于如何创建则是由Google Cloud或Amazon Cloud等云服务商提供的,创建的Load Balancer的过程不在Kubernetes Cluster的管理范围中。
目前WS,Azure,CloudStack,GCE 和 OpenStack 等主流的公有云和私有云提供商都可以为Kubernetes提供Load Balancer。一般来说,公有云提供商还会为Load Balancer提供一个External IP,以提供Internet接入。如果你的产品没有使用云提供商,而是自建Kubernetes Cluster,则需要自己提供LoadBalancer。
参考
【kubernetes中常用对象service的详细介绍】https://zhuanlan.zhihu.com/p/103413341
【Istio 运维实战系列(2):让人头大的『无头服务』-上】https://cloud.tencent.com/developer/article/1700748
【如何为服务网格选择入口网关?- Kubernetes Ingress,Istio Gateway还是API Gateway?】https://mp.weixin.qq.com/s?__biz=MzU3MjI5ODgxMA==&mid=2247483759&idx=1&sn=d44c3194810c02eba81d427292fab2d9&chksm=fcd2423acba5cb2c55e3d9952a74d06e6e5803e8a9755885e66630092e1687b57ad09154dc5f&scene=21#wechat_redirect
【iptables详解(1):iptables概念】https://www.zsythink.net/archives/1199
【Load Balancer】https://www.f5.com/services/resources/glossary/load-balancer#:~:text=A load balancer is a,users)%20and%20reliability%20of%20applications.
【What Is Load Balancing】https://www.nginx.com/resources/glossary/load-balancing/
【【K8S】Service服务详解,看这一篇就够了!!】https://www.cnblogs.com/binghe001/p/13166641.html
【k8s-集群里的三种IP(NodeIP、PodIP、ClusterIP)】https://blog.csdn.net/qq_21187515/article/details/101363521
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。