
1. 垃圾回收的简单回顾
关于垃圾回收算法,基本就是那么几种:标记-清除、标记-复制、标记-整理。在此基础上可以增加分代(新生代/老年代),每代采取不同的回收算法,以提高整体的分配和回收效率。
无论使用哪种算法,标记总是必要的一步。这是理算当然的,你不先找到垃圾,怎么进行回收?
垃圾回收器的工作流程大体如下:
- 标记出哪些对象是存活的,哪些是垃圾(可回收);
- 进行回收(清除/复制/整理),如果有移动过对象(复制/整理),还需要更新引用。
2. 三色标记法
2.1 基本算法
要找出存活对象,根据可达性分析,从 GC Roots 开始进行遍历访问,可达的则为存活对象(最终结果:A/D/E/F/G 可达):
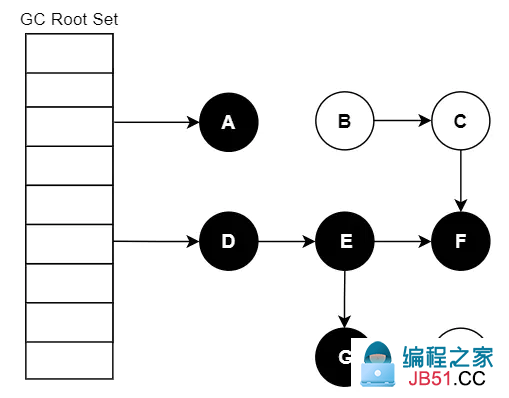
我们把遍历对象图过程中遇到的对象,按“是否访问过”这个条件标记成以下三种颜色:
- 白色:尚未访问过。
- 本对象已访问过,而且本对象引用到的其他对象也全部访问过了。
- 本对象已访问过,但是本对象引用到的其他对象尚未全部访问完。全部访问后,会转换为黑色。
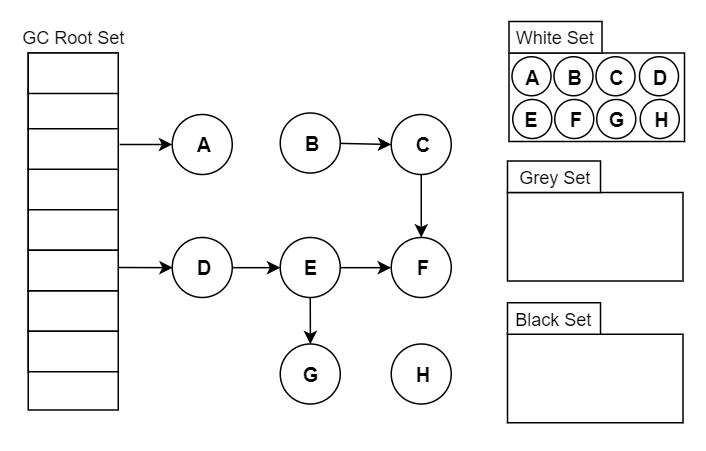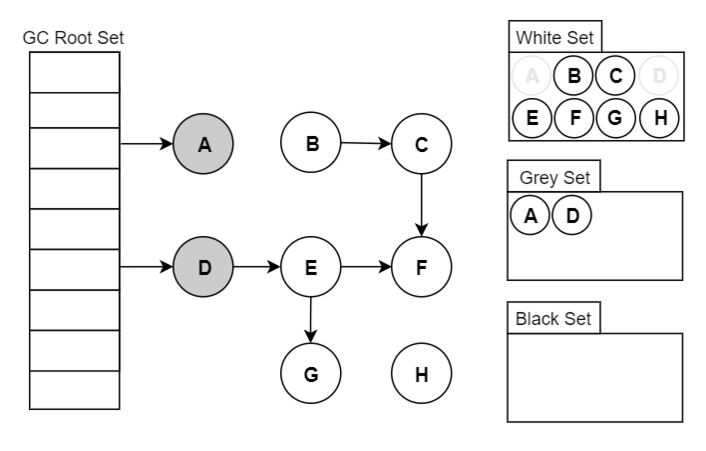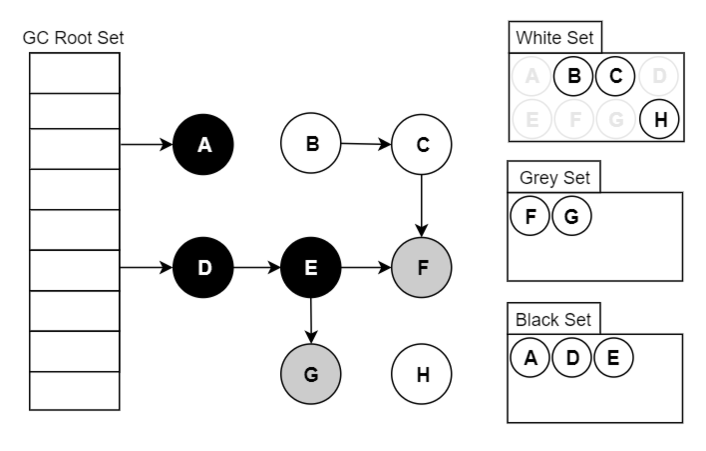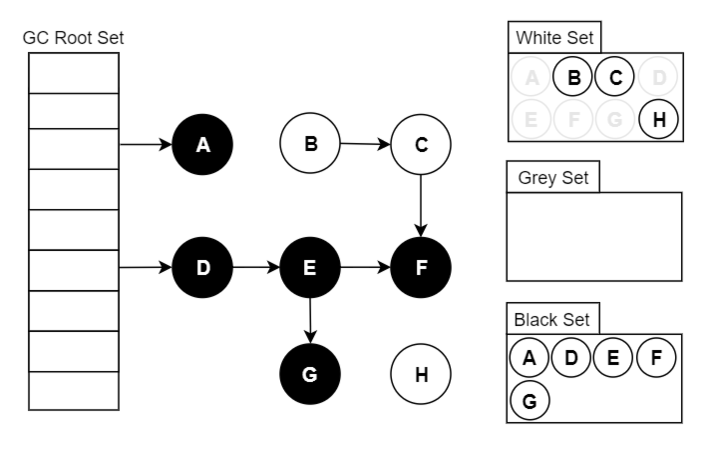
假设现在有白、灰、黑三个集合(表示当前对象的颜色),其遍历访问过程为:
- 初始时,所有对象都在【白色集合】中;
- 将 GC Roots 直接引用到的对象挪到 【灰色集合】中;
- 从灰色集合中获取对象:
3.1. 将本对象引用到的其他对象全部挪到 【灰色集合】中;
3.2. 将本对象挪到【黑色集合】里面。 - 重复步骤3,直至【灰色集合】为空时结束。
- 结束后,仍在【白色集合】的对象即为 GC Roots 不可达,可以进行回收。
注:如果标记结束后对象仍为白色,意味着已经“找不到”该对象在哪了,不可能会再被重新引用。
当 Stop The World (以下简称 STW)时,对象间的引用是不会发生变化的,可以轻松完成标记。
而当需要支持并发标记时,即标记期间应用线程还在继续跑,对象间的引用可能发生变化,多标和漏标的情况就有可能发生。
2.2 多标-浮动垃圾
假设已经遍历到 E(变为灰色了),此时应用执行了 objD.fieldE = null (D > E 的引用断开):
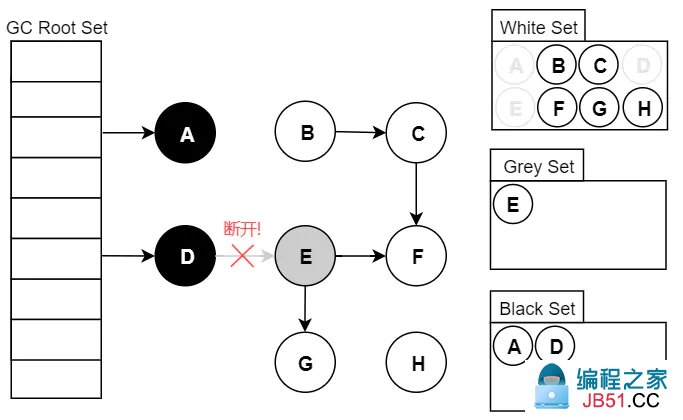
此刻之后,对象 E/F/G 是“应该”被回收的。然而因为 E 已经变为灰色了,其仍会被当作存活对象继续遍历下去。最终的结果是:这部分对象仍会被标记为存活,即本轮 GC 不会回收这部分内存。
这部分本应该回收 但是没有回收到的内存,被称之为“浮动垃圾”。浮动垃圾并不会影响应用程序的正确性,只是需要等到下一轮垃圾回收中才被清除。
另外,针对并发标记开始后的新对象,通常的做法是直接全部当成黑色,本轮不会进行清除。这部分对象期间可能会变为垃圾,这也算是浮动垃圾的一部分。
2.3 漏标-读写屏障
假设 GC 线程已经遍历到 E(变为灰色了),此时应用线程先执行了:
var G = objE.fieldG;
objE.fieldG = null; // 灰色E 断开引用 白色G
objD.fieldG = G; // 黑色D 引用 白色G
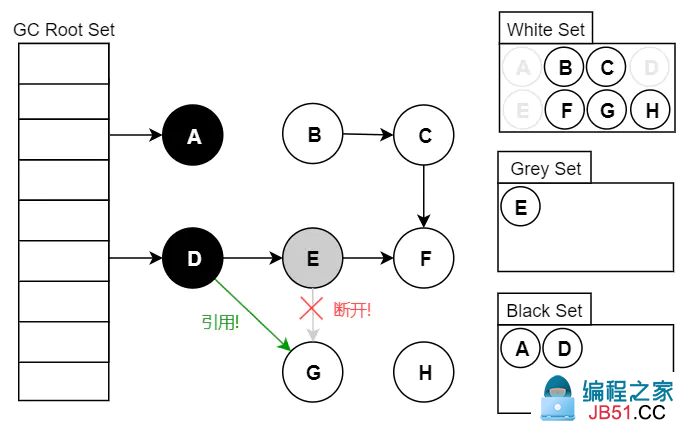
此时切回 GC 线程继续跑,因为 E 已经没有对 G 的引用了,所以不会将 G 放到灰色集合;尽管因为 D 重新引用了 G,但因为 D 已经是黑色了,不会再重新做遍历处理。
最终导致的结果是:G 会一直停留在白色集合中,最后被当作垃圾进行清除。这直接影响到了应用程序的正确性,是不可接受的。
不难分析,漏标只有同时满足以下两个条件时才会发生:
- 灰色对象断开了白色对象的引用(直接或间接的引用);即灰色对象原来成员变量的引用发生了变化。
- 黑色对象重新引用了该白色对象;即黑色对象成员变量增加了新的引用。
从代码的角度看:
var G = objE.fieldG; // 1.读
objE.fieldG = null; // 2.写
objD.fieldG = G; // 3.写
- 读取对象 E 的成员变量 fieldG 的引用值,即对象 G;
- 对象 E 往其成员变量 fieldG,写入 null值。
- 对象 D 往其成员变量 fieldG,写入对象 G ;
我们只要在上面这三步中的任意一步中做一些“手脚”,将对象 G 记录起来,然后作为灰色对象再进行遍历即可。比如放到一个特定的集合,等初始的 GC Roots 遍历完(并发标记),该集合的对象遍历即可(重新标记)。
重新标记是需要 STW 的,因为应用程序一直在跑的话,该集合可能会一直增加新的对象,导致永远都跑不完。当然,并发标记期间也可以将该集合中的大部分先跑了,从而缩短重新标记 STW 的时间,这个是优化问题了。
写屏障用于拦截第二和第三步;而读屏障则是拦截第一步。
它们的拦截的目的很简单:就是在读写前后,将对象 G 给记录下来。
3. 写屏障
给某个对象的成员变量赋值时,其底层代码大概长这样:
/**
* @param field 某对象的成员变量,如 D.fieldG
* @param new_value 新值,如 null
*/
void oop_field_store(oop* field,oop new_value) {
*field = new_value; // 赋值操作
}
所谓的写屏障,其实就是指在赋值操作前后,加入一些处理(可以参考AOP的概念),读屏障的含义也类似。
void oop_field_store(oop* field,oop new_value) {
pre_write_barrier(field); // 写屏障-写前操作
*field = new_value;
post_write_barrier(field,value); // 写屏障-写后操作
}
3.1 写屏障 + SATB
当对象 E 的成员变量的引用发生变化时(objE.fieldG = null;),我们可以利用写屏障,将 E 原来成员变量的引用对象 G 记录下来:
void pre_write_barrier(oop* field) {
oop old_value = *field; // 获取旧值
remark_set.add(old_value); // 记录 原来的引用对象
}
当原来成员变量的引用发生变化之前,记录下原来的引用对象。
这种做法的思路是:尝试保留开始时的对象图,即原始快照(Snapshot At The Beginning,SATB),当某个时刻 的 GC Roots 确定后,当时的对象图就已经确定了。
比如 当时 D 是引用着 G 的,那后续的标记也应该是按照这个时刻的对象图走(D 引用着 G)。如果期间发生变化,则可以记录起来,保证标记依然按照原本的视图来。
SATB 破坏了条件一:【灰色对象断开了白色对象的引用】,从而保证了不会漏标。
3.1 写屏障 + 增量更新
当对象 D 的成员变量的引用发生变化时(objD.fieldG = G;),我们可以利用写屏障,将 D 新的成员变量引用对象 G 记录下来:
void post_write_barrier(oop* field,oop new_value) {
if($gc_phase == GC_CONCURRENT_MARK && !isMarkd(field)) {
remark_set.add(new_value); // 记录新引用的对象
}
}
当有新引用插入进来时,记录下新的引用对象。
这种做法的思路是:不要求保留原始快照,而是针对新增的引用,将其记录下来等待遍历,即增量更新(Incremental Update)。
增量更新破坏了条件二:【黑色对象重新引用了该白色对象】,从而保证了不会漏标。
4. 读屏障
oop oop_field_load(oop* field) {
pre_load_barrier(field); // 读屏障-读取前操作
return *field;
}
读屏障是直接针对第一步:var G = objE.fieldG;,当读取成员变量时,一律记录下来:
void pre_load_barrier(oop* field,oop old_value) {
if($gc_phase == GC_CONCURRENT_MARK && !isMarkd(field)) {
oop old_value = *field;
remark_set.add(old_value); // 记录读取到的对象
}
}
这种做法是保守的,但也是安全的。因为条件二中【黑色对象重新引用了该白色对象】,重新引用的前提是:得获取到该白色对象,此时已经读屏障就发挥作用了。
5. 三色标记法与现代垃圾回收器
现代追踪式(可达性分析)的垃圾回收器几乎都借鉴了三色标记的算法思想,尽管实现的方式不尽相同:比如白色/黑色集合一般都不会出现(但是有其他体现颜色的地方)、灰色集合可以通过栈/队列/缓存日志等方式进行实现、遍历方式可以是广度/深度遍历等等。
对于读写屏障,以Java HotSpot VM 为例,其并发标记时对漏标的处理方案如下:
- CMS:写屏障 + 增量更新
- G1:写屏障 + SATB
- ZGC:读屏障
作者:路过的猪
链接:https://www.jianshu.com/p/12544c0ad5c1
来源:简书
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。