
浅谈 TensorFlow.js 在前端的工程化应用
Write By CS逍遥剑仙 我的主页: www.csxiaoyao.com GitHub: github.com/csxiaoyaojianxian Email: sunjianfeng@csxiaoyao.com
1. 起步
1.1 当机器学习遇上前端
Google 推出 TensorFlow.js 已有多年,JavaScript 也不知不觉成为了世界上最好的语言。相信对于大多数没接触过机器学习的前端工程师来说,都有一个共同的疑惑:TensorFlow.js 到底能做些什么?
本文不涉及机器学习的算法和原理,仅从一个前端工程师的角度,从 4 个 demo 浅谈 TensorFlow.js 在前端的应用,包括机器学习的模型如何拿来在前端或者说在浏览器中使用、模型的迁移学习以适配业务需求以及 python 模型如何与 js 模型互转优化三部分内容。
本文中的 demo 可以参考 https://github.com/csxiaoyaojianxian/JavaScriptStudy/tree/master/20-tensorflow.js
1.2 什么是 TensorFlow.js
TensorFlow.js 是一个开源的基于硬件加速的JavaScript库,用于训练和部署机器学习模型。对于前端开发者来说,终于可以使用浏览器中愉快地玩耍机器学习了。官方也提供了基于 tensorflow.js 的 playground:http://playground.tensorflow.org/。
1.3 模块安装
1.3.1 两类版本
TensorFlow.js 分两类版本,@tensorflow/tfjs 和 @tensorflow/tfjs-node,前者基于 JavaScript,可以在浏览器中运行,后者底层使用 C++ 编写,在命令行中使用 node 执行。本文的 demo 都是使用 @tensorflow/tfjs,这也是更推荐的方式,因为能够直接在浏览器训练和使用模型,想想就是一件让人兴奋的事情。
1.3.2 browser 版本 (@tensorflow/tfjs)
方式1: 直接在 browser 中运行
浏览器版本直接通过cdn引入script标签。
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@1.0.0/dist/tf.min.js"></script>
<script>
const a = tf.tensor([1, 2]);
a.print();
</script>方式2【推荐】: node 模块化
也可以使用模块化的方式,安装 @tensorflow/tfjs 库并导入,打包构建为 js 脚本引入 html。
$ npm i @tensorflow/tfjs编写 script.js
import * as tf from '@tensorflow/tfjs';
const a = tf.tensor([1, 2]);
a.print();index.html 中引入 build 后的 script.js 并运行
<script src="script.js"></script>1.3.3 nodejs 版本 (@tensorflow/tfjs-node)
底层为c++的版本具有更高的执行效率,可以直接在 node 命令行运行 tensorflow,需要安装 @tensorflow/tfjs-node
$ npm i node-gyp
$ npm i @tensorflow/tfjs-node编写 node.js
const tf = require('@tensorflow/tfjs-node');
const a = tf.tensor([1, 2]);
a.print();执行 node.js
$ node node.js2. 一些绕不开的常见概念
2.1 机器学习的流程
虽然机器学习的算法模型繁多,但其整体流程万变不离其宗,一般来说,tensorflow 中使用神经网络进行学习预测的步骤如下:
- 准备格式化的数据集
- 初始化神经网络模型并设置参数,添加层,设置神经元数量(根据经验预测)、特征数量(根据输入数据)、损失函数、激活函数、优化器等...
- 训练、拟合
- 验证、预测
2.2 tensor (张量)
TensorFlow = tensor + flow,可见,tensor 是深度学习的基础,tensor 中文叫张量,在深度学习里,tensor 实际上就是一个多维数组(multidimensional array),而 tensor 的目的是能够创造更高维度的矩阵、向量。如:数据 1 是一个标量,也是 0 维张量,数据 [1,2,3] 是一个矢量,也是 1维张量,而数据 [[1,2,3],[2,3,4],[3,4,5]] 则是一个矩阵,也是 2 维张量,在矩阵基础上增加一维形成矩阵数组,就是 3 维张量,以此类推。
在 TensorFlow.js 中 tensor 就是一个特殊的多维数组,虽然使用多维数组 + 多重循环的方式也能得到相同的计算结果,但使用 tensor 张量不仅能够使得运算语法更加简洁,而且矩阵运算还能使用GPU加速,提升性能。
2.3 regression (回归) & classification (分类)
回归、分类和聚类是机器学习中最常见的三种数据评估方式,尤其是回归和分类,绝大多数的机器学习都是为了将数据划分为几类并预测目标数据所属的分类(分类),或是根据模型计算出目标数据的值(回归)。
2.4 normalize (归一化)
把数据变成 0 和 1,或者是映射到 0 到 1 之间的小数,便于不同单位或量级的指标能够进行比较和加权。
3. 工程应用 — 基于 MobileNet 模型的图像识别
3.1 在浏览器中使用预训练模型 MobileNet
MobileNet 是由谷歌在 2017 年提出的一款专注于在移动设备和嵌入式设备上的轻量级CNN神经网络,相对于其他的卷积神经网络模型具有轻量、速度快的特性,但准确性一般。
所谓预训练模型,就是已经事先训练好的模型,无需训练即可预测,只需要在 tensorflow.js 中调用web格式的模型文件即可。
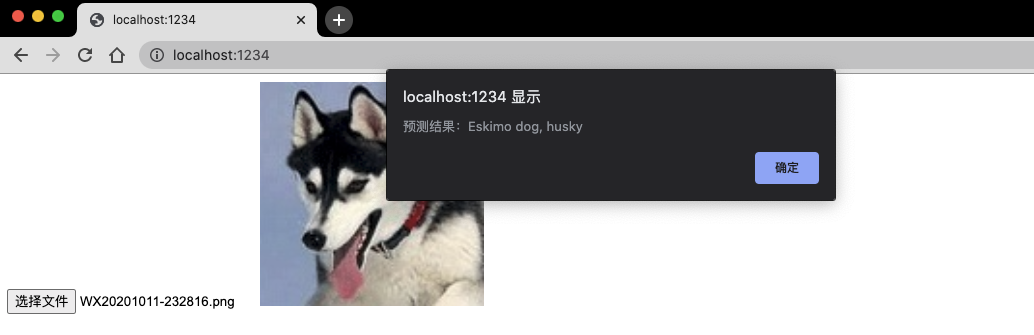
先看最终效果,用户在浏览器中点击上传一张照片,预测程序弹窗提示预测结果。
工程文件结构说明:
web_model
|-- group1-shard1of1.bin # 权重
|-- model.json # 模型
imagenet_classes.js # 映射模型能够识别的1000种类别
script.js # tf调用脚本
index.html # 入口html文件,嵌入打包后的 script.js其中模型文件夹中包含两个模型文件:bin & json,由于预测识别结果为 0 ~ 999,为了更好地展示预测结果,还需要一个映射表来表达预测结果,即 imagenet_classes.js:
export const IMAGENET_CLASSES = {
0: 'tench, Tinca tinca',
1: 'goldfish, Carassius auratus',
...
999: 'toilet tissue, toilet paper, bathroom tissue'
};在 script.js 中使用 tensorflow 调用模型处理预测逻辑:
import * as tf from '@tensorflow/tfjs';
import { IMAGENET_CLASSES } from './imagenet_classes';
...
const MOBILENET_MODEL_PATH = './web_model/model.json'; // 模型地址
window.onload = async () => {
// 加载模型文件
const model = await tf.loadLayersModel(MOBILENET_MODEL_PATH);
window.predict = async (file) => {
// file 转 img
const img = await file2img(file);
document.body.appendChild(img);
// img 转 tf 能处理的数据格式 tensor
const pred = tf.tidy(() => {
const input = tf.browser.fromPixels(img)
.toFloat()
// 归一化到 -1 ~ 1 之间
.sub(255 / 2) // 处理为 -127.5 ~ 127.5
.div(255 / 2) // 处理为 -1 ~ 1
.reshape([1, 224, 224, 3]); // 放到 tensor 数组,1个图片,224 x 224,rgb彩色
return model.predict(input);
});
// 获取预测值的索引
const index = pred.argMax(1).dataSync()[0];
setTimeout(() => { alert(`预测结果:${IMAGENET_CLASSES[index]}`); }, 0);
};
};在 index.html 中嵌入打包后的 script.js 并处理表单调用 predict 预测识别函数:
<script src="script.js"></script>
<input type="file" onchange="predict(this.files[0])">至此,一个机器学习模型就在浏览器中被成功调用并执行了图片识别,如上图所示,程序识别出上传的图片是哈士奇。
3.2 MobileNet 迁移学习 — 手机系统商标识别
前面使用 MobileNet 虽然能够进行图片识别,但往往不能满足现实的业务场景,若从头训练一个模型,由于深度学习模型参数多,不仅复杂,而且成本比较高,比较好的一种方式是把已训练好的模型参数迁移到新的模型来帮助新模型训练。具体讲,可以通过删除原始模型的最后一层,并基于此截断模型的输出训练一个新的(通常相当浅的)模型,这就是迁移学习。
本 demo 将在 mobilenet 基础上进行迁移学习,最后输出 ['android', 'apple', 'windows'] 三选一的商标图片识别结果,并将模型保存下来。
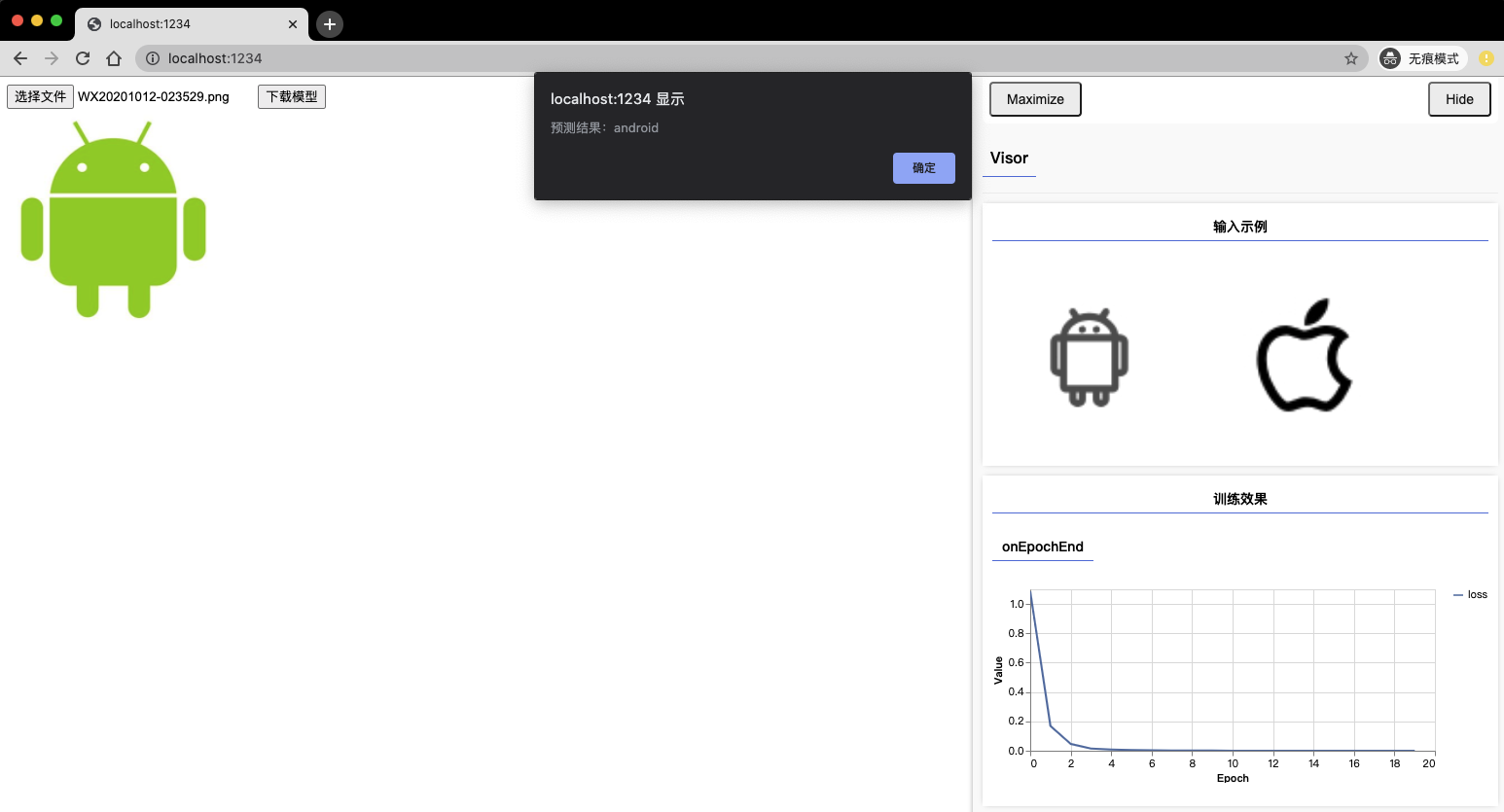
同样先看最终效果,当用户上传一张图片后,程序预测图片的内容为 'android'。
在 script.js 中一步步进行迁移学习并预测:
import * as tf from '@tensorflow/tfjs';
import * as tfvis from '@tensorflow/tfjs-vis';
...
const MOBILENET_MODEL_PATH = './web_model/model.json';
const NUM_CLASSES = 3;
const BRAND_CLASSES = ['android', 'apple', 'windows'];
window.onload = async () => {
...
// 1. 加载 mobilenet 模型(tfjs_layers_model格式)并截断
const mobilenet = await tf.loadLayersModel(MOBILENET_MODEL_PATH);
const layer = mobilenet.getLayer('conv_pw_13_relu'); // 根据层名获取模型中间层并截断
// 2. 生成新的截断模型作为后续模型的输入
const truncatedMobilenet = tf.model({
inputs: mobilenet.inputs,
outputs: layer.output
});
// 3. 构建双层神经网络作为输出,tensor 数据从 mobilenet 模型 flow 到构建的双层神经网络模型
const model = tf.sequential(); // 初始化神经网络模型
model.add(tf.layers.flatten({ // flatten输入
inputShape: layer.outputShape.slice(1) // 特征数量,由输入数据决定
}));
// 添加双层神经网络
model.add(tf.layers.dense({
units: 10, // 神经元数量,由经验决定
activation: 'relu' // 使用 relu 激活函数,使结果支持非线性拟合
}));
model.add(tf.layers.dense({
units: NUM_CLASSES, // 输出类别数量
activation: 'softmax' // 使用 softmax 激活函数,输出概率和为1,一般用于多分类
}));
// 4. 定义损失函数和优化器
model.compile({
loss: 'categoricalCrossentropy', // 交叉熵
optimizer: tf.train.adam() // adam自动调节学习速率,初始化学习速率0.1
});
// 5. 数据预处理: 处理输入为截断模型接受的数据格式,即 mobilenet 接受的格式
const { xs, ys } = tf.tidy(() => {
const xs = tf.concat(inputs.map(imgEl => truncatedMobilenet.predict(img2x(imgEl))));
const ys = tf.tensor(labels);
return { xs, ys };
});
// 5. 通过 fit 方法训练
await model.fit(xs, ys, {
epochs: 20, // 训练次数
callbacks: tfvis.show.fitCallbacks(
{ name: '训练效果' },
['loss'],
{ callbacks: ['onEpochEnd'] }
)
});
// 6. 迁移学习下的模型预测
window.predict = async (file) => {
const img = await file2img(file);
document.body.appendChild(img);
const pred = tf.tidy(() => {
const x = img2x(img); // img 转 tensor
// 截断模型先执行
const input = truncatedMobilenet.predict(x);
// 再用新模型预测出最终结果
return model.predict(input);
});
const index = pred.argMax(1).dataSync()[0];
setTimeout(() => { alert(`预测结果:${BRAND_CLASSES[index]}`); }, 0);
};
};学习完成后,可以把模型下载保存到本地,一共会下载两个文件:json文件 + 权重bin文件。
// 模型的保存 tfjs_layers_model 格式
window.download = async () => {
await model.save('downloads://model');
};至此,mobilenet 模型成功进行了迁移学习,并能够返回一个多分类的手机系统 brand 商标预测结果。
4. 工程应用 — 基于 speech-commands 模型的语音识别
4.1 在浏览器中使用预训练模型 speech-commands
TensorFlow 官方提供了一个语音识别模型 speech-commands,首先需要安装对应的库。
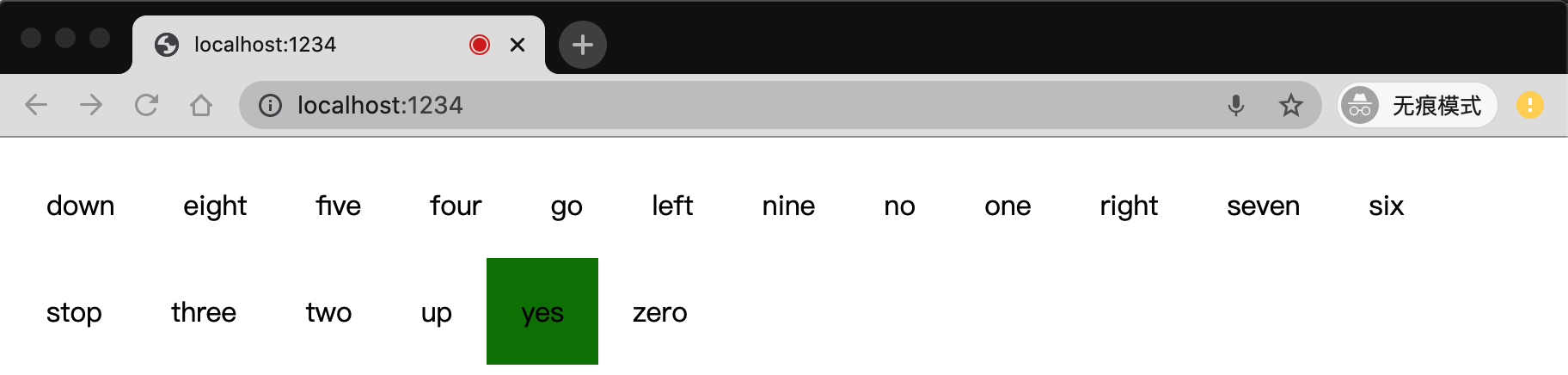
$ npm i @tensorflow-models/speech-commands语音识别的本质依然是分类,仍然先看最终效果,首次打开页面会提示获取麦克风权限,浏览器实时获取麦克风数据,预测程序会根据预测结果对应的单词下添加绿色背景。
工程文件结构说明:
web_model
|-- group1-shard1of2.bin # 权重1
|-- group1-shard2of2.bin # 权重2
|-- metadata.json # 自定义源信息
|-- model.json # 模型
script.js # tf调用脚本
index.html # 入口html文件,嵌入打包后的 script.js在 script.js 中一步步进行迁移学习并预测:
import * as speechCommands from '@tensorflow-models/speech-commands';
const MODEL_PATH = './web_model';
window.onload = async () => {
// 创建识别器
const recognizer = speechCommands.create(
'BROWSER_FFT', // 语音识别需要用到傅立叶变换,此处使用浏览器自带的傅立叶
null, // 识别的单词,null为默认单词
MODEL_PATH + '/model.json', // 模型
MODEL_PATH + '/metadata.json' // 自定义源信息
);
// 确保模型加载
await recognizer.ensureModelLoaded();
// 获取模型能够识别的单词
const labels = recognizer.wordLabels().slice(2); // 去掉前两个无意义的单词
// 绘制交互界面
const resultEl = document.querySelector('#result');
resultEl.innerHTML = labels.map(l => `<div>${l}</div>`).join('');
// 打开设备麦克风监听,可以不用编写 h5 代,语音库已经封装好
recognizer.listen(result => {
const { scores } = result;
const maxValue = Math.max(...scores);
const index = scores.indexOf(maxValue) - 2; // 去掉前两个无意义的单词
resultEl.innerHTML = labels.map((l, i) => `
<div style="background: ${i === index && 'green'}">${l}</div>
`).join('');
}, {
overlapFactor: 0.3, // 识别频率
probabilityThreshold: 0.9 // 识别阈值,超过指定的准确度即执行上面的回调
});
};一个简单的浏览器中运行的语音识别程序就完成了。
4.2 speech-commands 迁移学习 — 中文语音识别并控制幻灯片播放
4.2.1 中文语音训练并生成模型
和 3.2 对于 mobilenet 的迁移学习类似,我们也可以对 speech-commands 迁移学习,以实现中文的语音的训练识别,步骤如下:
- 浏览器中收集中文语音训练数据
- 使用 speech commands 包进行迁移学习并预测
- 语音训练数据的保存和加载
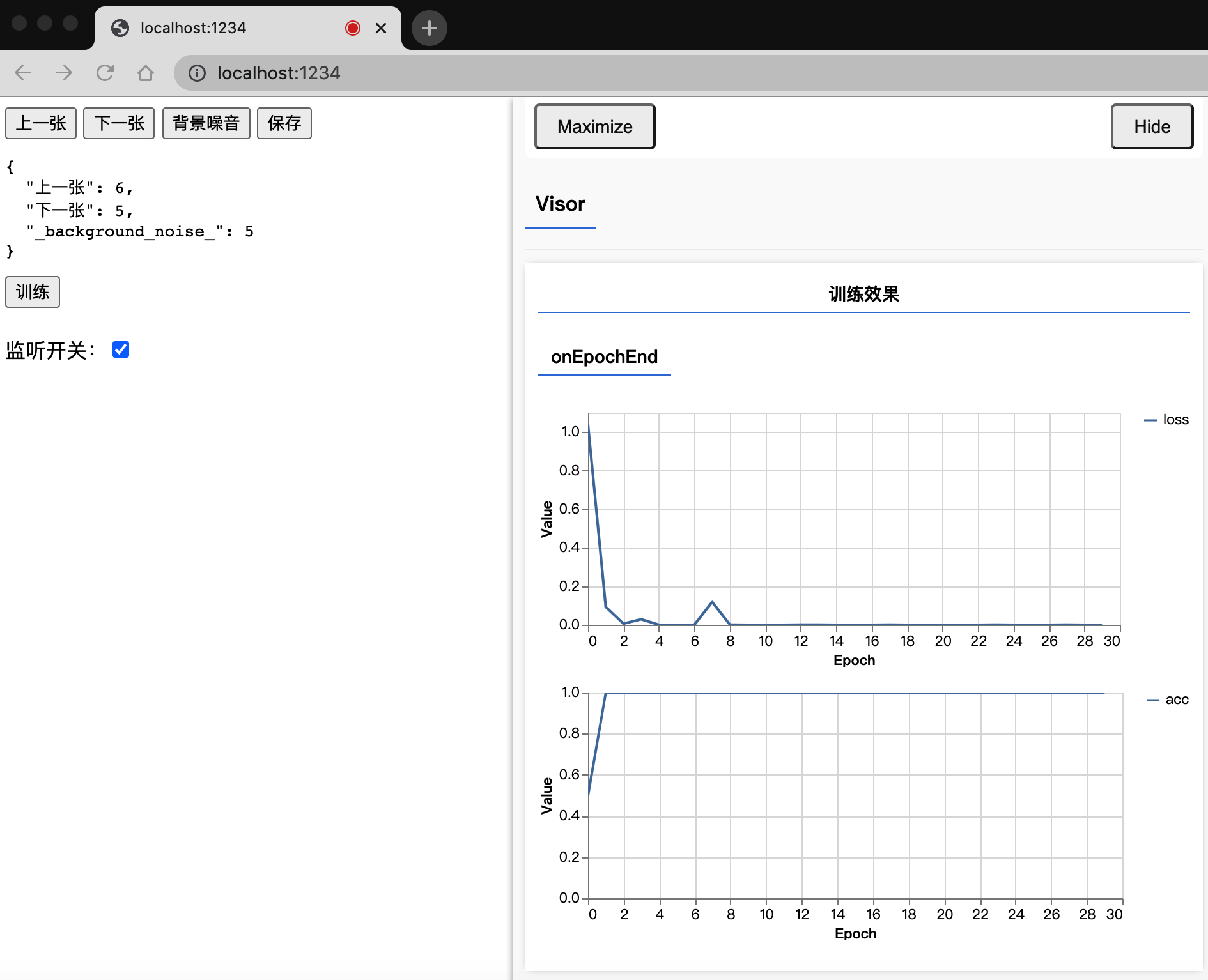
浏览器中的效果如下图,点击按钮采集语音数据,采集一定量的训练数据后执行训练,最后保存模型到本地。
在 script.js 中一步步进行迁移学习并保存模型到本地:
...
window.onload = async () => {
// 创建语音识别器
const recognizer = speechCommands.create(
'BROWSER_FFT',
null,
MODEL_PATH + '/model.json',
MODEL_PATH + '/metadata.json'
);
await recognizer.ensureModelLoaded();
// 迁移学习语音识别器
transferRecognizer = recognizer.createTransfer('轮播图');
};
// 收集语音素材
window.collect = async (btn) => {
btn.disabled = true;
const label = btn.innerText; // 上一张 / 下一张 / 背景噪音
// collect
await transferRecognizer.collectExample(
label === '背景噪音' ? '_background_noise_' : label
);
btn.disabled = false;
// 显示采集的素材数量
document.querySelector('#count').innerHTML = JSON.stringify(transferRecognizer.countExamples(), null, 2);
};
// 执行训练
window.train = async () => {
await transferRecognizer.train({
epochs: 30,
callback: tfvis.show.fitCallbacks(
{ name: '训练效果' },
['loss', 'acc'],
{ callbacks: ['onEpochEnd'] }
)
});
};
// 监听开关
window.toggle = async (checked) => {
if (checked) {
await transferRecognizer.listen(result => {
const { scores } = result;
const labels = transferRecognizer.wordLabels();
const index = scores.indexOf(Math.max(...scores));
}, {
overlapFactor: 0, // 识别频率 0 - 1
probabilityThreshold: 0.75 // 可能性阈值
});
} else {
// 停止监听
transferRecognizer.stopListening();
}
};
// 模型保存
window.save = () => {
// arrayBuffer 为二进制数据
const arrayBuffer = transferRecognizer.serializeExamples();
// 二进制数据转换为 blob
const blob = new Blob([arrayBuffer]);
// 模型文件下载
const link = document.createElement('a');
link.href = window.URL.createObjectURL(blob);
link.download = 'data.bin';
link.click();
};4.2.2 模型应用—使用生成的中文语音模型控制幻灯片播放
在 4.2.1 中生成了训练后的中文语音模型 data.bin,可以轻松地使用模型来控制幻灯片的切换,模型的使用方式与 3.2 节类似。
import * as speechCommands from '@tensorflow-models/speech-commands';
...
window.onload = async () => {
const recognizer = speechCommands.create(
'BROWSER_FFT',
null,
MODEL_PATH + '/speech/model.json',
MODEL_PATH + '/speech/metadata.json',
);
await recognizer.ensureModelLoaded();
// 创建迁移学习器实例
transferRecognizer = recognizer.createTransfer('轮播图');
// fetch data.bin 加载之前录制的训练语音数据
const res = await fetch(MODEL_PATH + '/slider/data.bin');
const arrayBuffer = await res.arrayBuffer();
transferRecognizer.loadExamples(arrayBuffer);
// 训练
await transferRecognizer.train({ epochs: 30 });
};
// 预测监听开关
window.toggle = async (checked) => {
if (checked) {
await transferRecognizer.listen(result => {
const { scores } = result;
const labels = transferRecognizer.wordLabels();
// 得到得分最高的label的索引
const index = scores.indexOf(Math.max(...scores));
window.play(labels[index]);
}, {
overlapFactor: 0,
probabilityThreshold: 0.5
});
} else {
transferRecognizer.stopListening();
}
};
// 播放控制,操作轮播图切换到指定页面
window.play = (label) => {
...
};至此,使用 speech-commands 迁移学习实现中文语音控制幻灯片播放就实现了。
5. 模型转换 & 优化
TensorFlow 模型除了本文中使用的 JavaScript 版模型,在现实工作场景中,更多的模型都是 Python 版模型:
JavaScript版模型:tfjs_layers_model / tfjs_graph_model
Python版模型:Tensorflow Saved Model / Keras HDF5 Model
如果能够使用 python 和 JavaScript 模型转换工具,将能大大扩展 TensorFlow.js 的应用场景。
5.1 安装 Tensorflow.js Converter
# 先 Conda mini 创建 python 虚拟环境
$ conda create -n tfjs python=3.6.8
$ conda active tfjs
$ conda deactive
$ pip install tensorflowjs5.2 Python模型 => JavaScript模型
执行转换 ./mobilenet/keras.h5 从 HDF5 格式转为 tfjs_layers_model / tfjs_graph_model。
$ tensorflowjs_converter --input_format=keras --output_format=tfjs_layers_model ./mobilenet/keras.h5 ./mobilenet/web_model5.3 JavaScript模型 => Python模型
执行转换从 tfjs_layers_model 格式转换为 HDF5 格式。
$ tensorflowjs_converter --input_format=tfjs_layers_model --output_format=keras ./mobilenet/web_model/model.json ./mobilenet/keras.h55.4 JavaScript模型优化 — 分片/量化/加速
- 分片:单位为 byte,本例为100kb
$ tensorflowjs_converter --input_format=tfjs_layers_model --output_format=tfjs_layers_model --weight_shared_size_bytes=100000 ./mobilenet/web_model/model.json ./mobilenet/shared_model/- 量化:压缩减少权重文件
$ tensorflowjs_converter --input_format=tfjs_layers_model --output_format=tfjs_layers_model --quantization_bytes=2 ./mobilenet/web_model/model.json ./mobilenet/quantized_model/- 加速:输出为 graph_model,执行预测更快
$ tensorflowjs_converter --input_format=tfjs_layers_model --output_format=tfjs_graph_model --weight_shared_size_bytes=100000 ./mobilenet/web_model/model.json ./mobilenet/graph_model/6. 总结
本文通过图像识别和语音识别的模型应用与迁移学习共 4 个 demo 浅谈了 TensorFlow 模型在前端的应用,本质上讲,4 个 demo 都是分类问题,而现实业务场景下大部分的需求也往往都是分类问题。
术业有专攻,也许大部分前端工程师目前还难以从头开始训练出能够媲美专业的算法工程师或者人工智能工程师训练出来的高质量的模型,但若能够利用现有的业界成熟的模型,或与算法工程师配合,结合实际业务场景发挥想象,一定能做一些有趣的事情。
7. 相关资料
【 tfvis-api 】https://js.tensorflow.org/api_vis/latest/#render.scatterplot
【 study 】https://developers.google.cn/machine-learning/crash-course/
【 playground 】http://playground.tensorflow.org/
【 speech model 】https://github.com/tensorflow/tfjs-models/tree/master/speech-commands
【 converter 】https://github.com/tensorflow/tfjs/tree/master/tfjs-converter

原文地址:https://cloud.tencent.com/developer/article/1748069
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。