
1、Scrapy简介
Scrapy是1个为了爬取网站数据,提取结构性数据而编写的利用框架。 可以利用在包括数据发掘,信息处理或存储历史数据等1系列的程序中。
其最初是为了 页面抓取 (更确切来讲,网络抓取 )所设计的, 也能够利用在获得API所返回的数据(例如 Amazon Associates Web Services ) 或通用的网络爬虫。
其最初是为了 页面抓取 (更确切来讲,网络抓取 )所设计的, 也能够利用在获得API所返回的数据(例如 Amazon Associates Web Services ) 或通用的网络爬虫。
Scrapy官网文档 -- 戳我
本来我是基于Python3.5学习爬虫的,但是Python3.x不支持Scrapy框架。即使不支持,也不能就此放弃这个强大的框架,因而转战Ubuntu,搭建Python2.7环境,安装Scrapy,开始学习~~~
2、环境搭建
【1】系统Ubuntu 15
【2】Python版本 -- 2.7 & 3.4 , 安装pip工具
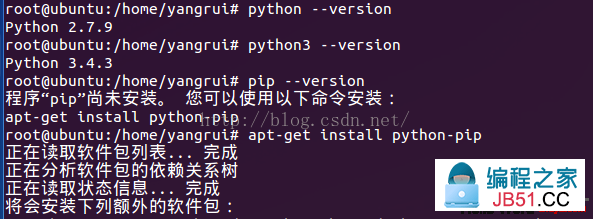
我的Ubuntu系统上安装了Python2.7和Python3.4两个版本,但是默许配置仍然是2.7。
【3】安装Scrapy
使用命令(apt-get install python-scrapy)或(pip install scrapy)安装:
验证安装完成:
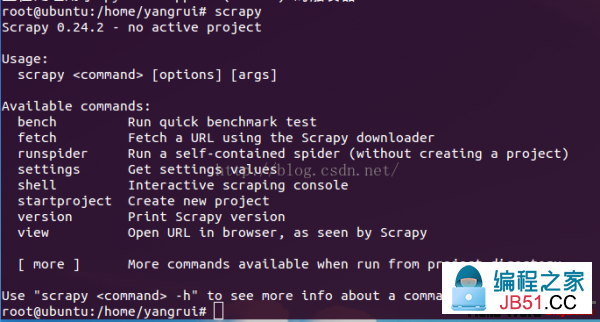
出现上图内容,说明正确安装Scrapy。其实Scrapy框架依赖setuptools,lxml,和OpenSSL软件,但是Ubuntu中Python2.7已内置安装,所以,1个简单的命令便可完成Scrapy框架的配置,非常简便。
至此,Scrapy已配置完成,下面开始我们的第1个Scrapy爬虫项目吧。
3、第1个Scrapy爬虫实例
此实例源于官网(Scrapy入门教程)。
3.1 开发步骤
接下来以 Open Directory Project(dmoz) (dmoz) 为例来说述爬取。
- 创建1个Scrapy项目
- 定义提取的Item
- 编写爬取网站的 spider 并提取 Item
- 编写 Item Pipeline 来存储提取到的Item(即数据)
3.2 创建项目
在开始爬取之前,您必须创建1个新的Scrapy项目。 进入您打算存储代码的目录中,运行以下命令:scrapy startproject tutorial
该命令将会创建包括以下内容的 tutorial 目录:tutorial/
scrapy.cfg
tutorial/
__init__.py
items.py
pipelines.py
settings.py
spiders/
__init__.py
...
这些文件分别是:- scrapy.cfg: 项目的配置文件.
- tutorial/: 该项目的python模块。以后您将在此加入代码.
- tutorial/items.py: 项目中的item文件.
- tutorial/pipelines.py: 项目中的pipelines文件.
- tutorial/settings.py: 项目的设置文件.
- tutorial/spiders/: 放置spider代码的目录.
3.3 定义Item
Item 是保存爬取到的数据的容器;其使用方法和python字典类似, 并且提供了额外保护机制来避免拼写毛病致使的未定义字段毛病。item可以用scrapy.item.Item类来创建,并且用scrapy.item.Field对象来定义属性(可以理解成类似于ORM的映照关系)。类似在ORM中做的1样,您可以通过创建1个 scrapy.Item 类, 并且定义类型为 scrapy.Field 的类属性来定义1个Item。
首先根据需要从dmoz.org获得到的数据对item进行建模。 我们需要从dmoz中获得名字,url,和网站的描写。 对此,在item中定义相应的字段。编辑 tutorial 目录中的 items.py 文件,添加类DmozItem:
import scrapy
class DmozItem(scrapy.Item):
title = scrapy.Field()
link = scrapy.Field()
desc = scrapy.Field()
3.4 编写第1个爬虫
Spider是用户编写用于从单个网站(或1些网站)爬取数据的类。
其包括了1个用于下载的初始URL,如何跟进网页中的链接和如何分析页面中的内容, 提取生成 item 的方法。
为了创建1个Spider,您必须继承 scrapy.Spider 类, 且定义以下3个属性:
其包括了1个用于下载的初始URL,如何跟进网页中的链接和如何分析页面中的内容, 提取生成 item 的方法。
为了创建1个Spider,您必须继承 scrapy.Spider 类, 且定义以下3个属性:
- name: 用于区分Spider。 该名字必须是唯1的,您不可以为不同的Spider设定相同的名字。
- start_urls: 包括了Spider在启动时进行爬取的url列表。 因此,第1个被获得到的页面将是其中之1。 后续的URL则从初始的URL获得到的数据中提取。
- parse() 是spider的1个方法。 被调用时,每一个初始URL完成下载后生成的 Response 对象将会作为唯1的参数传递给该函数。 该方法负责解析返回的数据(response data),提取数据(生成item)和生成需要进1步处理的URL的 Request 对象。
import scrapy
class DmozSpider(scrapy.spiders.Spider):
name = dmoz
allowed_domains = [dmoz.org]
start_urls = [
http://www.dmoz.org/Computers/Programming/Languages/Python/Books/,http://www.dmoz.org/Computers/Programming/Languages/Python/Resources/
]
def parse(self,response):
filename = response.url.split(/)[⑵]
with open(filename,'wb') as f:
f.write(response.body)
3.4.1 爬取
在项目的根目录输入命令(scrapy crawl dmoz)运行我们的爬虫,得到结果: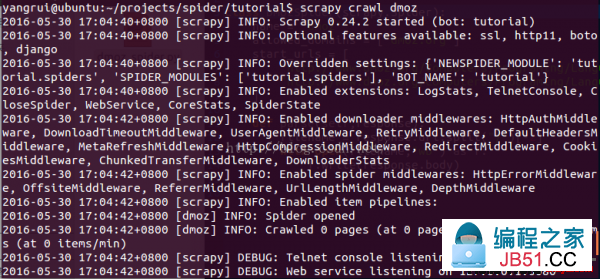
...中间省略
最后1句INFO: Closing spider (finished)表明爬虫已成功运行并且自行关闭了。

最后1句INFO: Closing spider (finished)表明爬虫已成功运行并且自行关闭了。
查看包括 [dmoz] 的输出,可以看到输出的log中包括定义在 start_urls 的初始URL,并且与spider中是逐一对应的。在log中可以看到其没有指向其他页面( (referer:None) )。
那末,刚才产生了甚么?
首先,Scrapy为Spider的 start_urls 属性中的每一个URL创建了 scrapy.Request 对象,并将 parse 方法作为回调函数(callback)赋值给了Request。
然后,Request对象经过调度,履行生成 scrapy.http.Response 对象并送回给spider parse() 方法。
首先,Scrapy为Spider的 start_urls 属性中的每一个URL创建了 scrapy.Request 对象,并将 parse 方法作为回调函数(callback)赋值给了Request。
然后,Request对象经过调度,履行生成 scrapy.http.Response 对象并送回给spider parse() 方法。
3.4.2 使用XPath
Selectors选择器简介:
从网页中提取数据有很多方法。Scrapy使用了1种基于 XPath 和 CSS 表达式机制: Scrapy Selectors 。 关于selector和其他提取机制的信息请参考 Selector文档 。
这里给出XPath表达式的例子及对应的含义:
从网页中提取数据有很多方法。Scrapy使用了1种基于 XPath 和 CSS 表达式机制: Scrapy Selectors 。 关于selector和其他提取机制的信息请参考 Selector文档 。
这里给出XPath表达式的例子及对应的含义:
- /html/head/title: 选择HTML文档中 <head> 标签内的 <title> 元素
- /html/head/title/text(): 选择上面提到的 <title> 元素的文字
- //td: 选择所有的 <td> 元素
- //div[@class=mine]: 选择所有具有 class=mine 属性的 div 元素
Selector有4个基本的方法:
- xpath(): 传入xpath表达式,返回该表达式所对应的所有节点的selector list列表 。
- css(): 传入CSS表达式,返回该表达式所对应的所有节点的selector list列表。
- extract(): 序列化该节点为unicode字符串并返回list。
- re(): 根据传入的正则表达式对数据进行提取,返回unicode字符串list列表。
首先,先查看1下我们需要爬取的网页http://www.dmoz.org/Computers/Programming/Languages/Python/Books/

为了介绍Selector的使用方法,接下来我们将要使用内置的 Scrapy shell 。Scrapy Shell需要您预装好IPython(1个扩大的Python终端)。进入项目的根目录,履行以下命令来启动shell:
scrapy shell http://www.dmoz.org/Computers/Programming/Languages/Python/Books/

当shell载入后,您将得到1个包括response数据的本地 response 变量。输入 response.body 将输出response的包体, 输出 response.headers 可以看到response的包头。
更加重要的是,当输入 response.selector 时, 您将获得到1个可以用于查询返回数据的selector(选择器), 和映照到 response.selector.xpath() 、 response.selector.css() 的 快捷方法(shortcut): response.xpath() 和 response.css() 。
同时,shell根据response提早初始化了变量 sel 。该selector根据response的类型自动选择最适合的分析规则(XML vs HTML)。
让我们来试试:
更加重要的是,当输入 response.selector 时, 您将获得到1个可以用于查询返回数据的selector(选择器), 和映照到 response.selector.xpath() 、 response.selector.css() 的 快捷方法(shortcut): response.xpath() 和 response.css() 。
同时,shell根据response提早初始化了变量 sel 。该selector根据response的类型自动选择最适合的分析规则(XML vs HTML)。
让我们来试试:

xpath路径表达式(说明):
表达式 描写
nodename 选取此节点的所有子节点。
/ 从根节点选取。
// 从匹配选择确当前节点选择文档中的节点,而不斟酌它们的位置。
. 选取当前节点。
.. 选取当前节点的父节点。
@ 选取属性。
表达式 描写
nodename 选取此节点的所有子节点。
/ 从根节点选取。
// 从匹配选择确当前节点选择文档中的节点,而不斟酌它们的位置。
. 选取当前节点。
.. 选取当前节点的父节点。
@ 选取属性。
3.4.3 查看网页源代码,提取有用数据

在查看了网页的源码后,您会发现网站的信息是被包括在 第2个 <ul> 元素中。
我们可以通过这段代码选择该页面中网站列表里所有 <li> 元素:
sel.xpath('//ul/li')
网站的描写:
sel.xpath('//ul/li/text()').extract()
网站的标题:
sel.xpath('//ul/li/a/text()').extract()
和网站的链接:
sel.xpath('//ul/li/a/@href').extract()
之条件到过,每一个 .xpath() 调用返回selector组成的list,因此我们可以拼接更多的 .xpath() 来进1步获得某个节点。我们将在下边使用这样的特性:
我们可以通过这段代码选择该页面中网站列表里所有 <li> 元素:
sel.xpath('//ul/li')
网站的描写:
sel.xpath('//ul/li/text()').extract()
网站的标题:
sel.xpath('//ul/li/a/text()').extract()
和网站的链接:
sel.xpath('//ul/li/a/@href').extract()
之条件到过,每一个 .xpath() 调用返回selector组成的list,因此我们可以拼接更多的 .xpath() 来进1步获得某个节点。我们将在下边使用这样的特性:
for sel in response.xpath('//ul/li'):
title = sel.xpath('a/text()').extract()
link = sel.xpath('a/@href').extract()
desc = sel.xpath('text()').extract()
print title,link,desc
3.4.4 修改dmoz_spider.py中DmozSpider类的代码:
# -*- coding: UTF⑻ -*-
import scrapy,sys
from scrapy.spider import Spider
from scrapy.selector import Selector
from tutorial.items import DmozItem
#设置编码格式
reload(sys)
sys.setdefaultencoding('gbk')
class DmozSpider(Spider):
name = dmoz
allowed_domains = [dmoz.org]
start_urls = [
http://www.dmoz.org/Computers/Programming/Languages/Python/Books/,http://www.dmoz.org/Computers/Programming/Languages/Python/Resources/
]
def parse(self,response):
The lines below is a spider contract. For more info see:
http://doc.scrapy.org/en/latest/topics/contracts.html
@url http://www.dmoz.org/Computers/Programming/Languages/Python/Resources/
@scrapes name
sel = Selector(response)
sites = sel.xpath('//ul/li')
for site in sites:
title = site.xpath('a/text()').extract()
link = site.xpath('a/@href').extract()
disc = site.xpath('text()').extract()
print(title= +str(title)+\tlink= +str(link)+\tdisc= +str(disc)+\n)
说明:
- 代码中的中文注释,首句添加# -*- coding: UTF⑻ -*- 避免出现编码毛病
- 若有写文件操作添加代码sys.setdefaultencoding('gbk'),设置编码格式
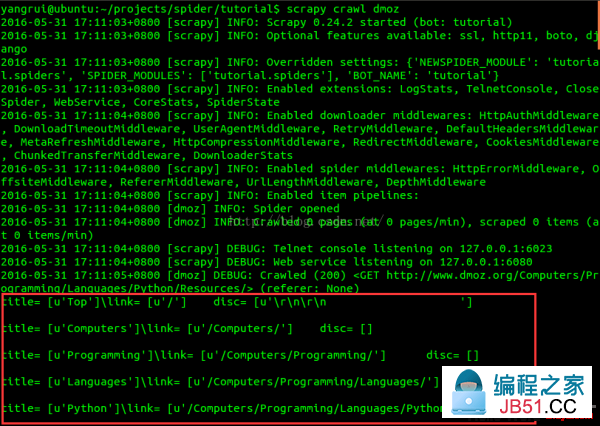
...省略
对照网站内容,我们发现网页顶层的Top和Python部份也被抓取出来,我们把这部份过滤掉。根据网页源代码发现,我们所要提取的目标信息是从 <ul class=directory-url...开始的。再次修改代码:
sites = sel.xpath('//ul[@class=directory-url]/li')
重新运行会发现此时已将Top和Python部份过滤掉了。
3.5 使用Item提取,并保存至dmoz.json
3.5.1 使用Item
Item 对象是自定义的python字典。 您可使用标准的字典语法来获得到其每一个字段的值。(字段即是我们之前用Field赋值的属性):
>>> item = DmozItem()
>>> item['title'] = 'Example title'
>>> item['title']
'Example title'
1般来讲,Spider将会将爬取到的数据以 Item 对象返回。所以为了将爬取的数据返回,修改dmoz_spider.py中DmozSpider类的代码:# -*- coding: UTF⑻ -*-
import scrapy
from scrapy.spider import Spider
from scrapy.selector import Selector
from tutorial.items import DmozItem
#设置编码格式
reload(sys)
sys.setdefaultencoding('gbk')
class DmozSpider(Spider):
name = dmoz
allowed_domains = [dmoz.org]
start_urls = [
http://www.dmoz.org/Computers/Programming/Languages/Python/Books/,response):
The lines below is a spider contract. For more info see:
http://doc.scrapy.org/en/latest/topics/contracts.html
@url http://www.dmoz.org/Computers/Programming/Languages/Python/Resources/
@scrapes name
sel = Selector(response)
sites = sel.xpath('//ul[@class=directory-url]/li')
items = []
for site in sites:
item = DmozItem()
item['title'] = site.xpath('a/text()').extract()
item['link'] = site.xpath('a/@href').extract()
item['desc'] = site.xpath('text()').re('-\s[^\n]*\\r')
items.append(item)
return items
3.5.2 运行并保存为json文件
保存信息的最简单的方法是通过Feed exports,主要有4种:JSON,JSON lines,CSV,XML。
我们将结果用最经常使用的JSON导出,命令以下:
scrapy crawl dmoz -o items.json -t json
-o 后面是导出文件名,-t 后面是导出类型。
scrapy crawl dmoz -o items.json -t json
-o 后面是导出文件名,-t 后面是导出类型。
运行结果:

查看items.json文件:

3.6 使用Pipeline输出结果
打开tutuorial/tutorial/pipelines.py文件,添加自定义JsonWithEncodingTutorialPipeline类代码:
# -*- coding: utf⑻ -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
import scrapy
from scrapy import signals
import json,codecs
class TutorialPipeline(object):
def process_item(self,item,spider):
return item
class JsonWithEncodingTutorialPipeline(object):
def __init__(self):
self.file = codecs.open('dmoz.json','w',encoding='utf⑻')
def process_item(self,spider):
line = json.dumps(dict(item),ensure_ascii=False)+'\n\n'
self.file.write(line)
return item
def spider_closed(self,spider):
self.file.close()
打开tutuorial/tutorial/settings.py文件,在末尾追加部份代码:# -*- coding: utf⑻ -*-
# Scrapy settings for tutorial project
#
# For simplicity,this file contains only the most important settings by
# default. All the other settings are documented here:
#
# http://doc.scrapy.org/en/latest/topics/settings.html
#
BOT_NAME = 'tutorial'
SPIDER_MODULES = ['tutorial.spiders']
NEWSPIDER_MODULE = 'tutorial.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'tutorial (+http://www.yourdomain.com)'
ITEM_PIPELINES = {
'tutorial.pipelines.JsonWithEncodingTutorialPipeline': 300,}
LOG_LEVEL = 'INFO'

我们可以发现,在根目录下多了1个dmoz.json文件,这就是我们利用pipeline管道自动生成的结果文件,可以查看其内容与上节的结果完全相同。
完全代码见:GitHub代码链接(请猛戳~~~)