
HBASE基础
1. HBase简介
HBase是一个高可靠、高性能、面向列的,主要用于海量结构化和半结构化数据存储的分布式key-value存储系统。
它基于Google Bigtable开源实现,但二者有明显的区别:Google Bigtable基于GFS存储,通过MAPREDUCE处理存储的数据,通过chubby处理协同服务;而HBase底层存储基于hdfs,可以利用MapReduce、Spark等计算引擎处理其存储的数据,通过Zookeeper作为处理HBase集群协同服务。
2. HBase表结构
HBase以表的形式将数据最终存储的hdfs上,建表时无需指定表中字段,只需指定若干个列簇即可。插入数据时,指定任意多个列到指定的列簇中。通过行键、列簇、列和时间戳可以对数据进行快速定位。
2.1 行键(row key)
HBase基于row key唯一标识一行数据,是用来检索数据的主键。HBase通过对row key进行字典排序从而对表中数据进行排序。基于这个特性,在设计row key时建议将经常一起读取的数据存储在一起。
2.2 列簇(column family)
HBase中的表可以有若干个列簇,一个列簇下面可以有多个列,必须在建表时指定列簇,但不需要指定列。
一个列族的所有列存储在同一个底层文存储件中。
HBase对访问控制、磁盘和内存的使用统计都是在列族层面进行的。列族越多,在取一行数据时所要参与IO、搜寻的文件就越多。所以,如果没有必要,不要设置太多的列族,也不要修改的太频繁。并且将经常一起查询的列放到一个列簇中,减少文件的IO、寻址时间,提升访问性能。
2.3 列(qualifier)
列可以是任意的字节数组,都唯一属于一个特定列簇,它也是按照字典顺序排序的。
列名都以列簇为前缀,常见引用列格式:column family:qualifier,如city:beijing、city:shanghai都属于city这个列簇。
列值没有类型和长度限定。
2.4 Cell
通过{row key,column family:qualifier,version}可以唯一确定的存贮单元,cell中的数据全部以字节码形式存贮。
2.5 时间戳(timestamp)
每个cell都可以保存同一份数据的不同版本,不同版本的数据按照时间倒序排序,读取时优先读取最新值,并通过时间戳来索引。
时间戳的类型是64位整型,可以由客户端显式赋值或者由HBase在写入数据时自动赋值(此时时间戳是精确到毫秒的当前系统时间),可以通过显式生成唯一性的时间戳来避免数据版本冲突。
每个cell中,为了避免数据存在过多版本造成的的存贮、索引等管负担,HBase提供了两种数据版本回收方式(可以针对每个列簇进行设置):
1)保存数据的最新n个版本
2)通过设置数据的生命周期保存最近一段时间内的版本
将以上特点综合在一起,就有了如下数据存取模式:SortedMap<RowKey,List<SortedMap<Column,List<Value,Timestamp>>>>第一个SortedMap代表那个表,包含一个列族集合List(多个列族)。列族中包含了另一个SortedMap存储列和相应的值。
HBASE系统架构
下图展现了HBase集群、内部存储中的主要角色,以及存储过程中与hdfs的交互:
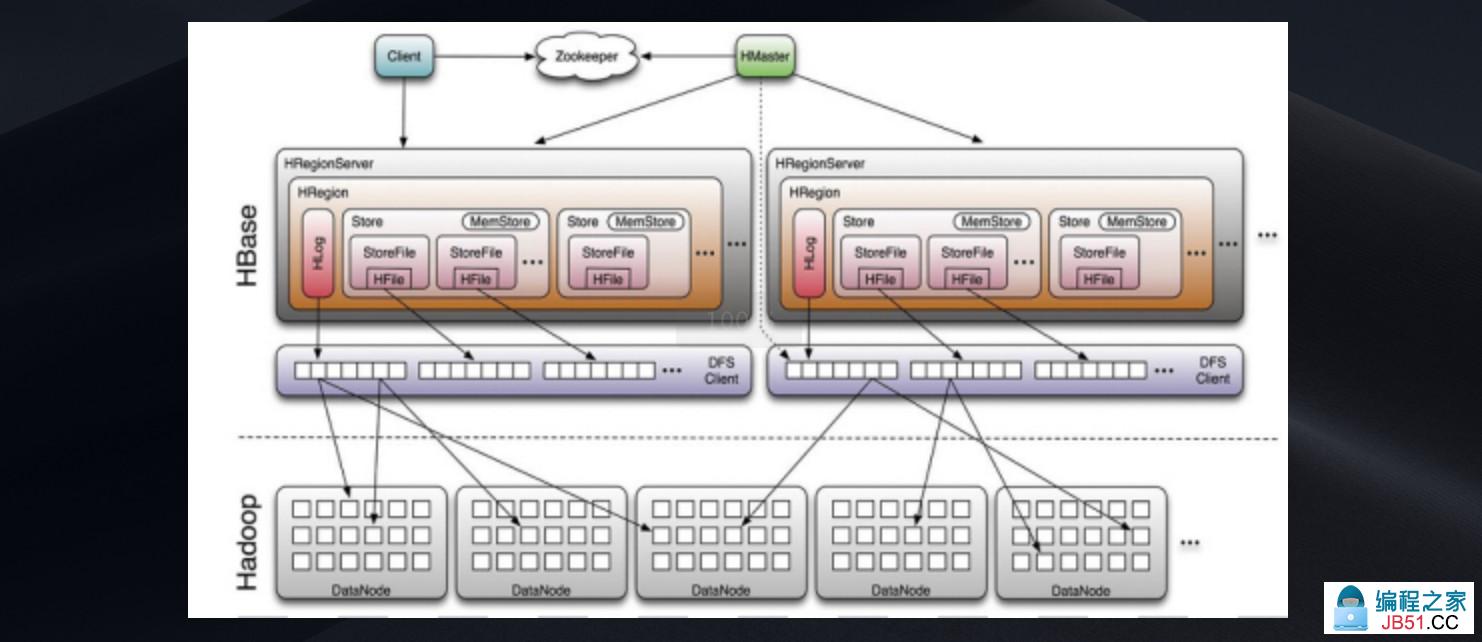
下面介绍一下HBase集群中主要角色的作用:
HMaster
HBase集群的主节点,可以配置多个,用来实现HA,主要作用:
1. 为RegionServer分配region
2. 负责RegionServer的负载均衡
3. 发现失效的RegionServer,重新分配它负责的region
4. hdfs上的垃圾文件回收(标记为删除的且经过major compact的文件)
5. 处理schema更新请求
RegionServer(以下简称RS)
HBase集群的从节点,负责数据存储,主要作用:
1. RS维护HMaster分配给它的region,处理对这些region的IO请求
2. RS负责切分在运行过程中变得过大的region
Zookeeper(以下简称ZK)
1. 通过选举,保证任何时候,集群中只有一个active master(HMaster与RS启动时会向ZK注册)
2. 存贮所有region的寻址入口,如-ROOT-表在哪台服务器上
3. 实时监控RS的状态,将RS的上下线信息通知HMaster
4. 存储HBase的元数据,如有哪些table,每个table有哪些column family
client包含访问HBase的接口,维护着一些缓存来加速对HBase的访问,比如region的位置信息。
client在访问HBase上数据时不需要HMaster参与(寻址访问ZK和RS,数据读写访问RS),HMaster主要维护着table和region的元数据信息,负载很低。
HBASE数据存储
通过之前的HBase系统架构图,可以看出:
1. HBase中table在行的方向上分割为多个region,它是HBase负载均衡的最小单元,可以分布在不同的RegionServer上,但是一个region不能拆分到多个RS上
2. region不是物理存储的最小单元region由一个或者多个store组成,每个store保存一个column family。每个store由一个memstore和多个storefile组成,storefile由hfile组成是对hfile的轻量级封装,存储在hdfs上。
3. region按大小分割,默认10G,每个表一开始只有一个region,随着表中数据不断增加,region不断增大,当增大到一个阀值时,region就会划分为两个新的region。
当表中的数据不断增多,就会有越来越多的region,这些region由HMaster分配给相应的RS,实现负载均衡。
HBase底层存储基于hdfs,但对于为null的列并不占据存储空间,并且支持随机读写,主要通过以下机制完成:
1. HBase底层存储结构依赖了LSM树(Log-structured merge tree)
2. 数据写入时先写入HLog,然后写入memstore,当memstore存储的数据达到阈值,RS启动flush cache将memstore中的数据刷写到storefile
3. 客户端检索数据时,先在client缓存中找,缓存中找不到则到memstore找,还找不到才会从storefile中查找
4. storefile底层以hfile的形式存储到hdfs上,当storefile达到一定阈值会进行合并
5. minor合并和major合并小文件,删弃做过删除标记的数据
WAL log
即预写日志,该机制用于数据的容错和恢复,每次更新都会先写入日志,只有写入成功才会通知客户端操作成功,然后RS按需自由批量处理和聚合内存中的数据。
每个HRegionServer中都有一个HLog对象,它负责记录数据的所有变更,被同一个RS中的所有region共享。
HLog是一个实现预写日志的类,在每次用户操作写入memstore之前,会先写一份数据到HLog文件中,HLog文件定期会滚动出新的,并删除已经持久化到storefile中的数据的文件。
当RS意外终止后,HMaster会通过ZK感知到,HMaster首先会处理遗留的HLog文件,将其中不同region的日志数据进行拆分,分别放到相应region的目录下,然后再将失效的region重新分配,领取到这些region的HRegionServer在加载region的过程中,如果发现有历史HLog需要处理,会"重放日志"中的数据到memstore中,然后flush到storefile,完成数据恢复。
HLog文件就是一个普通的Hadoop Sequence File。
HBASE中LSM树的应用
1. 输入数据首先存储在日志文件 [文件内数据完全有序,按键排序]
2. 然后当日志文件修改时,对应更新会被先保存在内存中来加速查询
3. 数据经过多次修改,且内存空间达到设定阈值,LSM树将有序的"键记录"flush到磁盘,同时创建一个新的数据存储文件。[内存中的数据由于已经被持久化了,就会被丢弃]
4. 查询时先从内存中查找数据,然后再查找磁盘上的文件
5. 删除只是“逻辑删除”即将要删除的数据或者过期数据等做删除标记,查找时会跳过这些做了删除标记的数据
6. 多次数据刷写之后会创建许多数据存储文件,后台线程会自动将小文件合并成大文件。合并过程是重写一遍数据,major compaction会略过做了删除标记的数据[丢弃]
7. LSM树利用存储的连续传输能力,以磁盘传输速率工作并能较好地扩展以处理大量数据。使用日志文件和内存存储将随机写转换成顺序写
8. LSM树对磁盘顺序读取做了优化
9. LSM树的读和写是独立的
HBASE寻址机制
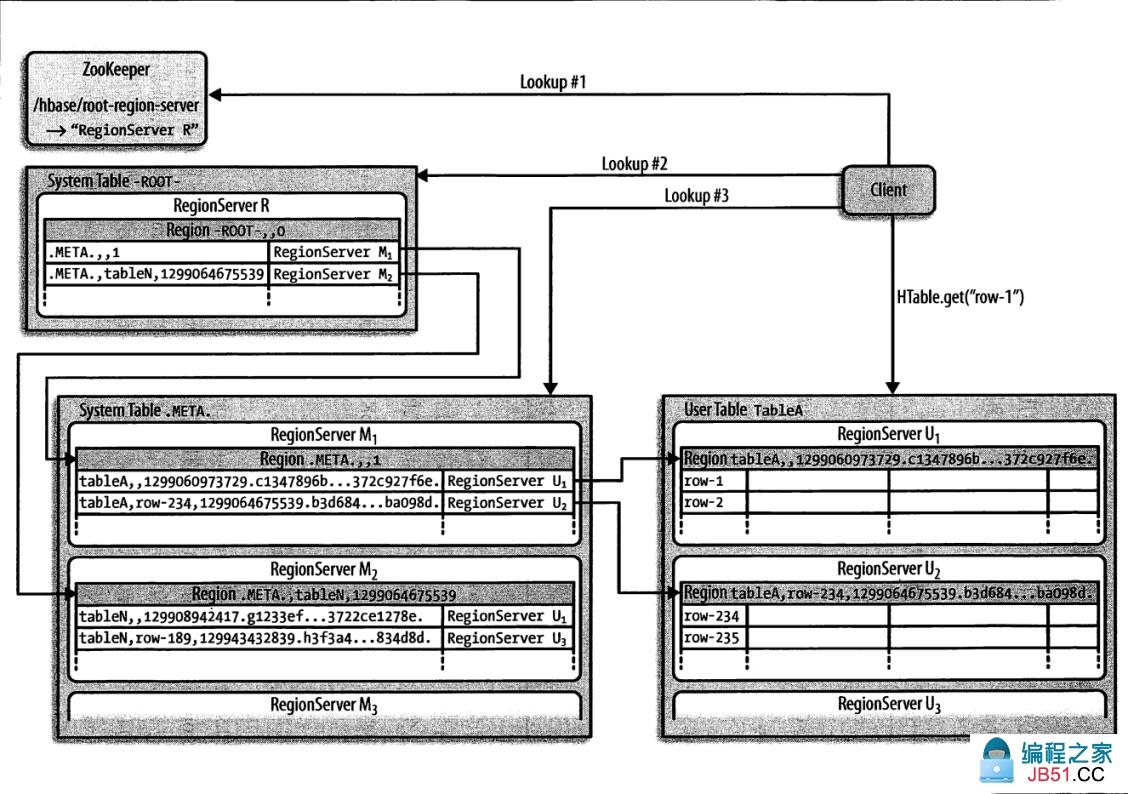
HBase提供了两张特殊的目录表-ROOT-和META表,-ROOT-表用来查询所有的META表中region位置。HBase设计中只有一个root region即root region从不进行切分,从而保证类似于B+树结构的三层查找结构:
第1层:zookeeper中包含root region位置信息的节点,如-ROOT-表在哪台regionserver上
第2层:从-ROOT-表中查找对应的meta region位置即.META.表所在位置
第3层:从META表中查找用户表对应region位置
目录表中的行健由region表名、起始行和ID(通常是以毫秒表示的当前时间)连接而成。HBase0.90.0版本开始,主键上有另一个散列值附加在后面,目前这个附加部分只用在用户表的region中。
注意:
1. root region永远不会被split,保证了最多需要三次跳转,就能定位到任意region
2. META表每行保存一个region的位置信息,row key采用表名+表的最后一行编码而成
3. 为了加快访问,META表的全部region都保存在内存中
4. client会将查询过的位置信息保存缓存起来,缓存不会主动失效,因此如果client上的缓存全部失效,则需要进行最多6次网络来回,才能定位到正确的region(其中三次用来发现缓存失效,另外三次用来获取位置信息)
关于寻址的几个问题:
1. 既然ZK中能保存-ROOT-信息,那么为什么不把META信息直接保存在ZK中,而需要通过-ROOT-表来定位?
ZK不适合保存大量数据,而META表主要是保存region和RS的映射信息,region的数量没有具体约束,只要在内存允许的范围内,region数量可以有很多,如果保存在ZK中,ZK的压力会很大。
所以,通过一个-ROOT-表来转存到regionserver中相比直接保存在ZK中,也就多了一层-ROOT-表的查询(类似于一个索引表),对性能来说影响不大。
2. client查找到目标地址后,下一次请求还需要走ZK —> -ROOT- —> META这个流程么?
不需要,client端有缓存,第一次查询到相应region所在RS后,这个信息将被缓存到client端,以后每次访问都直接从缓存中获取RS地址即可。
但是如果访问的region在RS上发生了改变,比如被balancer迁移到其他RS上了,这个时候,通过缓存的地址访问会出现异常,在出现异常的情况下,client需要重新走一遍上面的流程来获取新的RS地址。
minor合并和major合并
上文提到storefile最终是存储在hdfs上的,那么storefile就具有只读特性,因此HBase的更新其实是不断追加的操作。
当一个store中的storefile达到一定的阈值后,就会进行一次合并,将对同一个key的修改合并到一起,形成一个大的storefile,当storefile的大小达到一定阈值后,又会对storefile进行split,划分为两个storefile。
由于对表的更新是不断追加的,合并时,需要访问store中全部的storefile和memstore,将它们按row key进行合并,由于storefile和memstore都是经过排序的,并且storefile带有内存中索引,合并的过程还是比较快的。
因为存储文件不可修改,HBase是无法通过移除某个键/值来简单的删除数据,而是对删除的数据做个删除标记,表明该数据已被删除,检索过程中,删除标记掩盖该数据,客户端读取不到该数据。
随着memstore中数据不断刷写到磁盘中,会产生越来越多的hfile小文件,HBase内部通过将多个文件合并成一个较大的文件解决这一小文件问题。
1. minor合并(minor compaction)
将多个小文件(通过参数配置决定是否满足合并的条件)重写为数量较少的大文件,减少存储文件数量(多路归并),因为hfile的每个文件都是经过归类的,所以合并速度很快,主要受磁盘IO性能影响
2. major合并(major compaction)
将一个region中的一个列簇的若干个hfile重写为一个新的hfile。而且major合并能扫描所有的键/值对,顺序重写全部数据,重写过程中会略过做了删除标记的数据(超过版本号限制、超过生存时间TTL、客户端API移除等数据)
region管理
region分配
任何时刻,一个region只能分配给一个RS。
HMaster记录了当前有哪些可用的RS。以及当前哪些region分配给了哪些RS,哪些region还没有分配。当需要分配的新的region,并且有一个RS上有可用空间时,HMaster就给这个RS发送一个加载请求,把region分配给这个RS。RS得到请求后,就开始对此region提供服务。
region server上线
HMaster使用ZK来跟踪RS状态。当某个RS启动时,会首先在ZK上的server目录下建立代表自己的znode。由于HMaster订阅了server目录上的变更消息,当server目录下的文件出现新增或删除操作时,HMaster可以得到来自zookeeper的实时通知。因此一旦RS上线,HMaster能马上得到消息。
region server下线
当RS下线时,它和ZK的会话断开,ZK自动释放代表这台server的文件上的独占锁。HMaster就可以确定RS都无法继续为它的region提供服务了(比如RS和ZK之间的网络断开了或者RS挂了),此时HMaster会删除server目录下代表这台RS的znode数据,并将这台RS的region分配给集群中还活着的RS
HMaster工作机制
HMaster上线
master启动之后会做如下事情:
1. 从ZK上获取唯一一个代表active master的锁,用来阻止其它master成为active master
2. 扫描ZK上的server父节点,获得当前可用的RS列表
3. 和每个RS通信,获得当前已分配的region和RS的对应关系
4. 扫描.META.region的集合,得到当前还未分配的region,将它们放入待分配region列表
从上线过程可以看到,HMaster保存的信息全是可以从系统其它地方收集到或者计算出来的。
HMaster下线
由于HMaster只维护表和region的元数据,而不参与表数据IO的过程,HMaster下线仅导致所有元数据的修改被冻结(无法创建删除表,无法修改表的schema,无法进行region的负载均衡,无法处理region上下线,无法进行region的合并,唯一例外的是region的split可以正常进行,因为只有region server参与),表的数据读写还可以正常进行。因此HMaster下线短时间内对整个HBase集群没有影响。
HBASE容错性
HMaster容错配置
HA,当active master宕机时,通过ZK重新选择一个新的active master。注意:
1. 无HMaster过程中,数据读取仍照常进行
2. 无HMaster过程中,region切分、负载均衡等无法进行
RegionServer容错
定时向ZK汇报心跳,如果一定时间内未出现心跳,比如RS宕机,HMaster将该RS上的region、预写日志重新分配到其他RS上
HBASE数据迁移和备份
1. distcp命令拷贝hdfs文件的方式
使用MapReduce实现文件分发,把文件和目录的列表当做map任务的输入,每个任务完成部分文件的拷贝和传输工作。在目标集群再使用bulkload的方式导入就实现了数据的迁移。
执行完distcp命令后,需要执行hbase hbck -repairHoles修复HBase表元数据。缺点在于需要停写,不然会导致数据不一致,比较适合迁移历史表(数据不会被修改的情况)
2. copytable的方式实现表的迁移和备份
以表级别进行迁移,其本质也是使用MapReduce的方式进行数据的同步,它是利用MapReduce去scan源表数据,然后把scan出来的数据写到目标集群,从而实现数据的迁移和备份。
示例:./bin/hbase
org.apache.hadoop.hbase.mapreduce.CopyTable
-Dhbase.client.scanner.caching=300
-Dmapred.map.tasks.speculative.execution=false
-Dmapreduc.local.map.tasks.maximum=20
--peer.adr=zk_address:/hbase
hbase_table_name
这种方式需要通过scan数据,对于很大的表,如果这个表本身又读写比较频繁的情况下,会对性能造成比较大的影响,并且效率比较低。
copytable常用参数说明(更多参数说明可参考hbase官方文档)
startrow、stoprow:开始行、结束行
starttime:版本号最小值
endtime:版本号最大值,starttime和endtime必须同时制定
peer.adr:目标hbase集群地址,格式:hbase.zk.quorum:hbase.zk.client.port:zk.znode.parent
families:要同步的列族,多个列族用逗号分隔
3. replication的方式实现表的复制
类似MySQL binlog日志的同步方式,HBase通过同步WAL日志中所有变更来实现表的同步,异步同步。
需要在两个集群数据一样的情况下开启复制,默认复制功能是关闭的,配置后需要重启集群,并且如果主集群数据有出现误修改,备集群的数据也会有问题。
4. Export/Import的方式实现表的迁移和备份
和copytable的方式类似,将HBase表的数据转换成Sequence File并dump到hdfs,也涉及scan表数据。
和copytable不同的是,export不是将HBase的数据scan出来直接put到目标集群,而是先转换成文件并同步到目标集群,再通过import的方式导到对应的表中。
示例:
在老集群上执行:./hbaseorg.apache.hadoop.hbase.mapreduce.Export test_tabNamehdfs://ip:port/test
在新集群上执行:./hbaseorg.apache.hadoop.hbase.mapreduce.Import test_tabName
hdfs://ip:port/test
这种方式要求需要在import前在新集群中将表建好。需要scan数据,会对HBase造成负载的影响,效率不高。
5. snapshot的方式实现表的迁移和备份
通过HBase快照的方式实现HBase数据的迁移和拷贝。
示例:
1. 在老集群首先要创建快照:
snapshot 'tabName', 'snapshot_tabName'
2. ./bin/hbase
org.apache.hadoop.hbase.snapshot.ExportSnapshot
-snapshot snapshot_tabName-copy-from hdfs://src-hbase-dir/hbase
-copy-to hdfs://dst-hbase-dir/hbase
-mappers 30
-bandwidth 10
这种方式比较常用,效率高,也是最为推荐的数据迁移方式。
关注微信公众号:大数据学习与分享,获取更对技术干货
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。