
http://hadoop.apache.org/docs/r2.9.0/hadoop-project-dist/hadoop-hdfs/Federation.html
Background
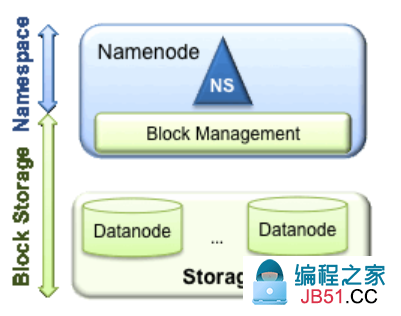
HDFS有两个主要的层:
-
Namespace
- 由目录、文件和块组成
- 它支持所有的文件系统命名空间操作,比如,创建、删除、修改、查看文件或目录
-
Block Storage Service
- Block Management(在NameNode中执行)
- 管理DataNode集群中的成员
- 处理Block报告,并且维护Block的位置
- 支持block相关操作,比如,创建、删除、修改、查看block位置
- 管理副本的位置,block的复制
- Storage
- 由DataNode来提供,存储block到本地文件系统,并提供读写访问
- Block Management(在NameNode中执行)
PS:就像图中画的那样,HDFS主要包括两方面:NameSpace和Block Storage。HDFS中有两种类型的节点,NameNode负责NameSpace和Block Management,而DataNode负责Storage
在先前的HDFS架构中,整个集群只允许有一个namespace,一个NameNode来管理这个namespace。HDFS Federation通过支持多个NameNodes/namespaces来突破这种限制。
Multiple Namenodes/Namespaces
为了水平的扩展name服务,federation采用多个独立的NameNodes/namespaces。NameNodes是独立的,彼此之间不需要联系和协调。DataNodes被用来作为所有NameNodes的公共存储。每一个DataNode会注册到集群中的所有NameNode。DataNode发送周期性的心跳和block报告。它们也处理来自NameNode的命令。
用户可能用ViewFs创建个性化的namespace views。ViewFs和Linux系统中挂载表很类似。
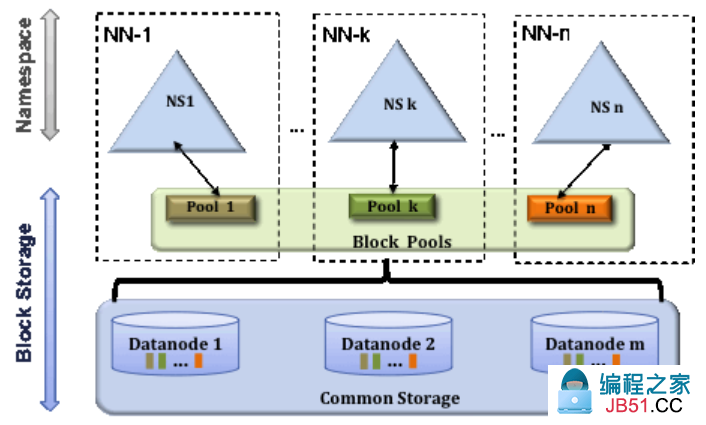
Block Pool
一个Block Pool是属于某个namespace下的一系列block。DataNode存储集群中所有block pool的块。每一个block pool被独立管理。一个namespace为一个新block生产Block ID的时候不需要管其它的namespace。一个NameNode失败不会影响这个DataNode为集群中的其它NameNode提供服务。
一个Namespace和它的block pool一起被叫做“Namespace Volume”。它是一个独立的管理单元。当一个NameNode/namespace被删除的时候,在DataNode中与之相应的block pool也会被删除。在集群升级的时候,每个namespace volume作为一个单元被升级。(PS:block pool是一系列的block,所以当namespace被删除的时候,属于这个namespace的所有block也会被删除)
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。