
原文链接:http://blog.csdn.net/qq_38646470/article/details/79427038[1.什么是位图? 2.位图的用处? 3.位图的结构 4.位图题目操练 5.总结(优缺点分析)]
1.什么是位图?
位图就是bitmap的缩写。所谓bitmap,就是用每一位来存放某种状态,适用于大规模数据,但数据状态又不是很多的情况。通常是用来判断某个数据存不存在的。在STL中有一个bitset容器,其实就是位图。
所以我们可以了解到,位图就是一个只用每一位来保存数的状态的结构。
2.位图的用处?
位图主要用于海量数据处理,索引,数据压缩等方面有广泛应用
3.位图的结构
关于位图的结构,类似于哈希,位图就是一个用每一位的0,1来表示一个数的状态。
比如,我们现在有一个文件,这个文件中有数 1,5,4294967295。我们就把第1位,第5位,第4294967295位改为状态1。
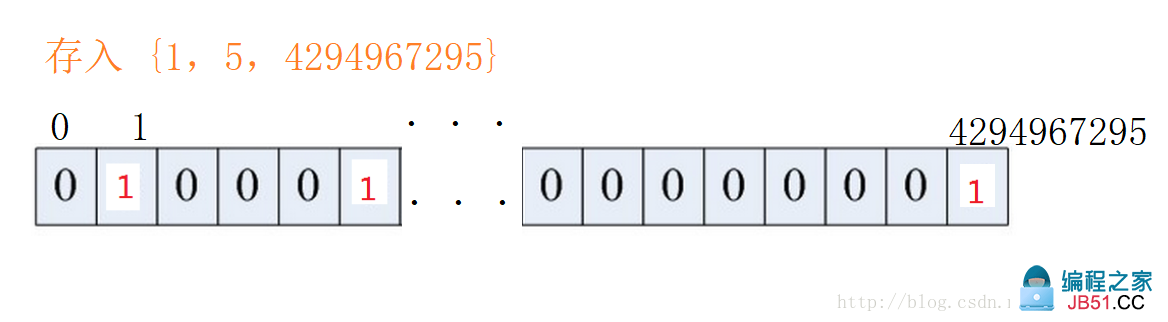
4.位图题目操练
给4 0 亿个不重复的无符号整数,没排过序。给一个无符号整数,如何快速判断一个数是否在这4 0 亿个数中。
题目分析:这是一道关于海量数据查找的题,其实这道题,我们就可以和哈希表联系在一起,为何说是海量数据呢,对于一个40亿整数,我们如果要存的话,按照无符号整数来存储,那么下来,大概就需要40亿*4这么些字节,下来大概就是16G的 内存。
对于现在的64位机,普遍标配内存也就是4-8G的内存,显而易见,16G是没有办法一次性处理的。那么我们如何是好?进行拆分?这样显然也是不好的,怎么拆,还有效率问题。
所以在这里我们采取一种新的思路,这种思路就是位图。
位图结构定义
typedef struct BitMap
{
size_t* _bits;
size_t _range;
}BitMap;
位图相关接口
void BitMapInit(BitMap *bm,size_t range) //初始化
{
assert(bm);
bm->_bits = NULL;
bm->_range = range;
bm->_bits = (size_t *)malloc(sizeof(char)*bm->_range/8);
assert(bm->_bits);
memset(bm->_bits,sizeof(char)*bm->_range/8);
}
void BitMapSet(BitMap *bm,size_t x)//标记相应位
{
size_t num = x>>5;
size_t bit = x%32;
bm->_bits[num] |=(1<<bit);
}
void BitMapReset(BitMap *bm,size_t x)//恢复相应位
{
size_t num = x>>5;
size_t bit = x%32;
bm->_bits[num] &= (~(1<<bit));
}
int BitMapTest(BitMap *bm,size_t x)
{
size_t num = x>>5;
size_t bit = x%32;
if ((1<<bit)&bm->_bits[num])
return 0;
return -1;
}
测试案例及结果截图:
void TestBitMap()
{
BitMap bm;
BitMapInit(&bm,-1);
BitMapSet(&bm,5);
BitMapSet(&bm,6);
BitMapSet(&bm,7);
BitMapSet(&bm,8);
BitMapSet(&bm,-1);
printf("%d\n",BitMapTest(&bm,4));
printf("%d\n",5));
printf("%d\n",6));
printf("%d\n",7));
printf("%d\n",8));
printf("%d\n",-1));
}
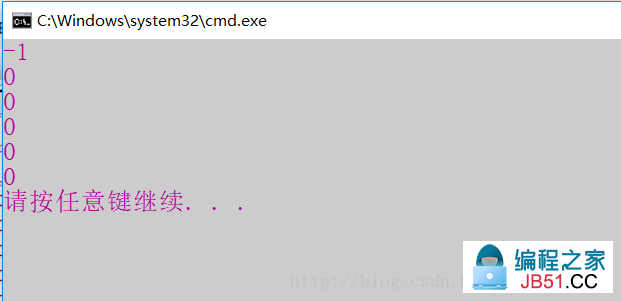
这道题中位图结构代码不难,注意理解思路,必须熟练掌握位运算。
5.总结
优缺点:
(1)可读性差
(2)位图存储的元素个数虽然比一般做法多,但是存储的元素大小受限于存储空间的大小。位图存储性质:存储的元素个数等于元素的最大值。比如, 1K 字节内存,能存储 8K 个值大小上限为 8K 的元素。(元素值上限为 8K ,这个局限性很大!)比如,要存储值为 65535 的数,就必须要 65535/8=8K 字节的内存。要就导致了位图法根本不适合存 unsigned int 类型的数(大约需要 2^32/8=5 亿字节的内存)。
(3)位图对有符号类型数据的存储,需要 2 位来表示一个有符号元素。这会让位图能存储的元素个数,元素值大小上限减半。 比如 8K 字节内存空间存储 short 类型数据只能存 8K*4=32K 个,元素值大小范围为 -32K~32K 。
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。