相关推荐
【啊哈!算法】算法3:最常用的排序——快速排序 上一节的冒泡排序可以说是我们学习第一个真正的排序算法,并且解决了桶排序浪费空间的问题,但在算法的执行效率上却牺牲了很多,它的时间复杂度达到了O(N2)。假如我们的计算机每秒钟可以运行10亿次,那么对1亿个数进行排序,桶排序则只需要0.1秒,而冒泡排序则需要1千万秒,达到115天之久,是不是很吓人。那有没有既不浪费空间又可以快一点的排序算法
匿名组 这里可能用到几个不同的分组构造。通过括号内围绕的正则表达式就可以组成第一个构造。正如稍后要介绍的一样,既然也可以命名组,大家就有考虑把这个构造作为匿名组。作为一个实例,请看看下列字符串: “08/14/57 46 02/25/59 45 06/05/85 18 03/12/88 16 09/09/90 13“ 这个字符串就是由生日和年龄组成的。如果需要匹配年两而不要生日,就可以把正则
选择排序:从数组的起始位置处开始,把第一个元素与数组中其他元素进行比较。然后,将最小的元素方式在第0个位置上,接着再从第1个位置开始再次进行排序操作。这种操作一直到除最后一个元素外的每一个元素都作为新循环的起始点操作过后才终止。 public void SelectionSort() { int min, temp;
public struct Pqitem { public int priority; public string name; } class CQueue { private ArrayList pqueue; public CQueue() { pqueue
在编写正则表达式的时候,经常会向要向正则表达式添加数量型数据,诸如”精确匹配两次”或者”匹配一次或多次”。利用数量词就可以把这些数据添加到正则表达式里面了。 数量词(+):这个数量词说明正则表达式应该匹配一个或多个紧紧接其前的字符。 string[] words = new string[] { "bad", "boy", "baad", "baaad" ,"bear", "b
来自:http://blog.csdn.net/morewindows/article/details/6678165/归并排序是建立在归并操作上的一种有效的排序算法。该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。首先考虑下如何将将二个有序数列合并。这个非常简单,只要从比较二个数列的第一个数,谁小就先取谁,取了后就在对应数列中删除这个数。然后再进行比较,如果有数列
插入排序算法有两层循环。外层循环会啄个遍历数组元素,而内存循环则会把外层循环所选择的元素与该元素在数组内的下一个元素进行比较。如果外层循环选择的元素小于内存循环选择的元素,那么瘦元素都想右移动以便为内存循环元素留出位置。 public void InsertionSort() { int inner, temp;
public int binSearch(int value) { int upperBround, lowerBound, mid; upperBround = arr.Length - 1; lowerBound = 0; while (lowerBound <= upper
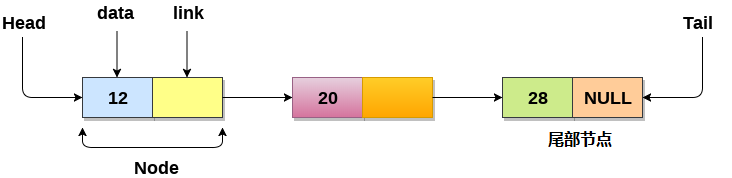
虽然从表内第一个节点到最后一个节点的遍历操作是非常简单的,但是反向遍历链表却不是一件容易的事情。如果为Node类添加一个字段来存储指向前一个节点的连接,那么久会使得这个反向操作过程变得容易许多。当向链表插入节点的时候,为了吧数据复制给新的字段会需要执行更多的操作,但是当腰吧节点从表移除的时候就能看到他的改进效果了。 首先需要修改Node类来为累增加一个额外的链接。为了区别两个连接,这个把指
八、树(Tree)树,顾名思义,长得像一棵树,不过通常我们画成一棵倒过来的树,根在上,叶在下。不说那么多了,图一看就懂:当然了,引入了树之后,就不得不引入树的一些概念,这些概念我照样尽量用图,谁会记那么多文字?树这种结构还可以表示成下面这种方式,可见树用来描述包含关系是很不错的,但这种包含关系不得出现交叉重叠区域,否则就不能用树描述了,看图:面试的时候我们经常被考到的是一种叫“二叉树”的结构,二叉
Queue的实现: 就像Stack类的实现所做的一样,Queue类的实现用ArrayList简直是毋庸置疑的。对于这些数据结构类型而言,由于他们都是动态内置的结构,所以ArrayList是极好的实现选择。当需要往队列中插入数据项时,ArrayList会在表中把每一个保留的数据项向前移动一个元素。 class CQueue { private ArrayLis
来自:http://yingyingol.iteye.com/blog/13348911 快速排序介绍:快速排序是由东尼·霍尔所发展的一种排序算法。在平均状况下,排序 n 个项目要Ο(n log n)次比较。在最坏状况下则需要Ο(n2)次比较,但这种状况并不常见。事实上,快速排序通常明显比其他Ο(n log n) 算法更快,因为它的内部循环(inner loop)可以在大部分的架构上很有效率地
Stack的实现必须采用一种基本结构来保存数据。因为再新数据项进栈的时候不需要担心调整表的大小,所以选择用arrayList.using System;using System.Collections.Generic;using System.Linq;using System.Text;using System.Threading.Tasks;using System.Collecti
数组类测试环境与排序算法using System;using System.Collections.Generic;using System.Linq;using System.Text;using System.Threading.Tasks;namespace Data_structure_and_algorithm{ class CArray { pr
一、构造二叉树 二叉树查找树由节点组成,所以需要有个Node类,这个类类似于链表实现中用到的Node类。首先一起来看看Node类的代码。 public class Node { public int Data; public Node Left; public Node Right; public v
二叉树是一种特殊的树。二叉树的特点是每个结点最多有两个儿子,左边的叫做左儿子,右边的叫做右儿子,或者说每个结点最多有两棵子树。更加严格的递归定义是:二叉树要么为空,要么由根结点、左子树和右子树组成,而左子树和右子树分别是一棵二叉树。 下面这棵树就是一棵二叉树。 二叉树的使用范围最广,一棵多叉树也可以转化为二叉树,因此我们将着重讲解二叉树。二叉树中还有连两种特殊的二叉树叫做满二叉树和
上一节中我们学习了队列,它是一种先进先出的数据结构。还有一种是后进先出的数据结构它叫做栈。栈限定只能在一端进行插入和删除操作。比如说有一个小桶,小桶的直径只能放一个小球,我们现在向小桶内依次放入2号、1号、3号小球。假如你现在需要拿出2号小球,那就必须先将3号小球拿出,再拿出1号小球,最后才能将2号小球拿出来。在刚才取小球的过程中,我们最先放进去的小球最后才能拿出来,而最后放进去的小球却可以最先拿
msdn中的描述如下:(?= 子表达式)(零宽度正预测先行断言。) 仅当子表达式在此位置的右侧匹配时才继续匹配。例如,w+(?=d) 与后跟数字的单词匹配,而不与该数字匹配。此构造不会回溯。(?(零宽度正回顾后发断言。) 仅当子表达式在此位置的左侧匹配时才继续匹配。例如,(?此构造不会回溯。msdn描述的比较清楚,如:w+(?=ing) 可以匹配以ing结尾的单词(匹配结果不包括ing),(
1.引入线索二叉树 二叉树的遍历实质上是对一个非线性结构实现线性化的过程,使每一个节点(除第一个和最后一个外)在这些线性序列中有且仅有一个直接前驱和直接后继。但在二叉链表存储结构中,只能找到一个节点的左、右孩子信息,而不能直接得到节点在任一遍历序列中的前驱和后继信息。这些信息只有在遍历的动态过程中才能得到,因此,引入线索二叉树来保存这些从动态过程中得到的信息。 2.建立线索二叉树 为了保
排序与我们日常生活中息息相关,比如,我们要从电话簿中找到某个联系人首先会按照姓氏排序、买火车票会按照出发时间或者时长排序、买东西会按照销量或者好评度排序、查找文件会按照修改时间排序等等。在计算机程序设计中,排序和查找也是最基本的算法,很多其他的算法都是以排序算法为基础,在一般的数据处理或分析中,通常第一步就是进行排序,比如说二分查找,首先要对数据进行排序。在Donald Knuth 的计算机程序设