
《谷歌布局大数据:开源平台 Apache Beam 正式发布》要点:
本文介绍了谷歌布局大数据:开源平台 Apache Beam 正式发布,希望对您有用。如果有疑问,可以联系我们。

美国时间 1 月 10 日,Apache 软件基金会对外宣布,万众期待的Apache Beam在经历了近一年的孵化之后终于卒业.这一顶级Apache 开源项目终于成熟.
这是大数据处理领域的又一大里程碑变乱——仅仅在上个月,腾讯宣布将在 2017 年一季度开源其大数据计算平台Angel.现在看来,生不逢时的 Angel 可能迎来了它最大的对手.至此,谷歌终于也完成了对其云端大数据平台 Cloud Dataflow 开源的承诺.
Apache Beam 有两大特点:
统一了数据批处置(batch)和流处置(stream)编程范式,
能在任何执行引擎上运转.
它不仅为模型设计、更为执行一系列数据导向的工作流提供了统一的模型.这些工作流包含数据处理、吸收和整合.
它针对什么问题提供了解决方案:
大数据处理领域的一大问题是:开发者经常要用到很多不同的技术、框架、API、开发语言和 SDK.雷锋网获知,取决于需要完成的是什么任务,以及在什么情况下进行,开发者很可能会用 MapReduce 进行批处理,用 Apache Spark SQL 进行交互哀求( interactive queries),用 Apache Flink 实时流处理,还有可能用到基于云端的机器学习框架.
近两年开启的开源大潮,为大数据开发者提供了十分富余的工具.但这同时也增加了开发者选择合适的工具的难度,尤其对于新入行的开发者来说.这很可能拖慢、甚至阻碍开源工具的发展:把各种开源框架、工具、库、平台人工整合到一起所需工作之复杂,是大数据开发者常有的埋怨之一,也是他们支持专有大数据平台的首要原因.
谷歌开源 Cloud Dataflow 背后的算盘是:
Apache Beam 的用户基础越年夜,就会有更多人用谷歌云平台运它.相应地,他们会转化为谷歌云服务的客户.腾讯开放 Angel 的动机与之类似.

背景
2016 年 2 月份,谷歌及其合作伙伴向 Apache 捐赠了一大批代码,创立了孵化中的 Beam 项目( 最初叫 Apache Dataflow).这些代码中的大部分来自于谷歌 Cloud Dataflow SDK——开发者用来写流处理和批处理管道(pipelines)的库,可在任何支持的执行引擎上运行.当时,支持的主要引擎是谷歌 Cloud Dataflow,附带对 Apache Spark 和 开发中的 Apache Flink 支持.如今,它正式开放之时,已经有五个官方支持的引擎.除去已经提到的三个,还包含 Beam 模型和 Apache Apex.
雷锋网获知,Apache Beam 的官方解释是:“Beam 为创建复杂数据平行处理管道,提供了一个可移动(兼容性好)的 API 层.这层 API 的核心概念基于 Beam 模型(以前被称为 Dataflow 模型),并在每个 Beam 引擎上分歧程度得执行.”
谷歌工程师、Apache Beam 项目的核心人物 Tyler Akidau 表现:
“当我们(谷歌和几家公司)决定把 Cloud Dataflow SDK 和相关引擎参加 Apache Beam 孵化器项目时,我们脑海里有一个目标:为世界提供一个易于使用、但是很强大的数据并行处理模型,支持流处理和批处理,兼容多个运行平台.”

前景
对付 Apache Beam 的前景,Tyler Akidau 说道:
“一般来讲,在孵化器卒业只是一个开源项目生命周期中的一个里程碑——未来还有很多在等着我们.但成为顶级项目是一个信号:Apache Beam 的背后已经有为迎接它的黄金时间准备就绪的开发者社群.
这意味着,我们已经准备好向前推进流处理和批处理的技术界限,并把可移动性(兼容多平台)带到可编程数据处理. 这很像 SQL 在陈述性数据(declarative data)分析领域起到的作用.相比不开源、把相关技术禁锢在谷歌高墙之内,我们希望借此创造出前者所无法实现的东西.”
另外,Tyler Akidau 信心十足地强调:“流处置和批处置的未来在于 Apache Beam,而执行引擎的选择权在于用户.”
最后,我们来看看谷歌在去年早些时候发布的 “Apache Beam 技能矩阵”,用它可以看出每一个兼容引擎执行 Beam 模型的效果.换句话说,它展示了 Apache Beam 管道在分歧平台执行的兼容能力.
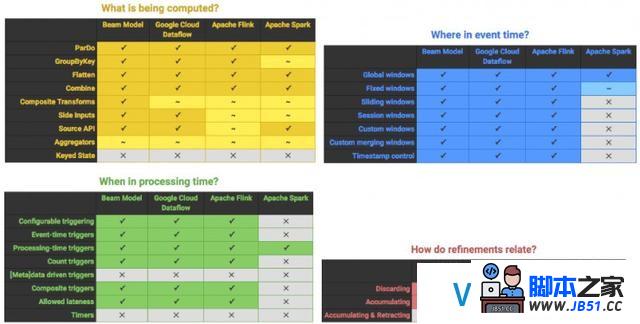
黄色表:都有什么被计算?蓝表:变乱时间的那一刻?绿表:处理时间的哪一刻?红表:各项改进之间有什么关系?
via 谷歌blog,GCP,datanami雷锋网
欢迎参与《谷歌布局大数据:开源平台 Apache Beam 正式发布》讨论,分享您的想法,编程之家PHP学院为您提供专业教程。
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。