

文章目录
其他文章:
萌新不看会后悔的C++基本类型总结(二)
萌新学习C++容易漏掉的知识点,看看你中招了没有(一)
萌新学习C++容易漏掉的知识点看看你中招了没有(二)
C/C++什么时候使用二级指针,你知道吗?
C++类型转换几种情况
C++使用指针,动态数组,指针做参数需要注意的问题等总结
c++的基本类型包括char,short,int,long,lang lang(C++新增的),double,float,bool,其中除了double,folat两种浮点数类型之外都有有符号和无符号两种类型,也就是说一共12种基本类型,至于为什么浮点数没有无符号类型,后面会说。
0.浮点数
浮点数包括float,和double,还有long double,这些书上面都有解释,我们不再赘述,只挑重点讲一讲:
单精度float和双精度double浮点数,那么单精度和双精度有什么区别?
就是前者占4字节,后者占8字节,前者有效数字位数位8位,后者为16位,还有就是取值范围不同。
等等,这显然不是我们想要的答案,比如说我给你举个例子:
float number_1 = 123456789.123456789;
float number_2 = 123456789.123456789f;
double number_3 = 123456789.123456789;
运行结果:
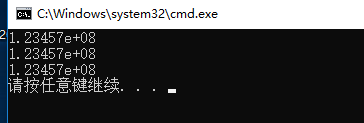
通过这个你能告诉我你就理解单精度和双精度了吗?我相信很多人还是只知道有单精度和双精度这个叫法,却不知道具体意义。
想要知道具体,我们需要查阅 IEEE754标准,该标准定义了float和double,float有32位,double有64位,不管是32位还是64位,它们都由符号位,指数位,和尾数位构成:
| 种类 | 符号位 | 指数位 | 尾数位 |
|---|---|---|---|
| float | 第31位(占1bit) | 第30~23位(占8bit) | 第20~0位(占23bit) |
| double | 第63位(占1bit) | 第62~52位(占11bit) | 第51~0位(占52bit) |
取值范围看指数部分,float指数部分占8位,也就是0 ~ 255,由于有正负,所以为-128 ~ 127,标准规定float偏移量为127,也就是-1-127~255-127为-128到128。
取值范围有-2 ^128到2 ^128,是不是够大?也就是约等于你们熟悉的-3.4E38到+3.4E38。
精度范围看尾数部分,23位所能表示最大的数是2 ^23-1=8388607,也就是说尾数值超过这个值后float将无法精确表示,所以float最多能表示小于8388607的小数点后8位,但绝对能保证为7位,这也是float精度位7 ~ 8位的原因。
同理,double类型的指数位为11位,取值范围有-2 ^10232到2 ^10232,既为你们熟悉的-1.7E+308~1.7E+308。
精度范围为2^52-1=4503599627370495,为16位。所以精度最高位16位,一定可以保证15位,这也double精度位15 ~ 16位的原因。
也是单精度8和双精度16的由来。
1.各种类型占用内存大小问题
下面先来看一段代码。
char c = 'a';
short s = 1;
int i = 1;
long l = 1;
long long ll = 1;
double d = 1.0;
float f = 2.5f;
bool b = 0;
// 在你的机器上面占用多少字节,具体可以使用sizeof运算符得到:
std::cout << sizeof(c);
std::cout << sizeof(s);
std::cout << sizeof(i);
std::cout << sizeof(l);
std::cout << sizeof(ll);
std::cout << sizeof(d);
std::cout << sizeof(f);
std::cout << sizeof(b);
//运行结果为1,2,4,4,8,8,4,1
与所有人一样,一上来我们先了解各个类型占据内存的大小。
这里有一个误区:在不同的编译器,每个类型占用的内存可能是不同的,这和编译器有关,一个类型占用多少字节由编译器在编译期间决定,并不和系统是否是32位和64位有关,不要以为在16位机器上就是16位,在36位机器上就是32位。
可以查看<limits.h> 头文件,int和其他类型的大小是由<limits.h> 中的宏定义来决定的:
INT_MAX
//随便写一个定义的常量,鼠标右击转到声明可以跳到limits.h头文件查看,如下:
所以我这里就不再列出烂大街的最大值,最小值。
我只是告诉你,这个值应该怎么得到。要知其然,还要知其所以然。
比如我们知道char的字节为1,一字节8位可以有256种组合,所以int的字节为4也就是256*256等于65536,这种东西我们理解就好了,没必要背这个最大值,最小值,只需要如何得到就好了。
2.sizeof和strlen的区别
然后说一下sizeof和strlen的区别,可能有很多萌新记不住这两个的区别:sizeof() 是运算符,它不是函数,不要因为它长的像函数,就上它的当,sizeof其值在编译时就已经计算好了,参数可以是数>组,指针,对象,函数等等,它的功能就是获取数组,指针等类型的字节大小。
数组——编译时分配的数组空间大小
指针——存储该指针所用的空间大小
类型——该类型所占空间大小
对象——对象的实际所占空间大小
函数——函数的返回类型所占的空间大小,这里的返回类型自然也不能voidstrlen()是函数,要运行时才能计算,参数必须字符型指针(char*),函数原型为:
Check_return size_t __cdecl strlen(In_z const char * _Str);
该函数的功能是返回字符串的长度,该字符串可能是自己定义的,也可能是内存中随机存储的,该函数实际完成的功能是从代>表该字符串的第一个地址开始遍历,知道遇到结束符NULL,返回的长度不包括NULL。
char * ch = "nihao";
std::cout << strlen(ch);
// 结果为5
3.整形字面值
与C相同,C++也有三种不同的书写方式来书写整数。
1.使用前一位或者两位来标识数字常量的基数,如果第一位是1 ~ 9则表示基数为10,也是十进制写法。
2.如果第一位是0,第二位是1 ~ 7,则基数为8,也就是八进制。
3.如果前两位为0x或者0X则表示基数为16,相当于十六进制。
int number_1 = 66;
int number_2 = 066;
int number_3 = 0x66;
std::cout << number_1 << std::endl;
std::cout << number_2 << std::endl;
std::cout << number_3 << std::endl;
运行结果:
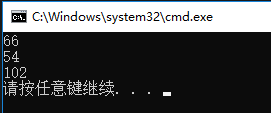
为什么要有这几种书写方式呢,在有些地方是使用八进制或者是十六进制表示,我们可以直接使用该表示方法赋值给number,而不必转换为十进制,总而言之,就是为了方便,为了偷懒,反过来,输入识别进制是有了,反过来,C++也提供了不同进制的输出方式,但C++默认是十进制的输出方式,想要改变默认的十进制输出方式,需要用到cout的一些特殊特性,头文件iostream提供了dec,hex,oct,分别用于表示十进制,十六进制和八进制:
int number_1 = 66;
int number_2 = 066;
int number_3 = 0x66;
std::cout << std::dec;
std::cout << number_1 << std::endl;
std::cout << std::oct;
std::cout << number_2 << std::endl;
std::cout << std::hex;
std::cout << number_3 << std::endl;
运行结果:
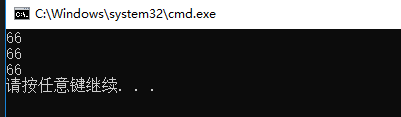
需要注意的是在修改之前,之前修改的格式会一直生效。
4.有无符号类型之间运算情况
说完sizeof和strlen,继续说基本类型的长度,计算机内存的基本单位是位(bit),8位为一个字节,每一位有0和1两种组合,也就是说一个字节有 2 * 2 * 2 * 2 * 2 * 2 * 2 * 2 * 2 = 256 种组合。上面使用sizeof得到char的字节为2字节,也就是说,char类型可以表示 0~ 255 或者 -128 ~ 127 ,上面说过,除了浮点数没有有无符合之分,剩下的类型都有有符合和无符号之分,也就是char支持0~255,也可以支持-128 ~ 127,至于我们需要有符合还是无符号的,决定于我们的应用场景。
执行运算时,如果一个运算数是有符号的,而另一个是无符号的,那么C/C++会隐式的将有符号参数强制转换为无符号类型,并假设这两个数都是非负数。当两种类型进行混合运算时,运算结果为正数时,结果不会出现异常,当运算结果为负数时就会出现异常结果,而且异常的结果往往很大。
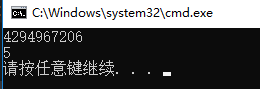
unsigned int usa_1 = 10;
int sa_1 = -100;
unsigned int usa_2 = 10;
int sa_2 = -5;
std::cout <<usa_1+sa_1;
std::cout << usa_2 + sa_2;
运行结果:
5.有无符号类型之间的转换
下面再往深走一点,我们来说说有符合数和无符号数类型之间的转换,也就是二进制01之间的转换,说之前,我们需要先复习一下原码,反码和补码:
原码:
原码就是在最高位符号位用于表示符号,其他位表示值,比如8位一字节:
正1的原码为00000001
负1的原码为10000001
反码:
反码的表示方法为正数的反码时其本身,而负数的反码是在其原码的基础上,符号位不变,其余各数取反:
正1的反码为00000001
负1的反码为11111110
补码:
补码的表示方法为正数的补码就是其本身,而负数的补码就是在其原码的基础上,符号位不变,其余各位取反,最后+1,也就是在反码的基础上+1:
正1的补码000000001
负1的补码111111111
复习了原码反码补码后,我们说:
1.无符号数,不存在正负之分,所有位都用来表示数的本身。
2.有符号数,最高为用来表示数的正负,最高位为1则表示负数,为0则表示为正数。
无符号数想要转换为有符号数需要三步:
1.看无符号数的最高为是否为1。
2.如果不为1,则有符号数就直接等于无符号数。
3.如果无符号数的最高位为1,则将无符号数取补码,得到的数就是有符号数。
举个例子:
无符号数10转换为有符号数
无符号数10的二进制写法:0000 1010
根据三步法得到:
有符号数10的二进制写法:0000 1010
还是10
无符号数129转换为有符号数
无符号数129的二进制写法:1000 0001
根据三步法得到:
反码:1111 1110
补码:1111 1111
也就是说转换成有符号后,代表的是-127
同样,有符号数想要转换为无符号数,同样需要这三步:
1.看有符号数的最高位是否为1,
2.如果不为1(为0),则无符号数就直接等于有符号数;
3.如果有符号数的最高位为1,则将有符号数取补码,得到的数就是无符号数。
举个例子:
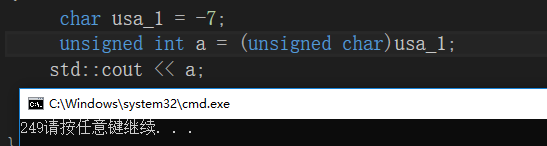
有符号数-7转换为无符号数
有符号数-7的二进制写法:1000 0111
根据三步法得:
反码:1111 1000
补码:1111 1001
也就是无符号数249
总而言之就是看符号位,如果是1,就把它当作负数来处理反码,补码。
6.为什么会出现结果数值异常大
还记得上面有一句话是这样说的当运算结果为负数时就会出现异常结果,而且异常的结果往往很大。现在,我们来处理这个问题:
我们可以把变量的取值范围当作是汽车的里程表,一来为了好理解,而来确实是这样的,拿char来说:

这也就解释了为什么unsigned int usa_1 = 10 和 int sa_1 = -100相加会得到那么大的一个数,也就是常说的最大值加1变为0的故事。
7.为什么浮点数没有分有无符号类型
有无符号类型说完,我们来说说文章开头留下的问题,为什么浮点数没有有无符号之分:
想要使用unsigned,就意味着最高为要用来表示数据,而不是正负,而浮点数定义中规定内存中的数据的第一位必须是符号位,因此两者是矛盾的,至于在哪看定义,请点击下面链接自行查看:
浮点数的定义
还有就是在某些编译器下,会将定义的unsigned folat 和unsigned double自动转换为unsigned int类型,而不报错,这时使用sizeof来测量的话得出来的是int的大小,也就是4.
,
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。