
Kafka的概念和入门
Kafka是一个消息系统。由LinkedIn于2011年设计开发。
Kafka是一种分布式的,基于发布/订阅的消息系统。主要设计目标如下:
- 以时间复杂度O(1)的方式提供消息持久化能力,即使对TB级以上数据页能保证常数时间复杂度的访问性能。
- 高吞吐率。即使在非常廉价的商用机器上也能做到单机支持每秒100K条以上的消息传输。
- 支持Kafka Server间的消息分区,及分布式消费,同时保证每个Partition内的消息顺序传输。
- 同时支持离线数据处理和实时数据处理。
- 支持在线水平扩展。
消费者是采用pull模式从Broker订阅消息。
| 模式 | 优点 | 缺点 |
|---|---|---|
| pull模式 | 消费者可以根据自己的消费能力决定拉取的策略 | 没有消息的时候会空轮询(kafka为了避免,有个参数可以阻塞直到新消息到达) |
| push模式 | 及时性高 | 消费能力远低于生产能力时,就会导致客户端消息堆积,甚至服务崩溃。服务端需要维护每次传输状态,以防消息传递失败好进行重试。 |
Kafka的基本概念
- Broker:Kafka集群包含一个或多个服务器,这种服务器被称为broker
- Topic:每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。
- Partition:Partition是物理上的概念,每个Topic包含一个或多个Partition
- Producer:负责发布消息到Kafka broker
- Consumer:消息消费者,向Kafka broker读取消息的客户端
- Consumer Group:每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定group name则属于默认的group)
单机部署结构

集群部署结构
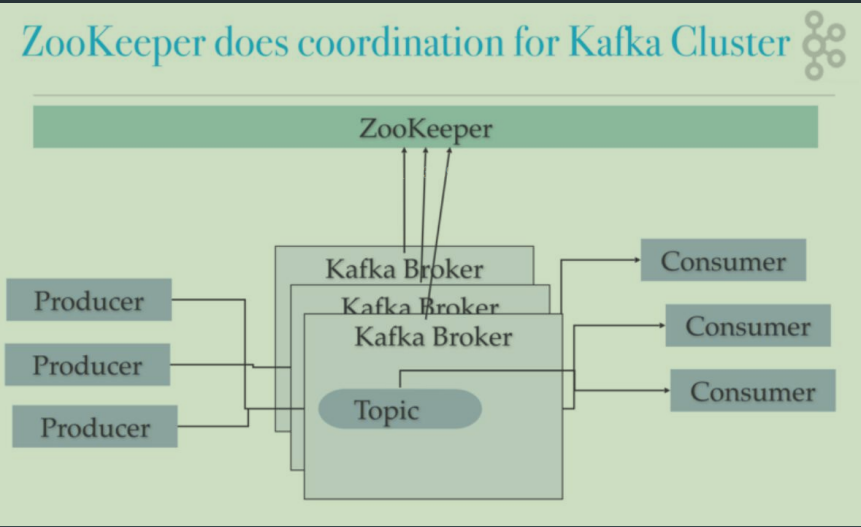
Topic和Partition
一个Topic可以包含一个或者多个Partition。因为一台机器的存储和性能是有限的,多个Partition是为了支持水平扩展和并行处理。
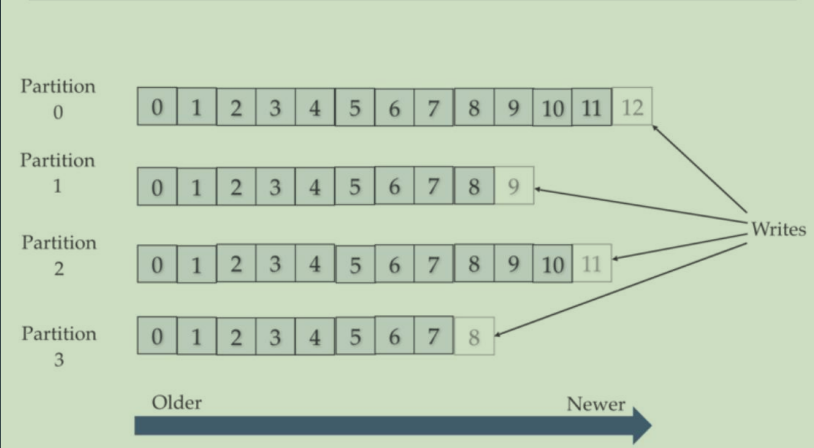
Partition和Replica
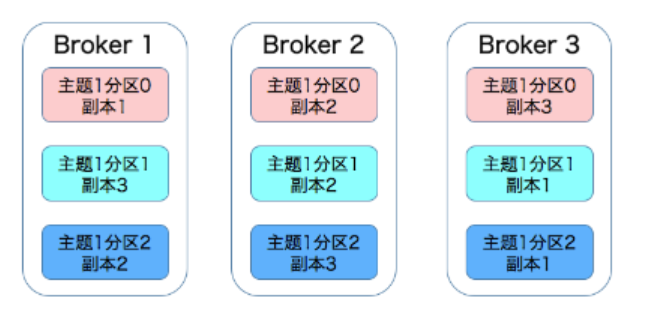
分为多个Partition可以将消息压力分到多个机器上,但是如果其中一个partition数据丢了,那总体数据就少了一块。所以又引入了Replica的概念。
每个partition都可以通过副本因子添加多个副本。这样就算有一台机器故障了,其他机器上也有备份的数据
集群环境下的3分区,3副本:
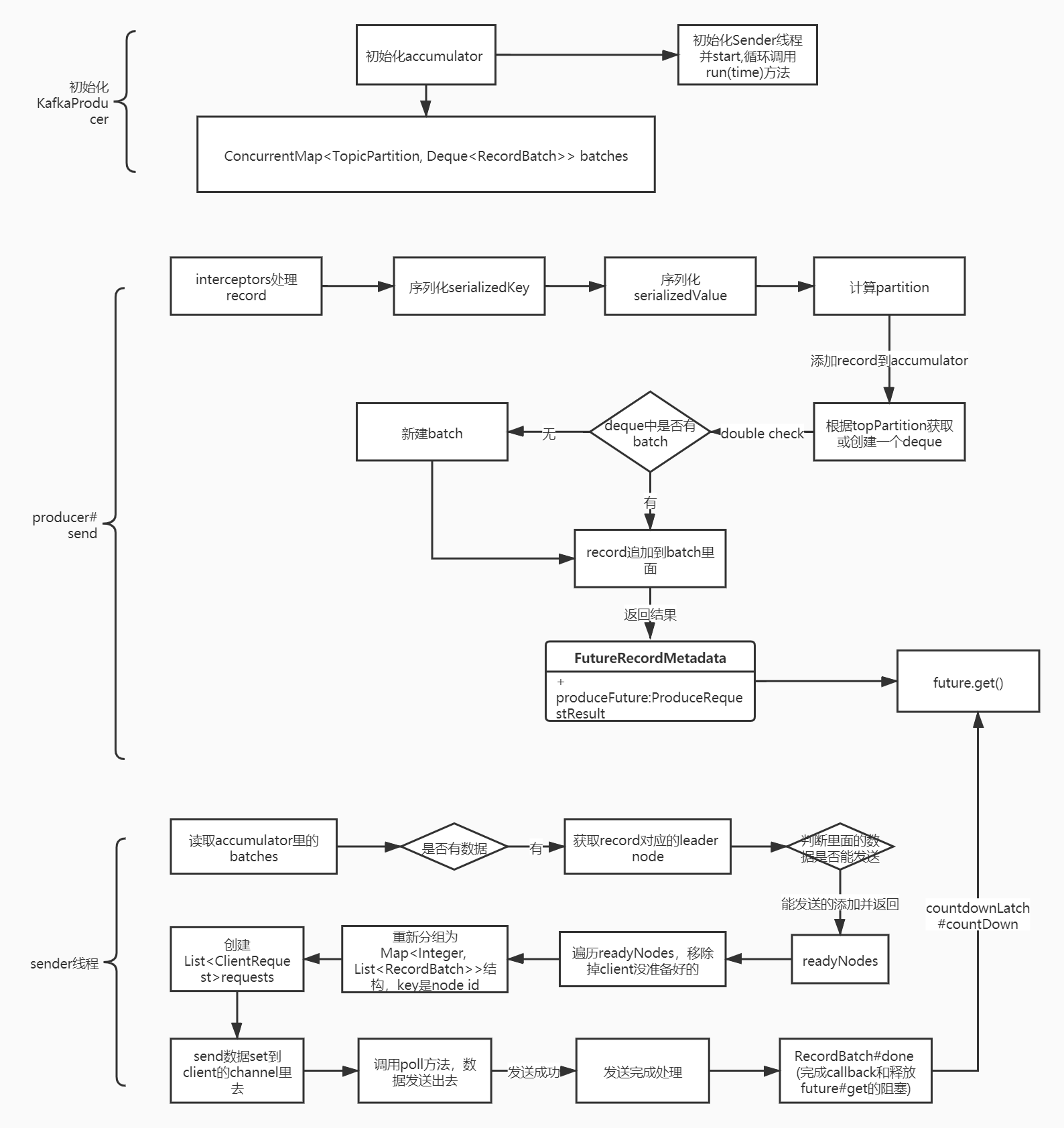
源码图:
二、安装部署
我用的2.7.0版本,下载后解压
注意选择Binary downloads而不是Source download
2. 进入conf/server.properties文件,打开如下配置
listeners=PLAINTEXT://localhost:9092
- 启动zookeeper
自行安装,我用的3.7版本的zookeeper
4. 启动kafka
bin/kafka-server-start.sh config/server.properties
Kafka命令行
查看topic
bin/kafka-topics.sh --zookeeper localhost:2181 --list
创建topic
bin/kafka-topics.sh --zookeeper localhost:2181 --create --topic test1 --partitions 4 --replication-factor 1
查看topic信息
bin/kafka-topics.sh --zookeeper localhost:2181 --describe --topic test1
消费命令
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --from-beginning --topic test1
生产命令
bin/kafka-console-producer.sh --bootstrap-server localhost:9092 --topic test1
简单性能测试:
bin/kafka-producer-perf-test.sh --topic test1 --num-records 100000 --record-size 1000 --throughput 2000 --producer-props bootstrap.servers=localhost:9092
bin/kafka-consumer-perf-test.sh --bootstrap-server localhost:9092 --topic test1 -- fetch-size 1048576 --messages 100000 --threads 1
Java客户端
生产者:
public class SimpleKafkaProducer {
public static void main(String[] args) {
Properties properties=new Properties();
properties.setProperty("key.serializer","org.apache.kafka.common.serialization.StringSerializer");
properties.setProperty("value.serializer","org.apache.kafka.common.serialization.StringSerializer");
properties.setProperty("bootstrap.servers","192.168.157.200:9092");
KafkaProducer producer=new KafkaProducer(properties);
ProducerRecord record=new ProducerRecord("test1","这是一条消息");
producer.send(record);
producer.close();
}
}
消费者
public class SimpleKafkaConsumer {
public static void main(String[] args) {
Properties properties=new Properties();
properties.setProperty("key.deserializer","org.apache.kafka.common.serialization.StringDeserializer");
properties.setProperty("value.deserializer","org.apache.kafka.common.serialization.StringDeserializer");
properties.setProperty("bootstrap.servers","192.168.157.200:9092");
//消费者组
properties.setProperty("group.id","group1");
KafkaConsumer consumer=new KafkaConsumer(properties);
//订阅topic
consumer.subscribe(Arrays.asList("test1"));
while (true){
//拉取数据
ConsumerRecords poll=consumer.poll(100);
((ConsumerRecords) poll).forEach(
data->{
System.out.println(((ConsumerRecord)data).value());
}
);
}
}
}
三、高级特性
生产者特性
生产者-确认模式
- acks=0 :只发送不管有没有写入到broker
- acks=1:只写入到leader就认为成功
- acks=-1/all:要求ISR列表里所有follower都同步过去,才算成功
将acks设置为-1就一定能保证消息不丢吗?
答:不是的。如果partition只有一个副本,也就是光有leader没有follower,那么宕机了消息一样会丢失。所以至少也要设置2个及以上的副本才行。
另外,要提高数据可靠性,设置acks=-1的同时,也要设置min.insync.replicas(最小副本数,默认1)
生产者-同步发送
public void syncSend() throws ExecutionException,InterruptedException {
Properties properties=new Properties();
properties.setProperty("key.serializer","这是一条消息");
Future future = producer.send(record);
//同步发送消息方法1
Object o = future.get();
//同步发送消息方法2
producer.send(record);
producer.flush();
producer.close();
}
生产者-异步发送
public void asyncSend(){
Properties properties=new Properties();
properties.setProperty("key.serializer","192.168.157.200:9092");
//生产者在发送批次之前等待更多消息加入批次的时间
properties.setProperty("linger.ms","1");
properties.setProperty("batch.size","20240");
KafkaProducer producer=new KafkaProducer(properties);
ProducerRecord record=new ProducerRecord("test1","这是一条消息");
//异步发送方法1
producer.send(record);
//异步发送方法2
producer.send(record,((metadata,exception) -> {
if(exception==null){
System.out.println("record="+record.value());
}
}));
}
生产者-顺序保证
同步请求发送+broker只能一个请求一个请求的接
public void sequenceGuarantee(){
Properties properties=new Properties();
properties.setProperty("key.serializer","192.168.157.200:9092");
//生产者在收到服务器响应之前可以发送多少个消息,保证一个一个的发
properties.setProperty("max.in.flight.requests.per.connection","1");
KafkaProducer producer=new KafkaProducer(properties);
ProducerRecord record=new ProducerRecord("test1","这是一条消息");
//同步发送
producer.send(record);
producer.flush();
producer.close();
}
生产者-消息可靠性传递
事务+幂等
这里的事务就是,发送100条消息,如果其中报错了,那么所有的消息都不能被消费者读取。
public static void transaction(){
Properties properties=new Properties();
properties.setProperty("key.serializer","org.apache.kafka.common.serialization.StringSerializer");
//重试次数
properties.setProperty("retries","3");
properties.setProperty("bootstrap.servers","192.168.157.200:9092");
//生产者发送消息幂等,此时会默认把acks设置为all
properties.setProperty("enable.idempotence","true");
//事务id
properties.setProperty("transactional.id","tx0001");
ProducerRecord record=new ProducerRecord("test1","这是一条消息");
KafkaProducer producer=new KafkaProducer(properties);
try {
producer.initTransactions();
producer.beginTransaction();
for (int i = 0; i < 100; i++) {
producer.send(record,(recordMetadata,e) -> {
if(e!=null){
producer.abortTransaction();
throw new KafkaException("send error"+e.getMessage());
}
});
}
producer.commitTransaction();
} catch (ProducerFencedException e) {
producer.abortTransaction();
e.printStackTrace();
}
producer.close();
}
消费者特性
消费者-消费者组

每个消费者组都记录了一个patition的offset,一个partition只能被一个消费者组消费。
如图,一个Topic有4个partition,分别在两个broker上。
对于消费者组A来说,他有两个消费者,所以他里面一个消费者消费2个partition。而对于消费者组B,他有4个消费者,所以一个消费者消费1个partition.

消费者-offset同步提交
void commitSyncReceive() throws InterruptedException {
Properties props = new Properties();
props.put("bootstrap.servers","49.234.77.60:9092");
props.put("group.id","group_id");
//关闭自动提交
props.put("enable.auto.commit","false");
props.put("auto.commit.interval.ms","1000");
props.put("session.timeout.ms","30000");
props.put("max.poll.records",1000);
props.put("auto.offset.reset","earliest");
props.put("key.deserializer",StringDeserializer.class.getName());
props.put("value.deserializer",StringDeserializer.class.getName());
KafkaConsumer<String,String> consumer = new KafkaConsumer<String,String>(props);
consumer.subscribe(Arrays.asList(TOPIC));
while (true){
ConsumerRecords<String,String> msgList=consumer.poll(1000);
for (ConsumerRecord<String,String> record:msgList){
System.out.printf("offset = %d,key = %s,value = %s%n",record.offset(),record.key(),record.value());
}
//同步提交,当前线程会阻塞直到 offset 提交成功
consumer.commitSync();
}
}
消费者-异步提交
void commitAsyncReceive() throws InterruptedException {
Properties props = new Properties();
props.put("bootstrap.servers","group_id");
props.put("enable.auto.commit",record.value());
}
//异步提交
consumer.commitAsync(new OffsetCommitCallback() {
@Override
public void onComplete(Map<TopicPartition,OffsetAndMetadata> map,Exception e) {
if(e!=null){
System.err.println("commit failed for "+map);
}
}
});
}
}
消费者-自定义保存offset
void commitCustomSaveOffest() throws InterruptedException {
Properties props = new Properties();
props.put("bootstrap.servers",String>(props);
consumer.subscribe(Arrays.asList(TOPIC),new ConsumerRebalanceListener() {
//调用时机是Consumer停止拉取数据后,Rebalance开始之前,我们可以手动提交offset
@Override
public void onPartitionsRevoked(Collection<TopicPartition> collection) {
}
//调用时机是Rebalance之后,Consumer开始拉取数据之前,我们可以在此方法调整offset
@Override
public void onPartitionsAssigned(Collection<TopicPartition> collection) {
}
});
while (true){
ConsumerRecords<String,record.value());
}
consumer.commitAsync(new OffsetCommitCallback() {
@Override
public void onComplete(Map<TopicPartition,Exception e) {
if(e!=null){
System.err.println("commit failed for "+map);
}
}
});
}
}
四、SpringBoot整合Kafka
- 引入依赖
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
- 配置
#kafka
spring.kafka.bootstrap-servers=192.168.157.200:9092
# 发生错误后,消息重发的次数
spring.kafka.producer.retries=0
spring.kafka.producer.batch-size=16384
# 设置生产者内存缓冲区的大小。
spring.kafka.producer.buffer-memory=33554432
spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.StringSerializer
spring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer
spring.kafka.producer.acks=1
#消费者
#自动提交的时间间隔
spring.kafka.consumer.auto-commit-interval=1S
# 该属性指定了消费者在读取一个没有偏移量的分区或者偏移量无效的情况下该作何处理:
# latest(默认值)在偏移量无效的情况下,消费者将从最新的记录开始读取数据(在消费者启动之后生成的记录)
# earliest :在偏移量无效的情况下,消费者将从起始位置读取分区的记录
spring.kafka.consumer.auto-offset-reset=earliest
spring.kafka.consumer.enable-auto-commit=false
spring.kafka.consumer.key-deserializer=org.apache.kafka.common.serialization.StringDeserializer
spring.kafka.consumer.value-deserializer=org.apache.kafka.common.serialization.StringDeserializer
# 在侦听器容器中运行的线程数。
spring.kafka.listener.concurrency=5
#listner负责ack,每调用一次,就立即commit
spring.kafka.listener.ack-mode=manual_immediate
spring.kafka.listener.missing-topics-fatal=false
- producer
@Component
public class MyKafkaProducer {
@Autowired
private KafkaTemplate<String,Object> kafkaTemplate;
public void send(String topic,Object object){
ListenableFuture<SendResult<String,Object>> future = kafkaTemplate.send(topic,object);
future.addCallback(new ListenableFutureCallback<SendResult<String,Object>>() {
@Override
public void onFailure(Throwable ex) {
System.out.println("发送消息失败"+ex.getMessage());
}
@Override
public void onSuccess(SendResult<String,Object> result) {
System.out.println("发送消息成功"+result);
}
});
}
- consumer
@Component
public class MyKafkaConsumer {
@KafkaListener(topics = "test1",groupId = "group_test")
public void consumer(ConsumerRecord<?,?> record,Acknowledgment ack,@Header(KafkaHeaders.RECEIVED_TOPIC) String topic){
Optional message = Optional.ofNullable(record.value());
if (message.isPresent()) {
Object msg = message.get();
System.out.println("group_test 消费了: Topic:" + topic + ",Message:" + msg);
ack.acknowledge();
}
}
@KafkaListener(topics = "test1",groupId = "group_test2")
public void consumer2(ConsumerRecord<?,@Header(KafkaHeaders.RECEIVED_TOPIC) String topic){
Optional message = Optional.ofNullable(record.value());
if (message.isPresent()) {
Object msg = message.get();
System.out.println("group_test2 消费了: Topic:" + topic + ",Message:" + msg);
ack.acknowledge();
}
}
}
- 测试

原文地址:https://www.cnblogs.com/javammc
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。