
大家都知道,Apache Hadoop的配置很繁琐,而且很零散,为此Cloudera公司提供了Clouder Manager工具,而且还封装了Apache Hadoop,flume,spark,hive,hbase等大数据产品形成自己特色的CDH产品,再使用CM进行安装,很大程度上方便了集群的搭建,并提供了集群的监控功能。
一、环境:
1.三台VMware虚拟机(一个做为主节点,两个做为从节点)
| hserver1n(主节点) | hserver2n(从节点) | hserver3n(从节点) |
| CM Server | ||
| CM Agent | CM Agent | CM Agent |
| NameNode | DateNode | DateNode |
| Mysql |
2.操作系统:Centos7
3.Cloudera Manager:5.14.1
4.CDH:5.14.0
5.JDK1.8
二、软件下载地址
2.CDH
3.JDK和MySQL自行搜索
三、系统环境设置:
以下步骤都使用root用户操作
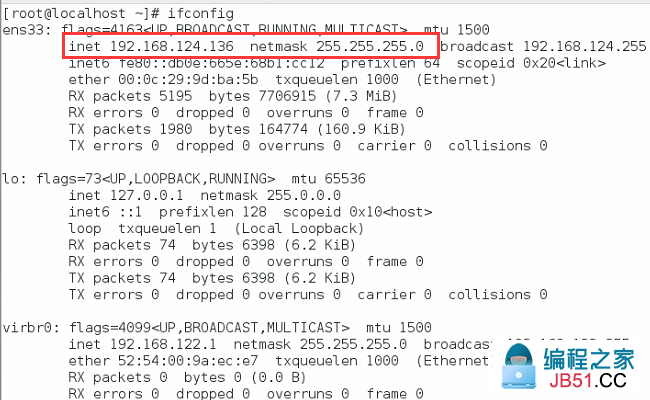
1.设置静态IP
[root@localhost ~]# vim /etc/sysconfig/network-scripts/ifcfg-ens33 TYPE="Ethernet" BOOTPROTO="static" DEFROUTE="yes" PEERDNS="yes" PEERROUTES="yes" IPV4_FAILURE_FATAL="no" IPV6INIT="yes" IPV6_AUTOCONF="yes" IPV6_DEFROUTE="yes" IPV6_PEERDNS="yes" IPV6_PEERROUTES="yes" IPV6_FAILURE_FATAL="no" IPV6_ADDR_GEN_MODE="stable-privacy" NAME="ens33" UUID="edcb54db-f59d-4893-bd8e-8ae60d0ba6f9" DEVICE="ens33" ONBOOT="yes" GATEWAY=192.168.124.2 IPADDR=192.168.124.136 NETMASK=255.255.255.0 DNS1=202.96.128.86 DNS2=223.5.5.5
还需要设置虚拟网络:
(1) 点击虚拟网络编辑器
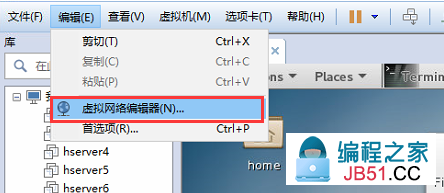
(2)子网,子网掩码,以及NAT设置
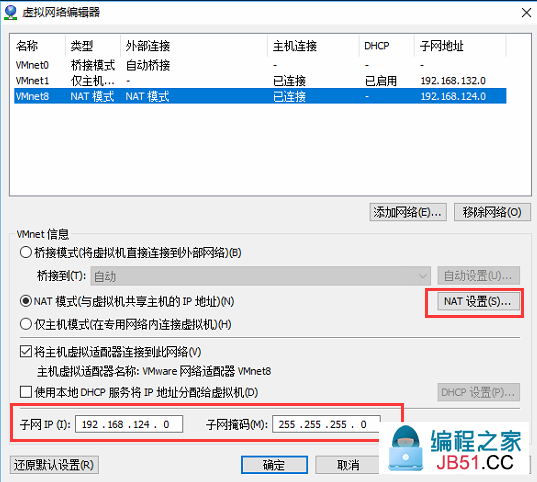
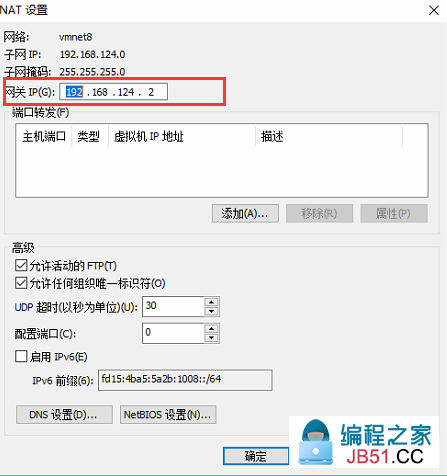
(3)虚拟机网络选择刚设置的VMnet8
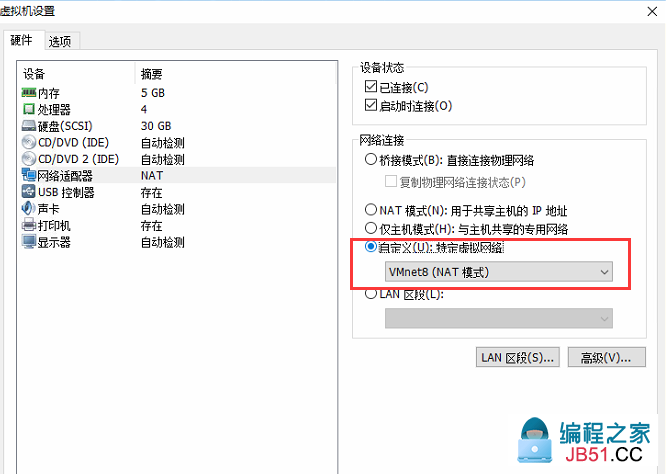
(4)重启网络
[root@localhost ~]# systemctl restart network
2.关闭防火墙和SELINUX

[root@localhost ~]# vim /etc/selinux/config .config/
将selinux=enforcing改成selinux=disabled
重启虚拟机
3.安装JDK
CentOS7默认安装的是OpenJDK,所以需要先卸载,然后安装Oracle JDK.
4.设置主机名(CentOS7与CentOS6主机名设置不同,请参考此博文)
(1)vim /etc/hostname
hserver1n
(2)hostname hserver1n
单台虚拟机设置好后,再复制两台虚拟机,修改HostName、IP、UUID即可。
5.配置三台虚拟机的Host文件
192.168.124.136 hserver1n
192.168.124.137 hserver2n
192.168.124.138 hserver3n
6.打通主节点SSH访问两个从节点
7.配置所有节点NTP时间同步服务
两个从节点同步主节点的时间
四、安装MySQL
- mysql只需在主节点安装
- mysql5.6开始mysql服务启动时会为root用户生成一个临时密码,通过grep 'password' /var/log/mysqld.log命令获取
- 配置密码验证策略,我选择的是不使用密码验证策略,以便创建简单密码
- 配置数据库字符集,我配置默认的字符集是utf8。
五、安装Clouder Manager及CDH
所有节点操作:
1.新建目录
$ sudo mkdir /opt/cloudera-manager
2.将下载的Clouder Manager解压到此目录下
$ sudo tar xzf cloudera-manager*.tar.gz -C /opt/cloudera-manager
3.创建用户cloudera-scm
由于Cloudera Manager和Managed Services默认使用cloudera-scm,所以需要创建此用户
$ sudo useradd --system --home=/opt/cloudera-manager/cm-5.14.1/run/cloudera-scm-server --no-create-home --shell=/bin/false --comment "Cloudera SCM User" cloudera-scm
4.主节点创建Cloudera Manager服务本地数据存储目录
$ sudo mkdir /var/lib/cloudera-scm-server
$ sudo chown cloudera-scm:cloudera-scm /var/lib/cloudera-scm-server
5.配置Agent
配置所有节点的Agent,路径:/opt/cloudera-manager/cm-5.14.1/etc/cloudera-scm-agent/config.ini,将server_host修改成主节点的主机名,如果主节点端口没有自定义,则不用修改。
6.下载mysql-connector-java.jar,并保存到所有主机的/usr/share/java目录下
7.配置mysql,可以参考这里
7.1 mysql安装在主节点上,使用mysql命令登录
7.2 新建一个scm用户,并赋予所有权限,密码是scm
mysql> grant all on *.* to 'scm'@'localhost' identified by 'temp' with grant option;
Query OK,0 rows affected,1 warning (0.00 sec)
7.3 创建数据库scm
7.4 初始化cloudera manager
[root@hserver1n ~]# /opt/cloudera-manager/cm-5.14.1/share/cmf/schema/scm_prepare_database.sh mysql scm scm scm
JAVA_HOME=/usr/java/jdk1.7.0_80
Verifying that we can write to /opt/cloudera-manager/cm-5.14.1/etc/cloudera-scm-server
Creating SCM configuration file in /opt/cloudera-manager/cm-5.14.1/etc/cloudera-scm-server
Executing: /usr/java/jdk1.7.0_80/bin/java -cp /usr/share/java/mysql-connector-java.jar:/usr/share/java/oracle-connector-java.jar:/opt/cloudera-manager/cm-5.14.1/share/cmf/schema/../lib/* com.cloudera.enterprise.dbutil.DbCommandExecutor /opt/cloudera-manager/cm-5.14.1/etc/cloudera-scm-server/db.properties com.cloudera.cmf.db.
Wed Mar 21 14:09:40 CST 2018 WARN: Establishing SSL connection without server's identity verification is not recommended. According to MySQL 5.5.45+,5.6.26+ and 5.7.6+ requirements SSL connection must be established by default if explicit option isn't set. For compliance with existing applications not using SSL the verifyServerCertificate property is set to 'false'. You need either to explicitly disable SSL by setting useSSL=false,or set useSSL=true and provide truststore for server certificate verification.
[ main] DbCommandExecutor INFO Successfully connected to database.
All done,your SCM database is configured correctly!
当看最后一句话,就说明初始化成功了
注意scm账户不能删除,因为cm以后还需要使用此账户,若想创建临时用户,则需要让CM创建用户和数据库,此时可以删除创建的临时用户。
可以使用命令:
/opt/cloudera-manager/cm-5.14.1/share/cmf/schema/scm_prepare_database.sh mysql -utemp -ptemp scm scm scm
8.将CDH安装包移动主节点的/opt/cloudera/parcel-repo目录下
移动的文件有:

将CDH-5.14.0-1.cdh5.14.0.p0.24-el7.parcel.sha1名称改成CDH-5.14.0-1.cdh5.14.0.p0.24-el7.parcel.sha
9.启动主节点的CM Server和所有节点的Agent
路径为:/opt/cloudera-manager/cm-5.14.1/etc/init.d
[root@hserver1n init.d]# ./cloudera-scm-server start
Starting cloudera-scm-server: [ OK ]
[root@hserver1n init.d]# ./cloudera-scm-agent start
Starting cloudera-scm-agent: [ OK ]
10.打开CM管理页面,网址为:http://hserver1n:7180,
用户名和密码都是admin
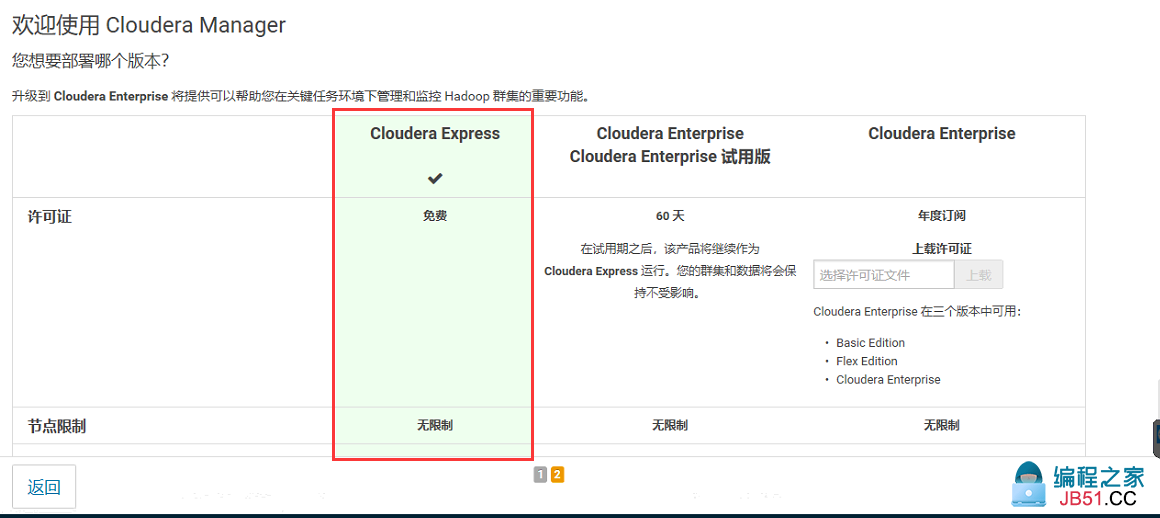
11.选择Cloudera Express
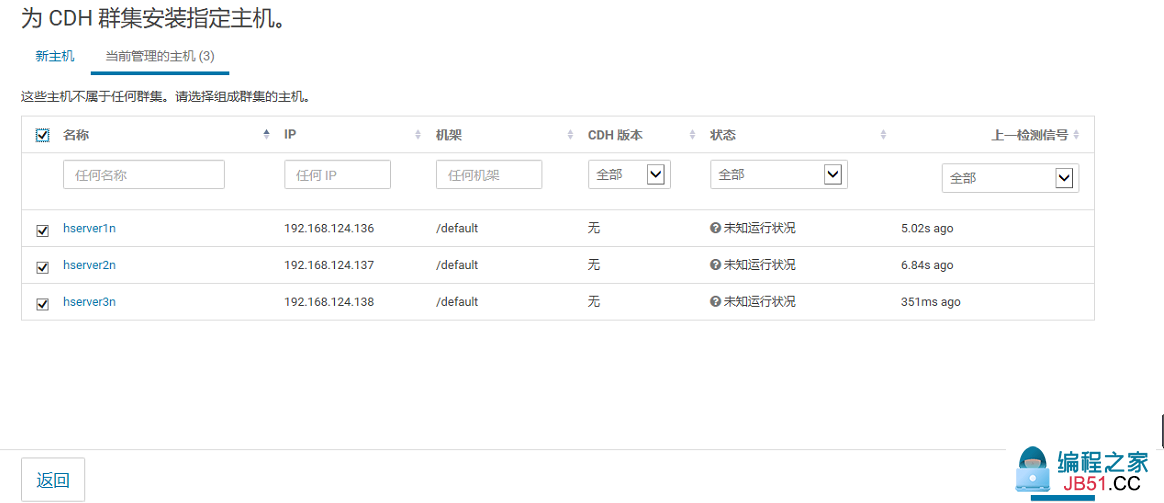
12.选择主机
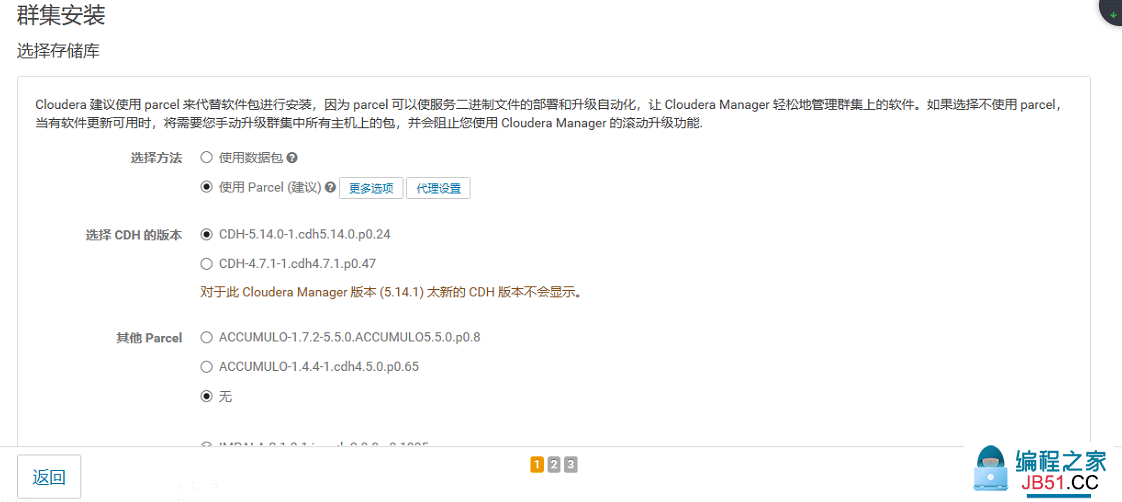
13.群集安装

14.安装完成后,检查主机正确性
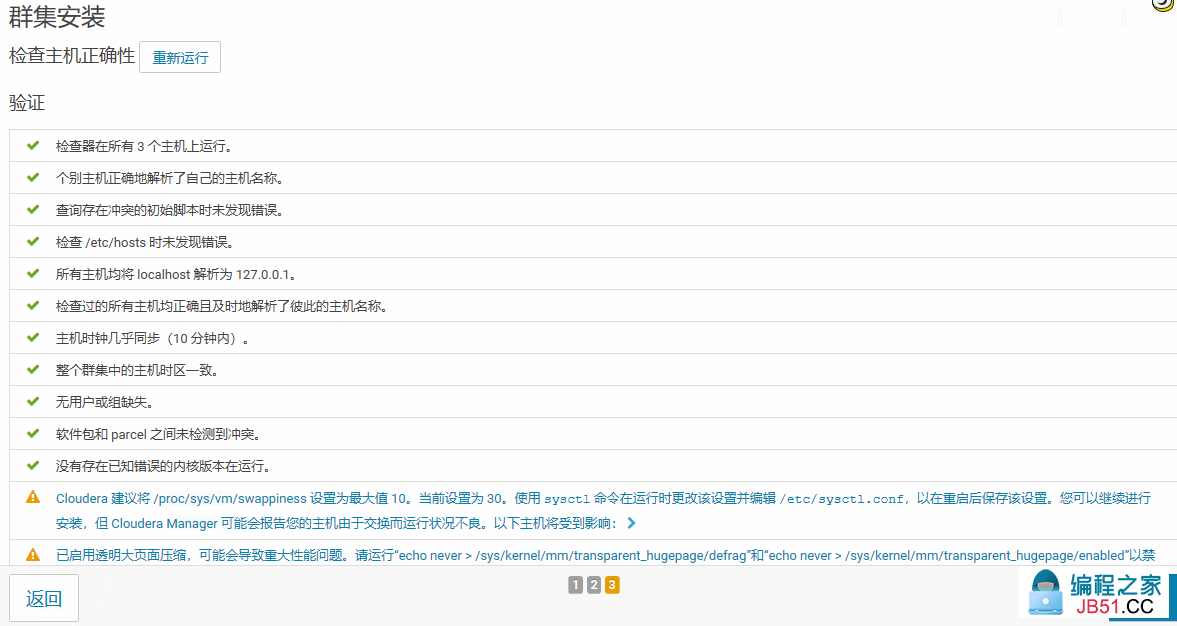
其中有两项需要修改,一个是修改swapping阀值,从30修改成10,已最大限度使用内存,第二项是关闭透明大页面压缩功能,提高性能。
15.选择要安装的服务,这里选择核心Hadoop,以后需要安装其它服务时,再根据需要安装

16.角色分配,尽量让角色均衡地分配到所有主机上,以减少某一台主机的压力
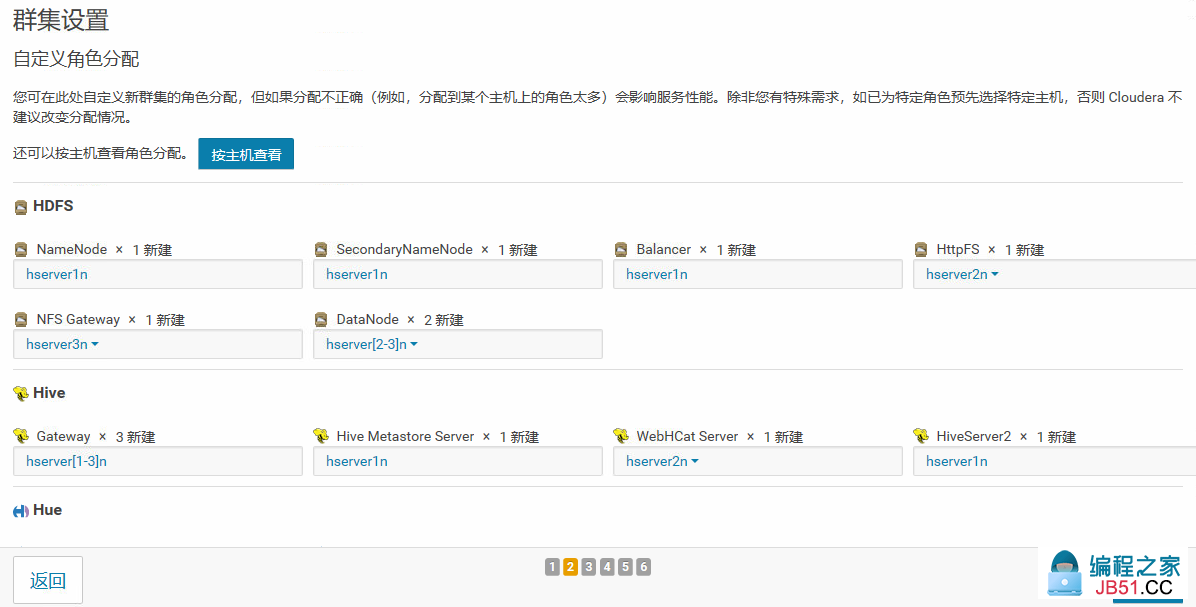
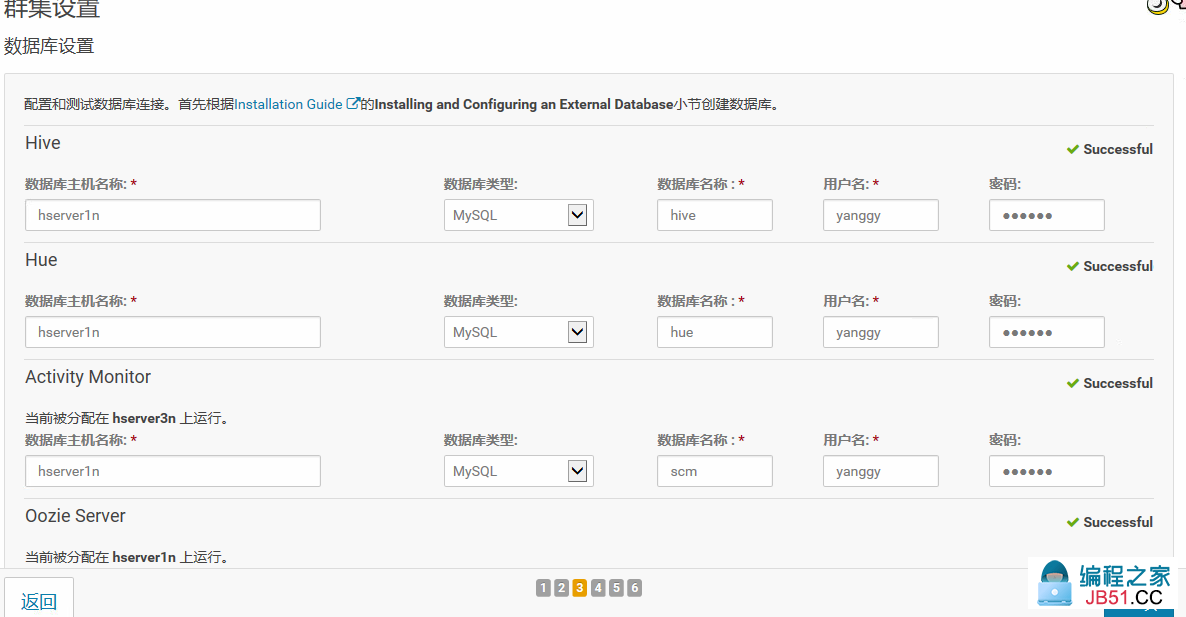
17.创建数据库用户,及相关数据库,并配置服务
mysql> grant all on *.* to 'yanggy'@'%' identified by '878963' with grant option;
Query OK,1 warning (0.03 sec)
mysql> create database hive;
Query OK,1 row affected (0.01 sec)
mysql> create database hue;
Query OK,1 row affected (0.01 sec)
mysql> create database ooz;
Query OK,1 row affected (0.00 sec)
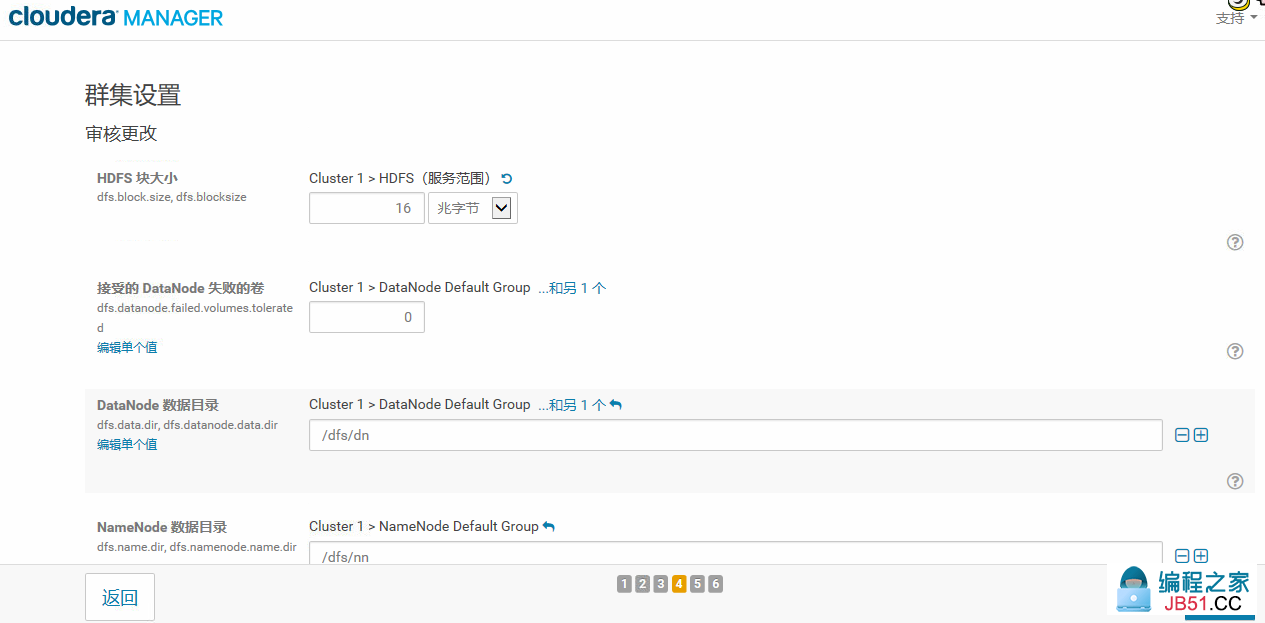
18.集群相关服务的配置
HDFS块大小默认是128M,我这里为测试方便,只配置了16M,其它的配置一些数据目录,日志目录,以及端口
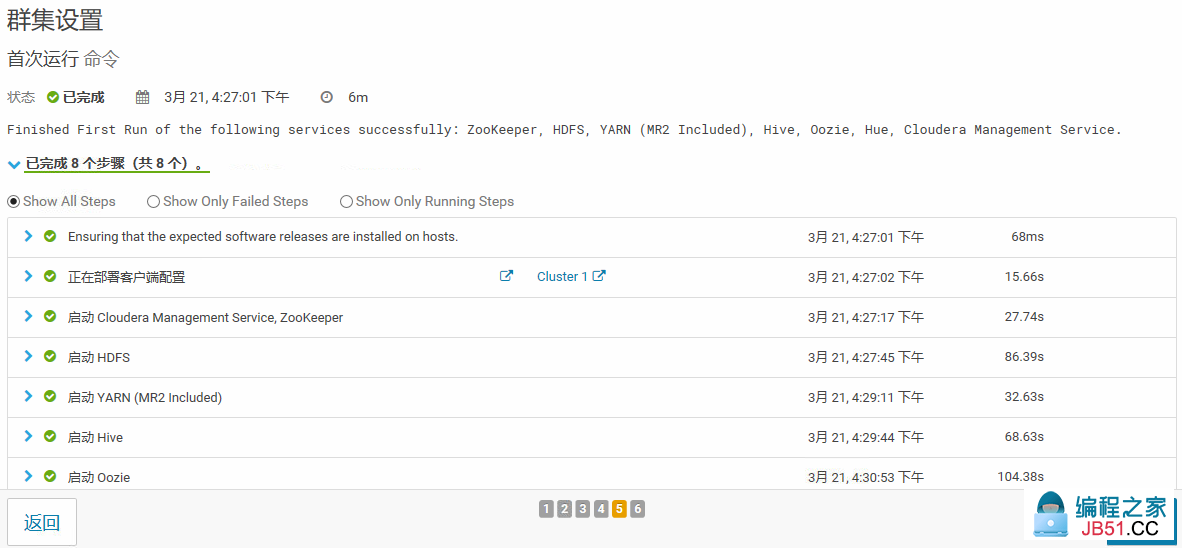
19.集群搭建完成,并启动了相关服务
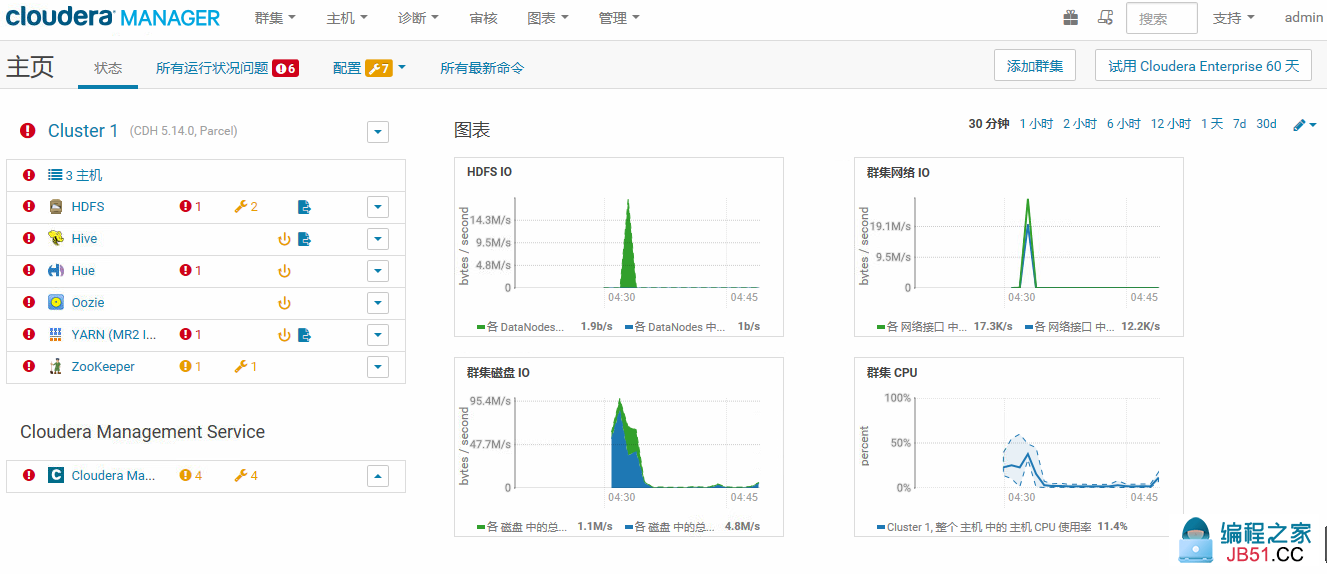
20.集群安装合成后的初始界面,可以很明显的看到集群中安装的服务和运行状况,红叹号是集群中某些配置、空间与CM期望的不一样,可以根据实际情况调整。
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。