
什么是单链表
在了解单链表之前,你知道什么是链表吗?如果你不知道什么是链表,可以看看我的这篇博客<链表-LinkList>
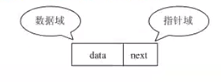
单链表是链表的其中一种基本结构。一个最简单的结点结构如图所示,它是构成单链表的基本结点结构。在结点中数据域用来存储数据元素,指针域用于指向下一个具有相同结构的结点。
因为只有一个指针结点,称为单链表。

单链表中三个概念需要区分清楚:分别是头指针,头节点和首元节点。
头结点、头指针和首元结点(此段转自@ciyeer大牛的博客)
- 头结点:有时,在链表的第一个结点之前会额外增设一个结点,结点的数据域一般不存放数据(有些情况下也可以存放链表的长度等信息),此结点被称为头结点。
若头结点的指针域为空(NULL),表明链表是空表。头结点对于链表来说,不是必须的,在处理某些问题时,给链表添加头结点会使问题变得简单。
首元结点:链表中第一个元素所在的结点,它是头结点后边的第一个结点。
-
头指针:永远指向链表中第一个结点的位置(如果链表有头结点,头指针指向头结点;否则,头指针指向首元结点)。
-
头结点和头指针的区别:头指针是一个指针,头指针指向链表的头结点或者首元结点;头结点是一个实际存在的结点,它包含有数据域和指针域。两者在程序中的直接体现就是:头指针只声明而没有分配存储空间,头结点进行了声明并分配了一个结点的实际物理内存。
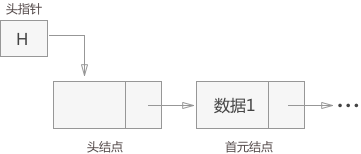
单链表中可以没有头结点,但是不能没有头指针!
头节点的引入能使链表对第一个元素的删除和插入和其他元素相同,不用另外说明,使得代码更加简洁。
单链表的基本操作
单链表的基本操作有:增(add),删(remove),改(set),查(find),插(insert)等。
在这里我们只讲解add,remove,insert三个操作,其他实现看源码。
单链表增添元素
-
声明一个新节点node作为新的尾节点,next=null;
-
获取原链表的最后一个节点,把它的next指向1步骤的新节点node
-
记录链表长度的变量+1
public void add(AnyType a){
Node<AnyType> renode=new Node<>(a,null);
getNode(thesize-1).next=renode;
thesize++;
}
单链表删除元素
-
获取需要删除的节点的上一个节点node
-
把node的next指向node的next的next
-
因为node的next节点没有指针指向它,因此它会被系统自动清理
-
记录链表长度的变量-1
public AnyType remove(int i){
Node<AnyType> prev=getNode(i-1);
AnyType a=prev.next.data;
prev.next=prev.next.next;
thesize--;
return a;
}
单链表插入元素
-
获取需要插入的位置的节点;
-
声明一个新节点node指向1步骤得到的节点;
-
获取需要插入位置节点的上一个节点;
-
将3步骤得到的节点的next指向新节点node;
-
记录链表长度的变量+1。
public void insert(int i,AnyType a){
Node<AnyType> prev=getNode(i-1);
Node<AnyType> renode=new Node<>(a,prev.next);
prev.next=renode;
thesize++;
}
源码实现(java)
/*
结点
*/
public class Node<AnyType> {
public AnyType data;
public Node<AnyType> next;
public Node(AnyType data,Node<AnyType> next){
this.data=data;
this.next=next;
}
}
-----
public class MyLinkList<AnyType> {
//首元节点
private Node<AnyType> first;
//头指针
private Node<AnyType> head;
//链表长度
int thesize;
//初始化链表
public boolean initlist(){
thesize=0;
first=new Node<>(null,null);
head=new Node<>(null,first);
return true;
}
//判断链表是否为空
public boolean isEmpty(){
return thesize==0;
}
//获取节点
public Node<AnyType> getNode(int i){
Node<AnyType> renode=head;
for(int j=-2;j<i;j++){
renode=renode.next;
}
return renode;
}
//在末尾添加元素
public void add(AnyType a){
Node<AnyType> renode=new Node<>(a,null);
getNode(thesize-1).next=renode;
thesize++;
}
//删除i位置节点,并返回删掉的数据
public AnyType remove(int i){
if(i==thesize-1){
AnyType a=getNode(thesize-1).data;
getNode(thesize-2).next=null;
return a;
}
Node<AnyType> prev=getNode(i-1);
AnyType a=prev.next.data;
prev.next=prev.next.next;
thesize--;
return a;
}
//在i位置插入新节点
public void insert(int i,AnyType a){
Node<AnyType> prev=getNode(i-1);
Node<AnyType> renode=new Node<>(a,prev.next);
prev.next=renode;
thesize++;
}
//获取i位置节点的数据
public AnyType get(int i){
return getNode(i).data;
}
//为i位置元素重新赋值
public void set(int i,AnyType a){
getNode(i).data=a;
}
//返回链表节点个数
public int length(){
return thesize;
}
//清空链表
public void clear(){
initlist();
}
//打印链表
public void print(){
for(int i=0;i<thesize;i++){
System.out.println(getNode(i).data);
}
}
}
原文地址:https://www.cnblogs.com/sang-bit
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。